

背景
总共有好几种。 1.标记-删除 2.标记-复制 3.标记-整理 4.分代
包含了几个概念。 1.标记 2.删除 3.复制 4.整理 5.分代
标记-删除
标记
到底什么是标记?标记的永远都是要删除的对象吗?不是。 标记只是一个叫法,标记的本质是基于root判断一个对象是否可达。不可达,就是死对象,可达,就是活对象,因为被引用。 所以,只要区分了死对象和活对象,就相当于标记了死对象和活对象,至于说具体标记了哪一种?看你要操作哪一种对象。你要操作死对象,那么这个时候就可以说标记了死对象,比如标记-清除算法,就是标记死对象,然后清除死对象。
标记-复制算法,就是标记活对象,然后复制活对象到另一个区。这个时候叫的时候,就是叫标记活对象。但本质上没有任何区别,就是jvm可以区分死对象和活对象而已。这个才是核心。
所以,标记-复制算法,最后一步才是删除死对象。一次性统一删除一个区的死对象,这个区就是一个新的没有使用的连续空间的区。
总结,本质上是jvm可以区分死对象活对象,操作的时候,也就可以区分死对象活对象,至于具体说标记了哪一种对象?这个不重要。因为这个不是本质,本质是jvm要操作的时候,可以区分死对象和活对象。
结论,不要关注是标记了哪一个,而应该关注要操作的是哪一个,操作哪一个,就是标记哪一个。
删除
删除的永远都是要删除的对象。
基础算法
这个是基础算法。后面的,都是改进。
步骤
1.标记的是要删除的数据
2.删除数据
3.最终的空间,是有的有数据,有的没数据(刚刚被删除),导致的问题是空间不连续,即所谓的碎片。 //缺点1,浪费空间
