

前言
文的文字及图片来源于网络,仅供学习、交流使用,不具有任何商业用途,版权归原作者所有,如有问题请及时联系我们以作处理。
作者: 肖豪
PS:如有需要Python学习资料的小伙伴可以加点击下方链接自行获取
http://note.youdao.com/noteshare?id=3054cce4add8a909e784ad934f956cef虽说找到了资源网站可以下载了,但是每次都要打开浏览器,输入网址,找到该美剧,然后点击链接才能下载。时间长了就觉得过程好繁琐,而且有时候网站链接还会打不开,会有点麻烦。
写个爬虫,抓取该网站上所有美剧链接,并保存在文本文档中,想要哪部剧就直接打开复制链接到迅雷就可以下载啦。
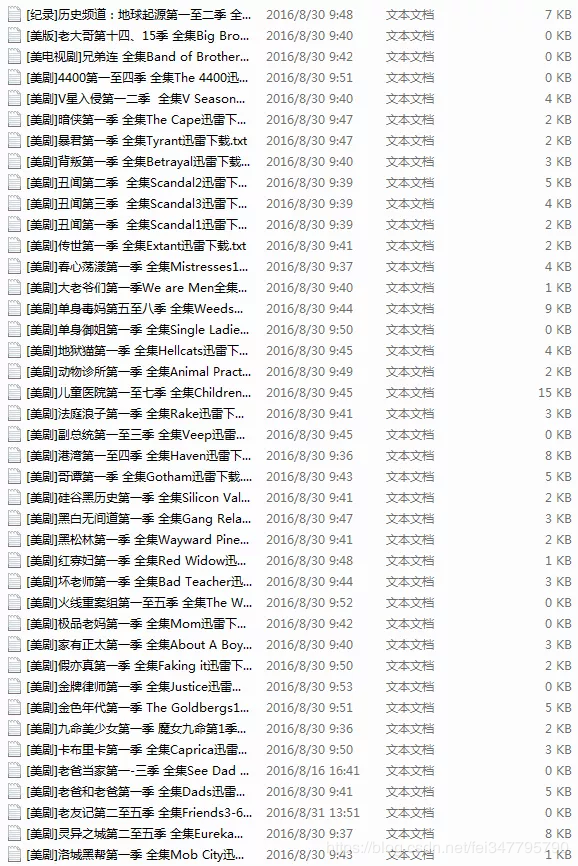 以下就是实现代码。
以下就是实现代码。
import sys
import threading
import time
reload(sys)
sys.setdefaultencoding('utf-8')
class Archives(object):
def save_links(self,url):
try:
data=requests.get(url,timeout=3)
content=data.text
link_pat='"(ed2k://\|file\|[^"]+?\.(S\d+)(E\d+)[^"]+?1024X\d{3}[^"]+?)"'
name_pat=re.compile(r'<h2 class="entry_title">(.*?)</h2>',re.S)
links = set(re.findall(link_pat,content))
name=re.findall(name_pat,content)
links_dict = {}
count=len(links)
except Exception,e:
pass
for i in links:
links_dict[int(i[1][1:3]) * 100 + int(i[2][1:3])] = i#把剧集按s和e提取编号
try:
with open(name[0].replace('/',' ')+'.txt','w') as f:
print name[0]
for i in sorted(list(links_dict.keys())):#按季数+集数排序顺序写入
f.write(links_dict[i][0] + '\n')
print "Get links ... ", name[0], count
except Exception,e:
pass
def get_urls(self):
try:
for i in range(2015,25000):
base_url='http://cn163.net/archives/'
url=base_url+str(i)+'/'
if requests.get(url).status_code == 404:
continue
else:
self.save_links(url)
except Exception,e:
pass
def main(self):
thread1=threading.Thread(target=self.get_urls())
thread1.start()
thread1.join()
if __name__ == '__main__':
start=time.time()
a=Archives()
a.main()
end=time.time()
print end-start