

tomcat如何实现一键启停
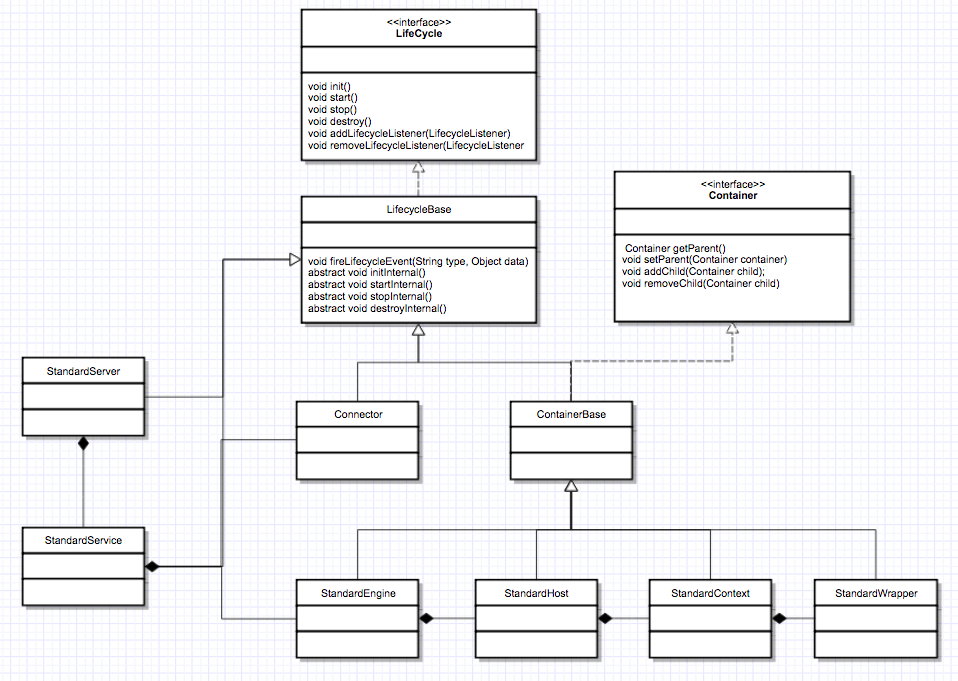
静态类图
动态启动
如果想让一个系统能够对外提供服务,我们需要创建、组装并启动这些组件;在服务停止的时候,我们还需要释放资源,销毁这些组件,因此这是一个动态的过程。也就是说,Tomcat 需要动态地管理这些组件的生命周期。
组件之间的关系
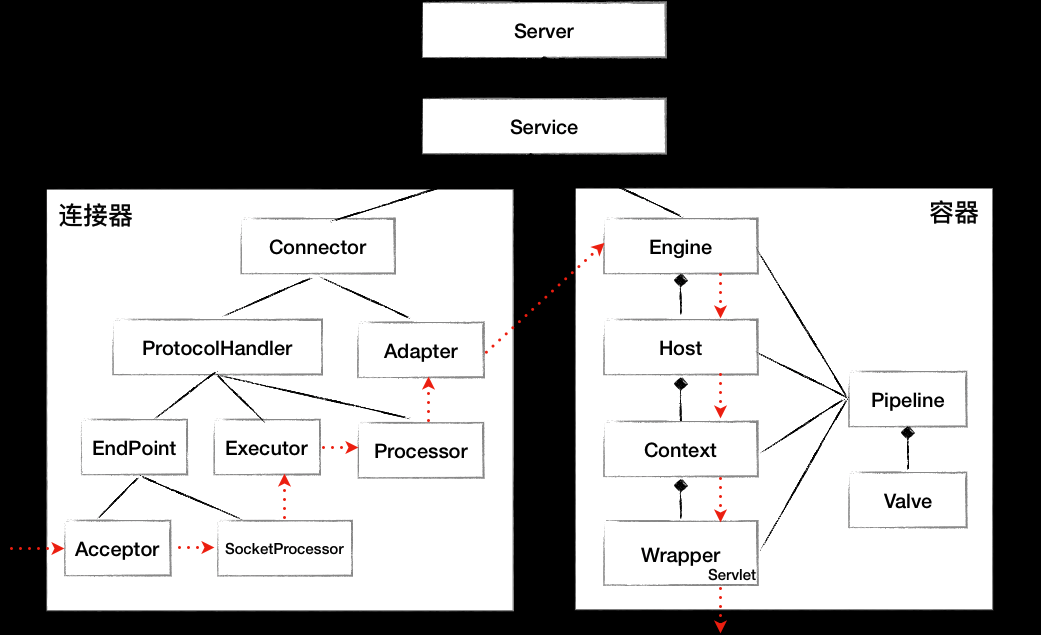
- 第一层关系是组件有大有小,大组件管理小组件,比如 Server 管理 Service,Service 又管理连接器和容器。
- 第二层关系是组件有外有内,外层组件控制内层组件,比如连接器是外层组件,负责对外交流,外层组件调用内层组件完成业务功能。 也就是说,请求的处理过程是由外层组件来驱动的。这两层关系决定了系统在创建组件时应该遵循一定的顺序。
- 第一个原则是先创建子组件,再创建父组件,子组件需要被“注入”到父组件中。
- 第二个原则是先创建内层组件,再创建外层组件,内层组建需要被“注入”到外层组件。
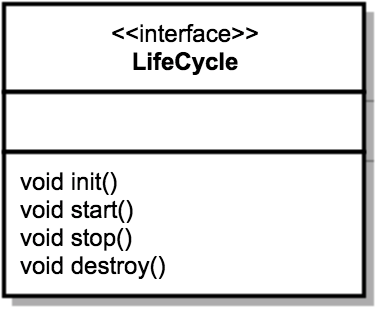
一键式启停:Lifecycle 接口
设计就是要找到系统的变化点和不变点。
- 组件创建所需要经历的 创建,初始化,启动着几个过程是不变的。
- 变化的只是不同的组件,这些方法的实现不一样。 因此,我们把不变点抽象出来成为一个接口,这个接口跟生命周期有关,叫作 Lifecycle。Lifecycle 接口里应该定义这么几个方法:init、start、stop 和 destroy,每个具体的组件去实现这些方法。
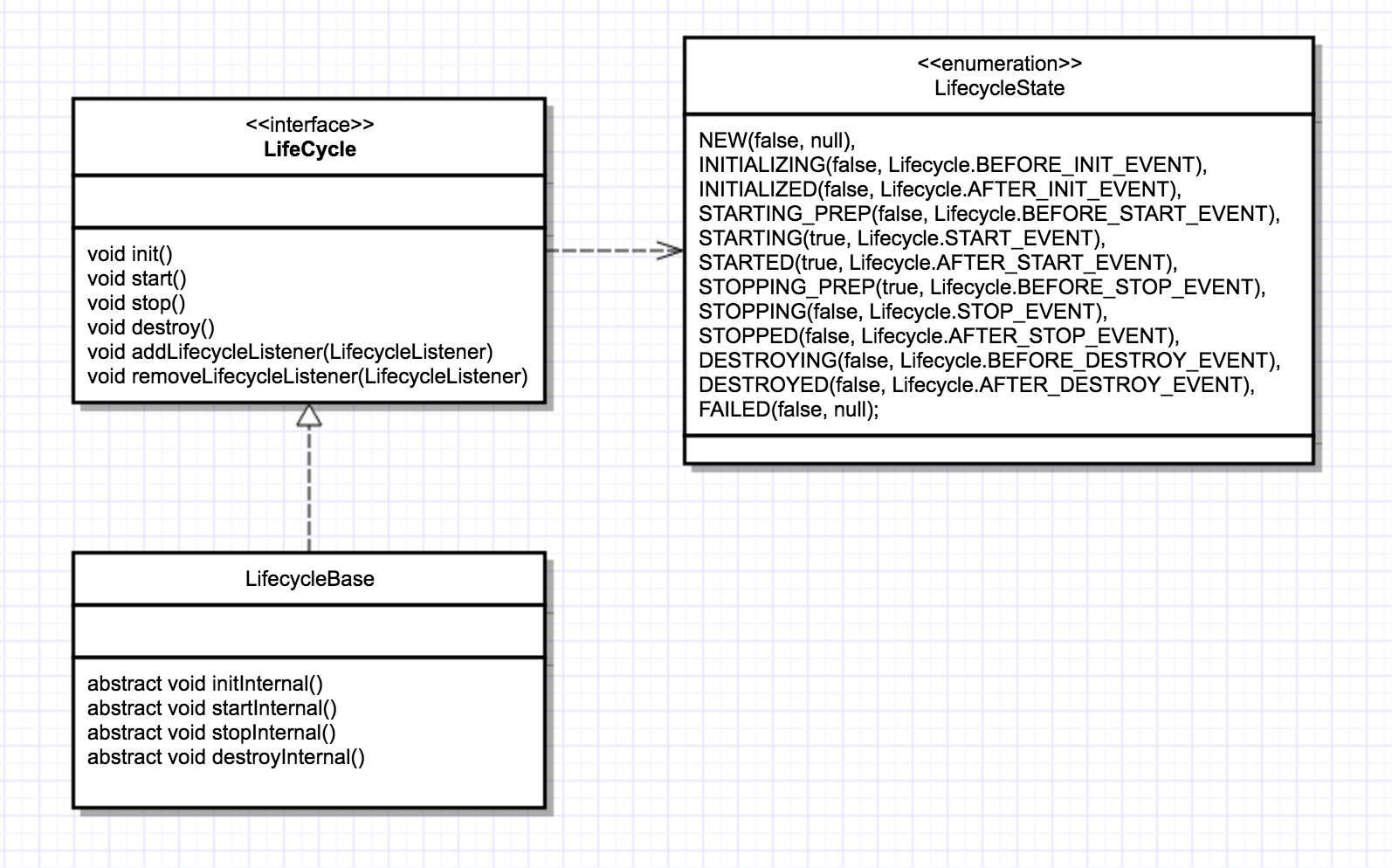
组合模式的
在父组件的 init 方法里需要创建子组件并调用子组件的 init 方法。同样,在父组件的 start 方法里也需要调用子组件的 start 方法,因此调用者可以无差别的调用各组件的 init 方法和 start 方法,这就是组合模式的使用
观察者模式
组件的 init 和 start 调用是由它的父组件的状态变化触发的,上层组件的初始化会触发子组件的初始化,上层组件的启动会触发子组件的启动,因此我们把组件的生命周期定义成一个个状态,把状态的转变看作是一个事件。而事件是有监听器的,在监听器里可以实现一些逻辑,并且监听器也可以方便的添加和删除,这就是典型的观察者模式
private final List<LifecycleListener> lifecycleListeners = new CopyOnWriteArrayList<>();
/**