4.标记和删除,效率不高,还是因为空间不连续。//缺点2,速度慢
示意图
1.回收前 //一个图是回收之前,一个图是回收之后
2.回收后
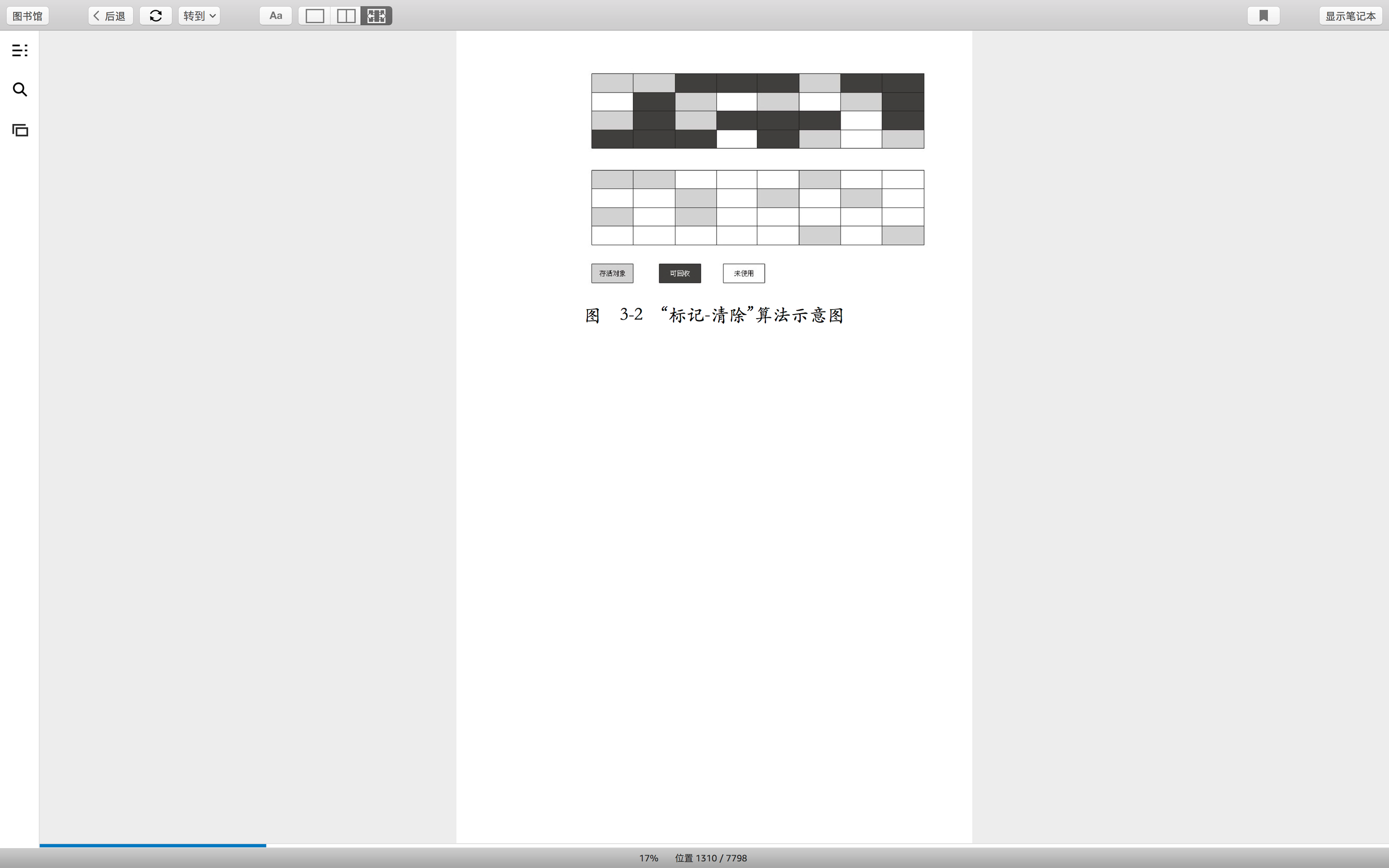
标记-复制
第一代
一半一半,两个区,一次只用一个区。
第二代
因为有个区,浪费了。所以为了利用空间,就把比例改为8 1 1。//现在jvm基本上都是采用这种。即标记-复制 + 分代。分代就是年轻代 + 老年代。
现在只浪费1的空间。
为什么1的空间,就够了?
因为大部分对象都是朝生夕死(大部分都是方法里的对象)。所以呢,剩下的对象比较少,也就是说能活下来的对象还是比较少的,所以复制这部分比较少的存活的对象到1,一般情况下,1就够了。不够,就复制到老年代。
复制的是死对象还是活对象?
活对象。标记的才是死对象。
优点
1.节约空间
2.提高速度
缺点
如果存活的对象,很多,怎么办?显然,这个时候,复制的数据就变多了,速度就变慢了。所以呢,怎么办?标记-整理。
应用场景?老年代的对象,就是存活的对象很多,且很久。所以,标记-整理,是老年代。
那什么是标记-整理呢?整理不还是复制吗?且是复制存活对象到一端去。这和标记-复制,有什么区别? cloud.tencent.com/developer/a… hllvm-group.iteye.com/group/topic… //这是r大的回复,总结就是一句话,一个是空间换时间,一个是时间换空间。怎么解释? 