

Kafka 的适用场景
官方文档对 Kafka 的定义是
Apache Kafka® is a distributed streaming platform.
这是一个简单朴实让人难以捉摸的自我介绍。那在什么情况下可以使用它呢。有这么几种场景
- 当你需要一个消息系统时,可以考虑使用它。Kafka 提供了一个消息系统一般会具备的两种特性:消息队列和发布订阅
- 当你需要一个分布式的存储系统时,可以考虑使用它。Kafka 支持消息的持久化,你可以选择产生而不消费消息,以这种将信息保留到磁盘。Kafka 支持数据的多副本,高容错,即使一个副本损坏了可以由其他副本替代。另外令人泪目的是,数据量的增长并不会影响它的性能,你可以按你的需要不断的扩充集群
- 如果你需要进行流式计算,可以考虑使用它。它允许你实时处理源源不断的流数据。
Kafka 的核心概念
介绍完 Kafka 的用途,接下来介绍 Kafka 中几个核心的概念。
- 集群(cluster) - Kafka 是一个分布式的流式平台,所以它可以以集群的形式在多条机器上运行
- topic(主题) - 生产者将数据写入到不同的 topic 中,消费者可以订阅不同的 topic 并消费其中的数据。可以暂时简单理解成,将流式记录归成不同的分类,这个分类就是 topic
- 生产者,负责发布数据到 topic
- 消费者,负责从 topic 中获取并处理数据
Kafka 的结构
Topic
Topic 是很多条流记录的集合,可以先简单把它认为是一条队列,流记录不断地写入到队列中。
Topic 由一个或者多个分区组成,Topic 按一定的规则将记录发布到不同的分区中。如下图所示,topic 分成了三个分区,每个分区负责保存一部分数据。新产生的数据不断地追加到某一个分区的尾端,分区将保证这些数据是有序的,并且顺序是不变的。同时,分区给每条记录分配一个称之为 offset 的标识符,用于唯一标记一条记录。
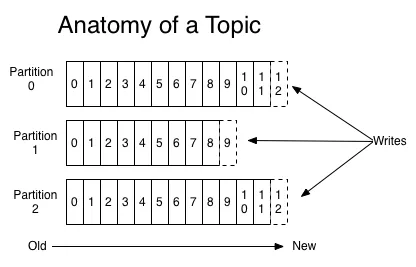
分区(Partition)
前面说过 topic 是由一个或者多个分区组成的。每个分区中的记录都是有序的(按发布到 topic 的时间)。
将 topic 分成多个分区有什么好处呢?
- 有助于水平扩展。每台机器的存储空间是有限的,当一台机器容纳不下所有数据时,最直接的想法就是将数据分散到多台机器中。Kafka 将 topic 分成多个分区,不同的分区分布到多个机器中,这样就可以很方便地实现扩展
- 提高性能。同个 topic 的不同分区的数据是可以被并行处理的。这样可以并行消费一个 topic 中多个分区的数据
- 负载均衡。分成多个分区并发布到多台机器中,可以让读写请求更均衡地落到不同的机器上,减轻单台机器的压力
同个分区内的数据是保证顺序的,但是同个 topic 的不同分区之间的数据是不保证顺序的。
生产者(Producer)
生产者负责选择 topic 和分区,将数据发布到分区中
消费者(Consumer)
消费者负责从 topic 的分区中取出并处理数据。实际上,消费者不是一个个孤立的个体,而是被组织成一个消费组,一个消费组有一个或多个消费者。消费组订阅 topic,然后该组内的消费者从这个 topic 里取数据。同个消费组内的消费者允许发布在不同的机器中。如下图。
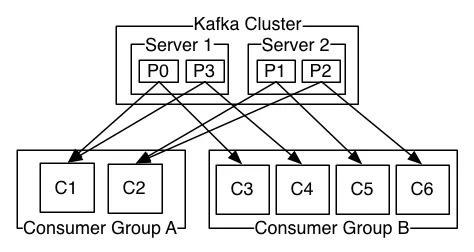
同个消费组里,topic 的一个分区只能由其中一个消费者实例消费,但一个消费者实例可以处理多个分区(这也就意味着消费者实例的数量不会多于分区的数量)。比如上例中,对于消费组 A,P0 和 P3分配给了 C1,C1 负责处理这两个分区的记录,C2 不能处理这两个分区的记录。如果消费组里新增了消费者,则会选择一些其他消费者负责的分区分配给它。如果消费组里移除了某个消费者,它所负责的分区将分配给同组里的其他消费者。
Kafka 提供的保证
这里直接引用官网原文的描述
At a high-level Kafka gives the following guarantees:
- Messages sent by a producer(生产者) to a particular topic partition(分区) will be appended in the order they are sent. That is, if a record M1 is sent by the same producer as a record M2, and M1 is sent first, then M1 will have a lower offset than M2 and appear earlier in the log.(即提供写顺序保证)
- A consumer instance(消费者实例) sees records in the order they are stored in the log.(即提供读顺序保证)
- For a topic with replication factor N, we will tolerate up to N-1 server failures without losing any records committed to the log.(即提供多副本保证数据不丢失)
资料参考:http://kafka.apache.org/intro