* Allow sub classes to fire {@link Lifecycle} events.
*
* @param type Event type
* @param data Data associated with event.
*/
protected void fireLifecycleEvent(String type, Object data) {
LifecycleEvent event = new LifecycleEvent(this, type, data);
for (LifecycleListener listener : lifecycleListeners) {
listener.lifecycleEvent(event);
}
}
模板模式
接口可能有多个实现类,为了避免每个实现类都去实现一些重复的逻辑。可以定义一个基类来实现共同的逻辑。而基类中往往会定义一些抽象方法,所谓的抽象方法就是说基类不会去实现这些方法,而是调用这些方法来实现骨架逻辑。抽象方法是留给各个子类去实现的,并且子类必须实现,否则无法实例
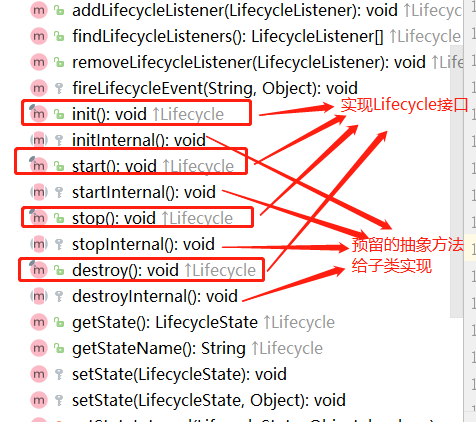
注意下图注释中的描述。
/**
* {@inheritDoc}
*/
@Override
public final synchronized void start() throws LifecycleException {
if (LifecycleState.STARTING_PREP.equals(state) || LifecycleState.STARTING.equals(state) ||
LifecycleState.STARTED.equals(state)) {
if (log.isDebugEnabled()) {
Exception e = new LifecycleException();
log.debug(sm.getString("lifecycleBase.alreadyStarted", toString()), e);
} else if (log.isInfoEnabled()) {
log.info(sm.getString("lifecycleBase.alreadyStarted", toString()));
}
return;
}
if (state.equals(LifecycleState.NEW)) {
init();
} else if (state.equals(LifecycleState.FAILED)) {
stop();
} else if (!state.equals(LifecycleState.INITIALIZED) &&
