

intro: 对于布尔类型字段的处理,Elasticsearch 曾犯了一个错,直到数年后 发布6.0版本才修正过来,这个设计或多或少会遇到,只是没留意,但是查询的时候结果还是让人困惑的。
问题或现象
前几天刚到公司,同事抛出一个问题,就是发现前一天某个搜索查询条件没有结果,但是第二天却出来结果,不过这个出来的结果是不对的,即搜索result=90时,出现了result=91的结果。
于是给我发了链接,我点过去就是下图这样子: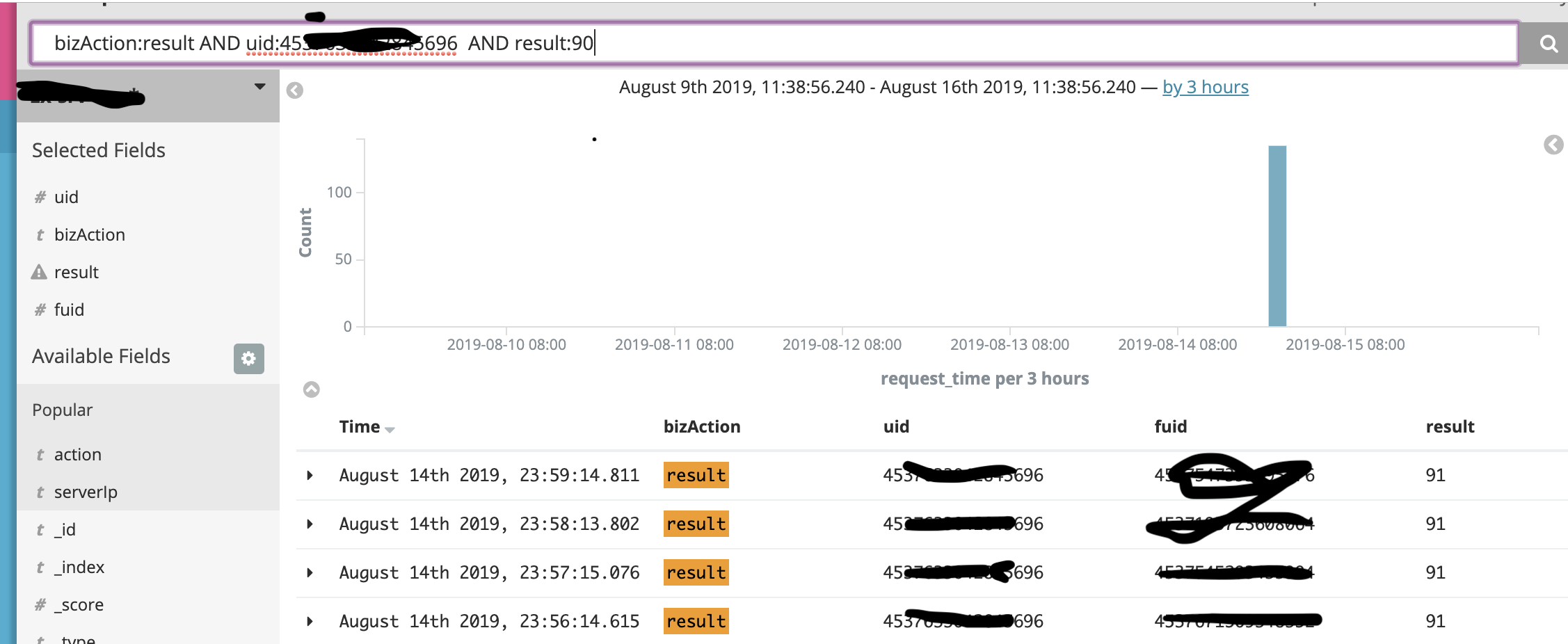
由于忙于其他问题,所以随口回复了让他使用
result.keyword=90 查询,显然满足条件了。不过一会儿对方又问了个问题“这个字段和其他有什么特殊吗,为什么就要用keyword”,我想了想,的确是个问题,这类索引没有使用特别的分词也没有用特制的打分策略,确实不应该匹配的。
但是为什么呢?
