

前言
需要Python源码、PDF、视频资料可以点击下方链接获取
http://note.youdao.com/noteshare?id=3054cce4add8a909e784ad934f956cef运行环境
python3.7
Windows
vscode
运行依赖包
requests ( pip install requests 即可安装)
re
爬虫可以简单的分为:
获取数据
分析数据
存储数据
下载数据
简单来说一个网页是由一个html文件解析构成,我们需要获取这个文本内容。
每个浏览器都可以通过开发者工具获取到文本内容,以chrome为例,打开网页后,右键->检查。
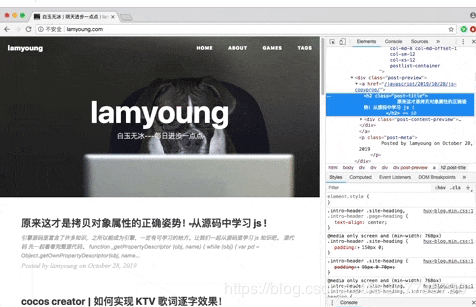 右边的 Elements 就是我们要下载的数据。
右边的 Elements 就是我们要下载的数据。
让我们看看 requests 是如何获取这个数据的。
url='http://lamyoung.com/';
html=requests.get(url);
if html.status_code == 200:
html_bytes=html.content;
html_str=html_bytes.decode();分析数据
这次我们用正则表达式去解析源数据,截取到我们需要。
 现在我们的目标是抓取博客的文章标题和链接,我们可以通过刚才的开发者工具获取文章标题和链接的特征。
现在我们的目标是抓取博客的文章标题和链接,我们可以通过刚才的开发者工具获取文章标题和链接的特征。
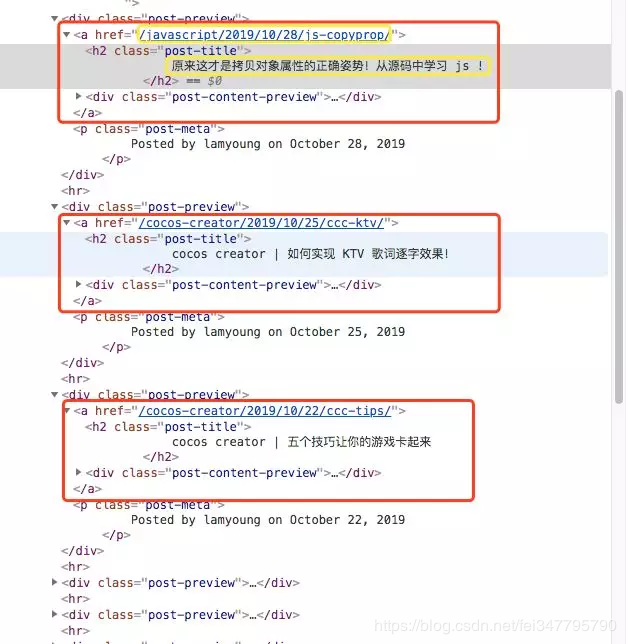 使用正则表达式中的 findall 把所有内容找出来,并保存在字符串中。
使用正则表达式中的 findall 把所有内容找出来,并保存在字符串中。
write_content = ''
all_items = re.findall(regex,html_str);
for item in all_items:
write_content=f'{write_content}\n{item[1]}\nhttp://lamyoung.com{item[0]}\n'我们可以点几个下一页,很容易发现其中的规律。
第一页:lamyoung.com/
第三页:lamyoung.com/page3/ ...
为此,我们加个循环判断就可以啦。
index=1
while True:
page_url = '';
if index>1:
page_url=f'page{index}/'
url=f'http://lamyoung.com/{page_url}';
html=requests.get(url);
if html.status_code != 200:
print(html);
break;在判断状态码为200时,退出循环。
存储数据
这次我们就用文本存储来结束我们的教程吧。
with open('lamyoung_title_out.txt','w',encoding='utf-8') as f:
f.write(write_content)
.