!state.equals(LifecycleState.STOPPED)) {
invalidTransition(Lifecycle.BEFORE_START_EVENT);
}
try {
setStateInternal(LifecycleState.STARTING_PREP, null, false);
startInternal(); //骨架代码中调用的预留的抽象方法,将来每个子类在使用本方法的时候,就是调用的它自己实现了startInternal
if (state.equals(LifecycleState.FAILED)) {
stop();
} else if (!state.equals(LifecycleState.STARTING)) {
invalidTransition(Lifecycle.AFTER_START_EVENT);
} else {
setStateInternal(LifecycleState.STARTED, null, false);
}
} catch (Throwable t) {
handleSubClassException(t, "lifecycleBase.startFail", toString());
}
}
生周期管理总体类图
connector的线程池是只处理连接的线程池,还是后台任务都共用的线程池?
Connector上的线程池负责处理这个它所接收到的所有请求。一个Connector有一个线程池。其他的后台任务也有专门的线程池,不会占用Connector的线程池。
其它精彩链接
- 和大家分享一篇介绍Tomcat启动的文章, 从startup.bat的源码开始分析的.www.cnblogs.com/tanshaoshen…
- 怎么启动Tomcat的源码、调试。怎么读源码。建议跟SpringBoot那样,用嵌入式方式启动Tomcat,这里有例子https://github.com/heroku/devcenter-embedded-tomcat
Tomcat的“高层们”都负责做什么?
执行startup.sh启动脚本后,执行了什么?
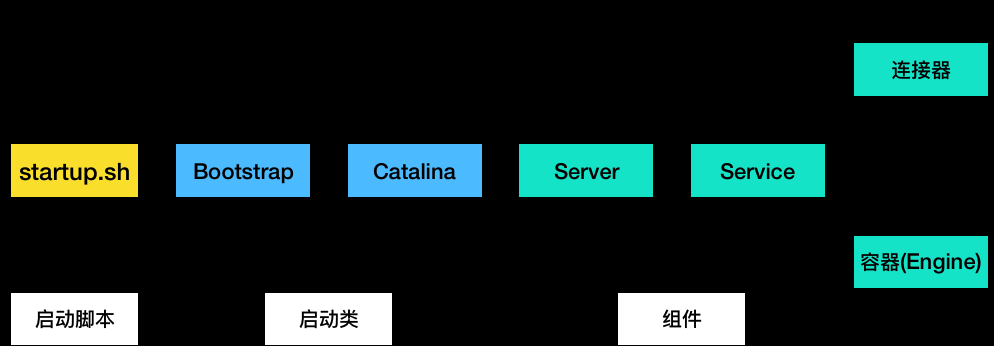
- Tomcat 本质是 Java 程序, startup.sh 启动 JVM 运行 Tomcat 启动类 bootstrap
- Bootstrap 初始化类加载器, 创建 Catalina
- Catalina 解析 server.xml, 创建相应组件, 调用 Server start 方法
- Server 组件管理 Service 组件并调用其 start 方法