为什么
好在Elasticsearch(以下可能简称es)提供了一些辅查询相关的助接口,如分词有疑问可使用_analyze理解,打分有疑问可使用_explain, 应早在1.7版本前已经存在了,虽然es的版本有段时间跳跃。
当我们无法理解一个document为什么会被匹配时,就可以试试用explain查询那条记录,看看es为何会匹配,于是有下面结果(我简化了下查询):
[java@xx~]$ curl -s '10.135.20.38:9200/aa-2019.08.14/result/AWyQ2s_MQk_27Wzfh6IY/_explain?pretty&q=uid:4537633042845696%20%20AND%20result:90'
{
"_index" : "aa-2019.08.14",
"_type" : "result",
"_id" : "AWyQ2s_MQk_27Wzfh6IY",
"matched" : true,
"explanation" : {
"value" : 1.0068661,
"description" : "sum of:",
"details" : [
{
"value" : 1.0068661,
"description" : "sum of:",
"details" : [
{
"value" : 1.0,
"description" : "uid:[4537633042845696 TO 4537633042845696], product of:",
"details" : [
{
"value" : 1.0,
"description" : "boost",
"details" : [ ]
},
{
"value" : 1.0,
"description" : "queryNorm",
"details" : [ ]
}
]
},
{
"value" : 0.006866124,
"description" : "weight(result:T in 59188) [PerFieldSimilarity], result of:",
"details" : [
{
"value" : 0.006866124,
"description" : "score(doc=59188,freq=1.0 = termFreq=1.0\n), product of:",
"details" : [
{
"value" : 0.006866124,
"description" : "idf, computed as log(1 + (docCount - docFreq + 0.5) / (docFreq + 0.5)) from:",
"details" : [
{
"value" : 1.7270076E7,
"description" : "docFreq",
"details" : [ ]
},
{
"value" : 1.738906E7,
"description" : "docCount",
"details" : [ ]
}
]
},
{
"value" : 1.0,
"description" : "tfNorm, computed as (freq * (k1 + 1)) / (freq + k1) from:",
"details" : [
{
"value" : 1.0,
"description" : "termFreq=1.0",
"details" : [ ]
},
{
"value" : 1.2,
"description" : "parameter k1",
"details" : [ ]
},
{
"value" : 0.0,
"description" : "parameter b (norms omitted for field)",
"details" : [ ]
}
]
}
]
}
]
}
]
},
{
"value" : 0.0,
"description" : "match on required clause, product of:",
"details" : [
{
"value" : 0.0,
"description" : "# clause",
"details" : [ ]
},
{
"value" : 1.0,
"description" : "_type:result, product of:",
"details" : [
{
"value" : 1.0,
"description" : "boost",
"details" : [ ]
},
{
"value" : 1.0,
"description" : "queryNorm",
"details" : [ ]
}
]
}
]
}
]
}
}我们期待的得分是0,即应该有一条是不满足的条件,但上述结果返回的还是得分1.0068661,匹配了,explain接口值得后面再写文章讨论下,这里不展开,如果这里你看不出什么,可以试试下面。
可以再查询下 昨日今日,即aa-2019.08.13/14的mapping配置,于是我得到了这样的结果
# 2019.08.13
"result" : {
"type" : "boolean"
},
# 2019.08.14
"result" : {
"type" : "text",
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
}
},系统的索引是一天创建一个当天日期后缀的索引,没有特别对字段的mapping配置。
那么结论也就出来了,08.13那天的索引里,result类型是boolean,所以当查询条件 result为90或91的时候,他们都是都会被解析为true,也就是匹配索引里的boolean类型的字段的那条记录,所以搜索 result=90时,result=91也就出现在结果里了。
How
解决方法不难,有几种。
先看根原因,由于写es会根据字段 biz=A 聚合到同一索引下,多个服务又会共用 biz=A 的属性,并且由于他们可能使用了同名的字段 act,但是(act在各个服务里的)类型是不同的,比如上文result 有的是boolean,有的是String类型,所以每天凌晨第一条数据(先发出事件的服务)决定该字段在当天该索引的类型了。
所以,根本的办法是要求各应用规范统一。
但也可以在这里修改es不修改服务,统一设置该类索引的mapping,强制将该字段弱化为
string 类型,这样实现elasticsearch层面的统一。
More
我好奇的是,这是es的bug吗?