标记-复制,是需要空间,目的是速度快。为什么快?因为每个对象都是即时的复制到另外一个区。总结就是,优点是速度快,缺点是空间大。 标记-压缩,我们要追求的是,老年代空间极为珍贵,因为老年代的对象活的久且大。所以这个算法的目的是为了节约空间,这个才是这个算法的本质目的,为什么要设计这个算法,就是为了给老年代量身定制的。
具体是怎么节约空间的?为什么又是时间换空间? 因为现在没有多余的另一个区,所以节约了空间。 后果就是速度慢。为什么速度慢?因为现在没有多余的空间,所以这个时候,只是标记每一个活对象,并没有在标记的时候就复制,而是分2步走,先标记,后复制。复制是需要时间的,所以到后面复制的时候,统一复制,需要花费很多时间,这样就造成了full GC的时间比较久。
本质,标记-复制,是空间换时间,标记-压缩,是时间换空间。具体的原因,见上面的解释——其实,就是一句话,是同时标记和复制每一个活对象,还是分2步走,先只标记,后统一复制。
示意图
总共两个区
1.一个区是使用 //这个区被使用
2.一个区是用来存放复制存活的对象 //这个区是浪费的

标记-整理
示意图
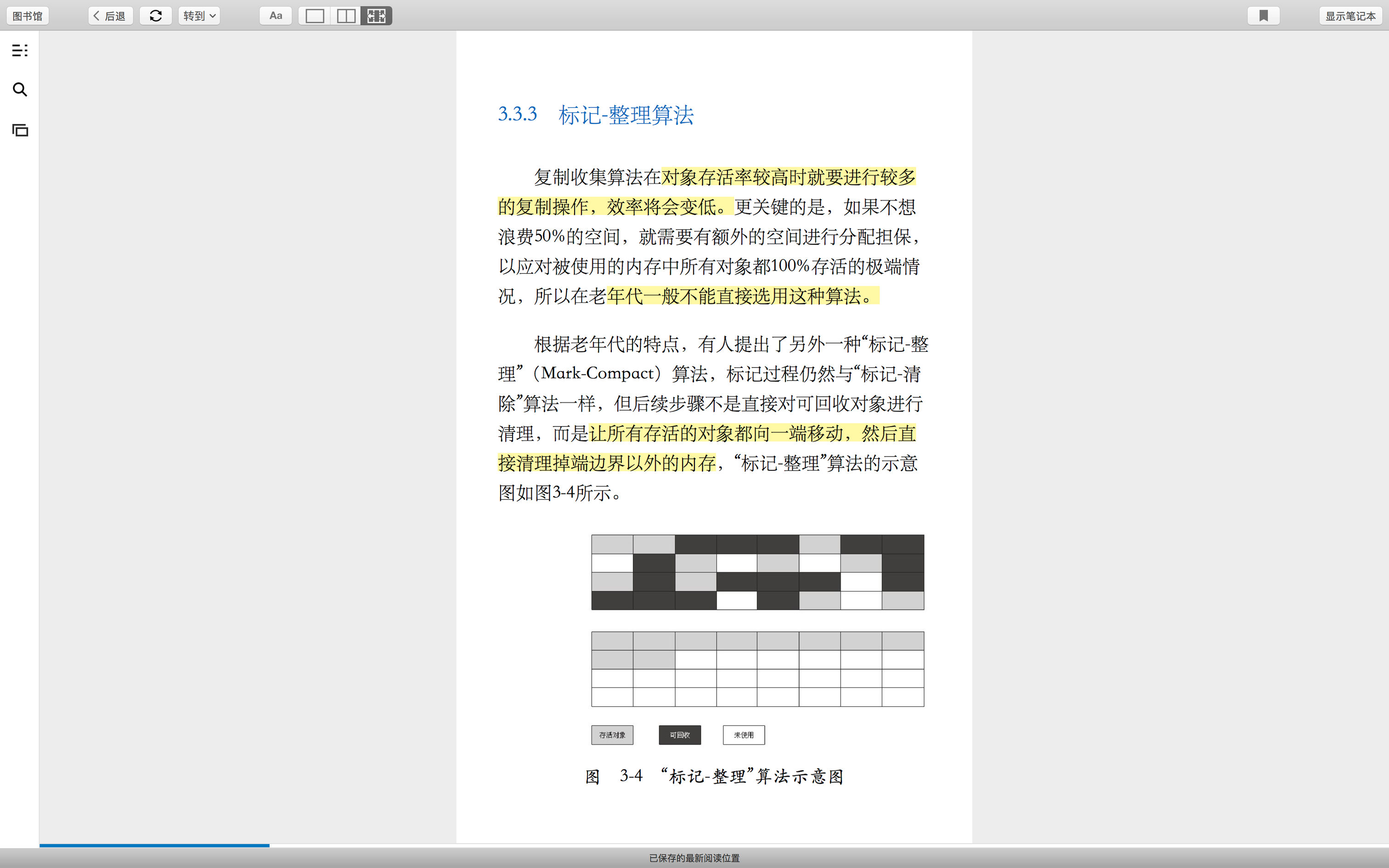
为什么老年代是标记-压缩?
因为老年代的对象存活比较久,且对象比较大,占用空间大。所以,老年代,要尽量节约空间,但是标记-复制是需要双倍的空间的。所以不适合老年代。
分代
分代不是一种算法,而是分代之后,在不同的代,使用不同的算法。这个才叫分代。//最佳实践
参考
周志明
高翔龙
r大