- Service 负责管理连接器和顶层容器 Engine, 其会调用 Engine start 方法- 这些类不处理具体请求, 主要管理下层组件, 并分配请求
- 一个比喻:
如果我们把 Tomcat 比作是一家公司,
- 那么 Catalina 应该是公司创始人,因为 Catalina 负责组建团队,也就是创建 Server 以及它的子组件。
- Server 是公司的 CEO,负责管理多个事业群,每个事业群就是一个 Service。
- Service 是事业群总经理,它管理两个职能部门:一个是对外的市场部,也就是连接器组件;另一个是对内的研发部,也就是容器组件。
- Engine 则是研发部经理,因为 Engine 是最顶层的容器组件。
Catalina 功能
- 解析 server.xml, 创建定义的各组件, 调用 server init 和 start 方法
- 处理异常情况, 例如 ctrl + c 关闭 Tomcat. 其会在 JVM 中注册"关闭钩子"
- 关闭钩子, 在关闭 JVM 时做清理工作, 例如刷新缓存到磁盘
- 关闭钩子是一个线程, JVM 停止前会执行器 run 方法, 该 run 方法调用 server stop 方法
//创建并注册关闭钩子
if (useShutdownHook) {
if (shutdownHook == null) {
shutdownHook = new CatalinaShutdownHook();
}
Runtime.getRuntime().addShutdownHook(shutdownHook);//关闭钩子其实就是一个实现了run方法的线程对象。
}
Server 组件
- 实现类 StandServer 继承了 LifeCycleBase
- 子组件是 Service, 需要管理其生命周期(调用其 LifeCycle 的方法), 用数组保存多个 Service 组件, 动态扩容数组来添加组件
- 启动一个 socket Listen停止端口, Catalina 启动时, 调用 Server await 方法, 其创建 socket Listen 8005 端口, 并在死循环中等连接, 检查到 shutdown 命令, 调用 stop 方法
Service 组件,
- 实现类 StandService 包含 Server, Connector, Engine 和 Mapper 组件的成员变量
- 还包含 MapperListener 成员变量, 以支持热部署, 其Listen容器变化, 并更新 Mapper, 是观察者模式
- 需注意各组件启动顺序, 根据其依赖关系确定