于是尝试下载最新版的Elasticsearch,发现该问题已经不存在的了
➜ elasticsearch-7.2.1 curl -XPOST -H"Content-Type:application/json" 'http://127.0.0.1:9200/people/doc/1' -d'{"name":"hello","man":false}'
{"_index":"people","_type":"doc","_id":"1","_version":1,"result":"created","_shards":{"total":2,"successful":1,"failed":0},"_seq_no":0,"_primary_term":1}
➜ elasticsearch-7.2.1 curl -XPOST -H"Content-Type:application/json" 'http://127.0.0.1:9200/people/doc/2' -d'{"name":"hello","man":93}'
{"error":{"root_cause":[{"type":"mapper_parsing_exception","reason":"failed to parse field [man] of type [boolean] in document with id '2'"}],"type":"mapper_parsing_exception","reason":"failed to parse field [man] of type [boolean] in document with id '2'","caused_by":{"type":"json_parse_exception","reason":"Current token (VALUE_NUMBER_INT) not of boolean type\n at [Source: org.elasticsearch.common.bytes.BytesReference$MarkSupportingStreamInputWrapper@4bc234e3; line: 1, column: 25]"}},"status":400}这里报了个json解析异常,这看起来有点有趣。
我们知道elasticsearch底层其实也用到Jackson的jsonparser去解析json类型内容的,于是我看了下7.2.1的Jackson-core这个jar包,确实升级了个版本。
那么这个bug是谁解决的呢?是Elasticsearch团队解决的,还是他们不经意间升级Jackson组件解决的?
后者有趣,是软件开发里的信任链问题了。
如果对Jackson了解的话,或许已经有答案了,不过我还是希望可以通过搜索到相关主题,更快速些。
遗憾的是通过elasticsearch/boolean/BooleanFieldMapper/number等关键字N种组合尝试都没有找到相关主题。
于是我猜测了几个可能的改动文件,就先从 BooleanFieldMapper.java 开始,从github的历史版本里查找,至少二分法查找能找到在哪个版本里有git变更吧。(需要说明的是elasticsearch源码比较能折腾,7.0后代码组织结构大变更,从之前的core分到server目录,module变更等)。巧合的是打开6.0版本就发现BooleanFieldMapper.java的历史变更记录里有一个主题关于 strict boolean ,点开发现和我的问题很相似。
看了下,虽然主题下帖子较多,但是互动人数不多,看评论似乎还未意识到这是个很明显的“看起来合理”的错误,而不是喜好问题。
More
该PR涉及几个改动,这里列下和本文问题最相关的改动点(以下讨论时基于JsonXContentParser):
1)es的解析原理中,对于document的解析是在org.elasticsearch.index.mapper.DocumentParser里通过 parseObjectOrField 方法完成对各个字段的解析的(index/store是后续逻辑了,无关本文)。
2)parseObjectOrField将解析代理给 org.elasticsearch.index.mapper.FieldMapper,
由于我们已经知道该字段是boolean类型的,所以就是通过 BooleanFieldMapper 解析的,对应的入口就是在org.elasticsearch.index.mapper.BooleanFieldMapper.parseCreateField 方法内处理field的。
3)5.2.2和 7.2.1 在处理boolean类型field的区别就是下面代码所示:
Elasticsearch 5.2.2 的部分代码
// boolean org.elasticsearch.common.xcontent.support.AbstractXContentParser.booleanValue() throws IOException
@Override
public boolean booleanValue() throws IOException {
Token token = currentToken();
if (token == Token.VALUE_NUMBER) {
return intValue() != 0;
} else if (token == Token.VALUE_STRING) {
return Booleans.parseBoolean(textCharacters(), textOffset(), textLength(), false /* irrelevant */);
}
return doBooleanValue();
}
//boolean org.elasticsearch.common.Booleans.parseBoolean(char[] text, int offset, int length, boolean defaultValue)
/**
* Returns <code>false</code> if text is in <tt>false</tt>, <tt>0</tt>, <tt>off</tt>, <tt>no</tt>; else, true
*/
public static boolean parseBoolean(char[] text, int offset, int length, boolean defaultValue) {
// TODO: the leniency here is very dangerous: a simple typo will be misinterpreted and the user won't know.
