

最近在内部技术分享会上发现大家对Bert实践中的问题比较感兴趣,疑问点主要集中在,Bert机器资源代价昂贵,如何用较小成本(金钱和时间)把Bert跑起来?因此,希望这篇文章能帮助你在实践Bert的过程中少走一些弯路。
整个文章结构分成四部分。
第一部分Bert代码速读,提示Bert代码中容易忽略的关键点,目的是让你快速的熟悉代码并且跑起来
第二部分总结下我在服务化部署Bert中趟过的一些坑
第三部分参考资料(同样有干货)
第四部分总结性能和效果,给出实践Bert最低成本路径。
- 一、Bert代码速读
这一部分代码来源是google research 在github上发布的官网链接:google-research/bert讲讲代码中容易忽略但是很重要的点,帮助你在较短时间内实践Bert,所要掌握的必要代码。解析Google research官方发布的Bert源码(给出连接)的主要结构,重点讲run_classifier.py,run_squad.py,modeling.py中模型构建的核心代码。
1.Bert代码结构
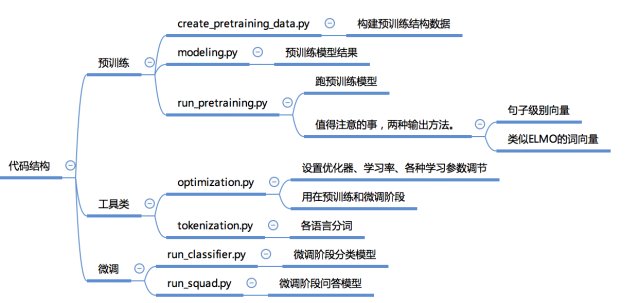
2.两个微调模型run_classifier.py和run_squad.py的create _model 部分核心代码。


3.预训练模型层modeling.py 中的attention_layer代码,包含原理图和代码解析。
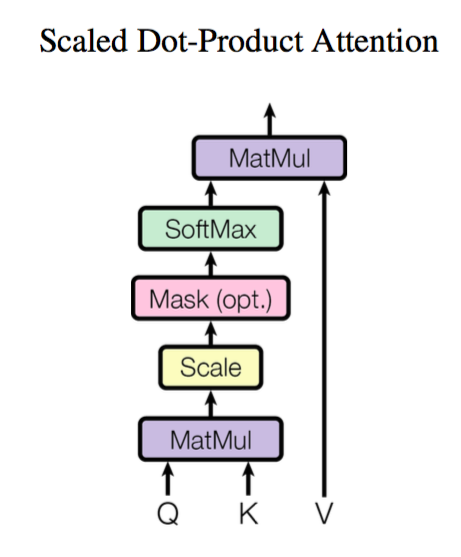
attention layer原理图

预训练阶段,对机器和数据量要求高,所幸,作者提供了主要语言英语和中文的预训练模 型,直接下载即可,中文预训练模型。因此,我们重点关注的是,如何构建和利用微调模型实现我们的目标。重点讲下作者在源码中给出的两个微调模型。看完之后,你可以会惊呼微调模型竟然这么简单。用run_classifier.py,整个50万样本量,微调阶段训练时间约为半个小时。
从代码中可以看到,run_squad.py和run_classifier.py微调模型是一层简单的全链接层,以此类推,如果你要实现命名实体识别等其他目标任务,可在预训练的模型基础上,加入少了全链接层。
- 二、我趟过的一些坑
1.tensorflow服务化部署的坑。
Tensorflow服务化部署有好几套接口,有版本历史原因,导致相互之间不兼容,对用户来说可谓非常不友好。我这边提供一个可用的接口方法供参考。 TensorFlow 模型如何对外提供服务。 微调模型跑出结果模型是checkpoint的文件格式,需转化为.pt格式提供出来。
2.TPU改成GPU estimator
官网源码中给出的是TPU estimator接口,改成普通estimator接口方案就能跑起来了。
https://www.tensorflow.org/guide/estimators
www.tensorflow.org
给个示例,run_classifier.py中关于TPU estimator的修改,直接上代码吧
(1)main()函数中estimator定义部分的修改

源代码中的定义

修改后的定义
(2) model_fn()部分代码修改,给个train部分的示例,eval部分同理可得。

源码

修改后
3.Out of Memory问题
官网源码中Readme.md中有关于Out of Memory解决的方法,如果你遇到类似问题,一定要先看这部分文档。文中意思大概是调节两个参数max_seq_length和train_batch_size,观察你GPU显存的占用情况 。我使用的GPU显存28GB,如果你想把微调模型跑起来,这个显存基本够了(train_batch_size=64,--max_seq_length=128 显存占用22GB)
- 三、参考资料
1.Bert as Service hanxiao/bert-as-service
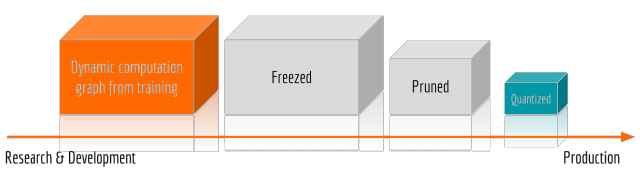
图优化方法
Bert预训练模型较为完整的服务化部署方法,预训练模型可作为NLP基础服务。源码中两个亮点:一是提供了图优化的方法,提升效率和降低显存消耗。Freezed图冻结把tf.Variable变为tf.Constant,Pruned去掉训练时多余的节点,Quantized降低浮点数维度,比如把int64改为int32。二是zeromq实现异步并发请求,设计了一套Bert服务化部署的软件架构。
2.参考我的另一篇博文,关于Bert的原理章鱼小丸子:NLP突破性成果 BERT 模型详细解读
- 四、总结
关于Bert的效果,我未做定量分析,但从个人评估结果来看,其在公开数据集的泛化能力,明显优于利用词向量预训练的QAnet等问答其他模型。
关于Bert的性能,对服务进行压力测试,根据应用场景,我调节的max length=30,耗时均值在400ms左右,能满足一般应用qps要求。如果对运算速度要求更高的产品,需改为GPU分布式计算。
较低成本实践Bert的路径:
第一步:找一台满足GPU显存要求的机器(一般是28GB左右,不同情况略有不同)
第二步:设置一个你能拿到数据集的微调任务,如分类、问答、实体标注等。
第三步:修改微调代码跑起来,验证效果。