- 先启动 Engine, 再启动 Mapper Listener, 最后启动连接器, 而停止顺序相反.
Engine 组件
- 实现类 StandEngine 继承 ContainerBase
- ContainerBase 实现了维护子组件的逻辑, 用 HaspMap 保存子组件, 因此各层容器可重用逻辑
- ContainerBase 用专门线程池启动子容器, 并负责子组件启动/停止, "增删改查"
- 请求到达 Engine 之前, Mapper 通过 URL 定位了容器, 并存入 Request 中. Engine 从 Request 取出 Host 子容器, 并调用其 pipeline 的第一个 valve
在实际应用场景中,tomcat在shutdown的时候,无法杀死java进程,还得kill,这是为何呢?
Tomcat会调用Web应用的代码来处理请求,可能Web应用代码阻塞在某个地方。
tomcat一般生产环境线程数大小建议怎么设置呢
理论上:线程数=((线程阻塞时间 + 线程忙绿时间) / 线程忙碌时间) * cpu核数如果线程始终不阻塞,一直忙碌,会一直占用一个CPU核,因此可以直接设置 线程数=CPU核数。但是现实中线程可能会被阻塞,比如等待IO。因此根据上面的公式确定线程数。那怎么确定线程的忙碌时间和阻塞时间?要经过压测,在代码中埋点统计.
connector的线程池设置成800合理吗?
问题:刚到新公司,看他们把一个tomact的connector的线程池设置成800,这个太夸张了吧,connector的线程池只是用来处理接收的http请求,线程池不会用来处理其他业务本身的事情,设置再大也只能提高请求的并发,并不能提高系统的响应,让这个线程池干其他的事情,而且线程数太高,线程上下文切换时间也高,反而会降低系统的响应速度吧?我理解是不是对的,老师?还有一个问题就是设置的connector线程数,是tomcat启动的时候就会初始化这么多固定的线程还是这只是一个上限,还有就是如果线程处于空闲状态,会不会进行上下文切换呢?
解答:这里误解了Connector中的线程池,这个线程池就是用来处理业务的。另外你提到线程数设的太高,会有线程切换的开销,这是对的。线程数具体设多少,根据具体业务而定,如果你的业务是IO密集型的,比如大量线程等待在数据库读写上,线程数应该设的越高。如果是CPU密集型,完全没有阻塞,设成CPU核数就行。800这个数有点高,我猜你们的应用属于IO密集型。
备注
本文是我个人学习了李号双老师的专栏课程之后,结合专栏文章和老师对同学答疑整理的学习笔记。仅供分享。更多精彩内容,大家可以扫描下方二位码,在极客时间订阅李号双老师的《深入拆解Tomcat & Jetty》。获取一手学习资料。