// We should remove it and cutover to https://github.com/rmuir/booleanparser
if (text == null || length == 0) {
return defaultValue;
}
if (length == 1) {
return text[offset] != '0';
}
if (length == 2) {
return !(text[offset] == 'n' && text[offset + 1] == 'o');
}
if (length == 3) {
return !(text[offset] == 'o' && text[offset + 1] == 'f' && text[offset + 2] == 'f');
}
if (length == 5) {
return !(text[offset] == 'f' && text[offset + 1] == 'a' && text[offset + 2] == 'l' && text[offset + 3] == 's' && text[offset + 4] == 'e');
}
return true;
}Elasticsearch 7.2.1 的部分代码
// boolean org.elasticsearch.common.xcontent.support.AbstractXContentParser.booleanValue() throws IOException
@Override
public boolean booleanValue() throws IOException {
Token token = currentToken();
if (token == Token.VALUE_STRING) {
return Booleans.parseBoolean(textCharacters(), textOffset(), textLength(), false /* irrelevant */);
}
return doBooleanValue();
}
//boolean org.elasticsearch.common.Booleans.parseBoolean(char[] text, int offset, int length, boolean defaultValue)
/**
* Parses a char[] representation of a boolean value to <code>boolean</code>.
*
* @return <code>true</code> iff the sequence of chars is "true", <code>false</code> iff the sequence of chars is "false" or the
* provided default value iff either text is <code>null</code> or length == 0.
* @throws IllegalArgumentException if the string cannot be parsed to boolean.
*/
public static boolean parseBoolean(char[] text, int offset, int length, boolean defaultValue) {
if (text == null || length == 0) {
return defaultValue;
} else {
return parseBoolean(new String(text, offset, length));
}
}
...
/**
* Parses a string representation of a boolean value to <code>boolean</code>.
*
* @return <code>true</code> iff the provided value is "true". <code>false</code> iff the provided value is "false".
* @throws IllegalArgumentException if the string cannot be parsed to boolean.
*/
public static boolean parseBoolean(String value) {
if (isFalse(value)) {
return false;
}
if (isTrue(value)) {
return true;
}
throw new IllegalArgumentException("Failed to parse value [" + value + "] as only [true] or [false] are allowed.");
}区别在于 7.2.1中对boolean的解析去掉了 token == Token.VALUE_NUMBER 部分的逻辑(同时对0/1作为布尔类型也不再支持了),而是先判断 VALUE_STRING 这种情况,通过 parseBoolean 处理, 即仅支持“true/false/null”,其他任何都是报 IllegalArgumentException(包括不支持on/off/True/False/yes/no) ,此外的就交给 doBooleanValue 处理了,即通过Jackson的 JsonParser.getBooleanValue处理。这里其实只是对Jackson有些依赖的。
需要指出是对于True/False是另外一处代码,但最终和 JsonParser.getBooleanValue 类似。
