

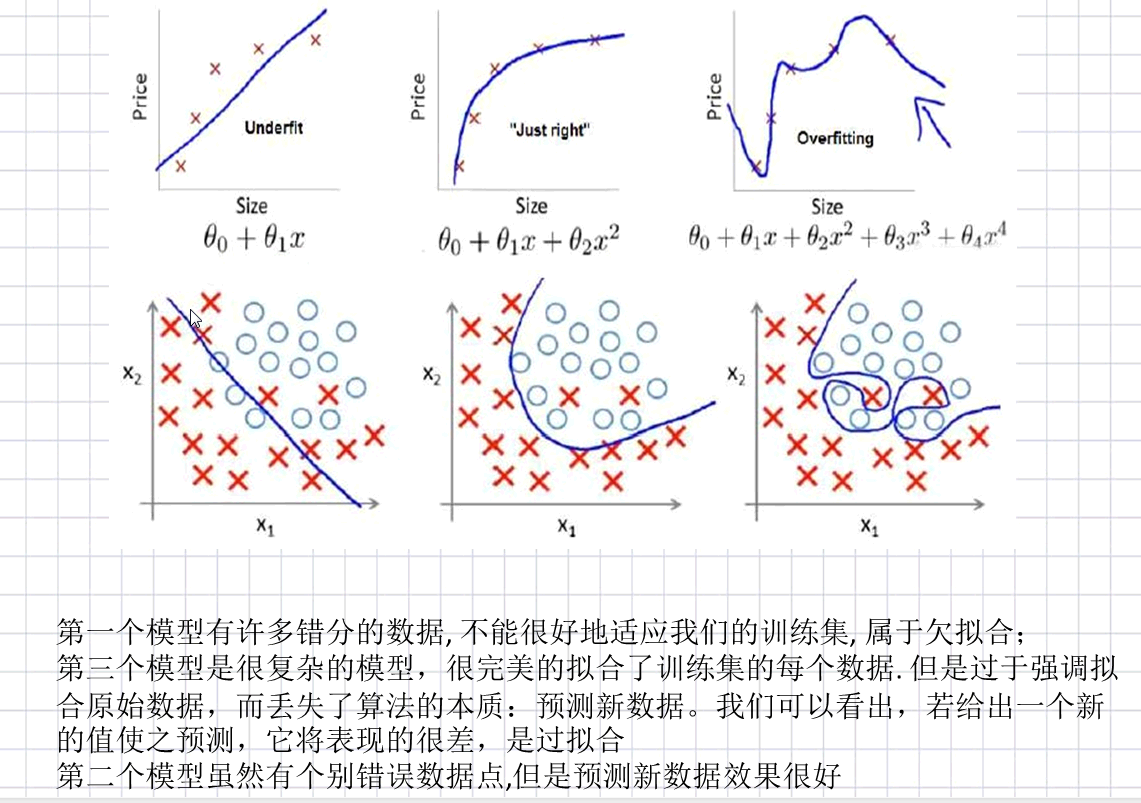
什么是过拟合
当我们的数据在训练集上表现得很好,但是在遇到新数据后,表现的没有那么出色,这种现象就叫做过拟合
出现过拟合的原因
出现这种现象的主要原因是训练数据中存在噪音或者训练数据及太少
下面我们来简单了解三种拟合情况
当我们发现了过拟合问题时,应该如何去处理呢?
1.正则化(Regularization)(L1和L2)
2.数据增强(Data augmentation),也就是增加训练数据样本
3.Dropout
4.early stopping
- 正则化 保留所有特征,但是需要减少参数大小(magnitude)
以下是正则化的两种形式
L1正则化(lasso):
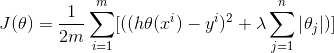
L1是模型各个参数的绝对值之和
L2正则化(岭回归 Ridge):
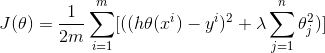
L1是模型各个参数平方和的开放值
两者的区别:
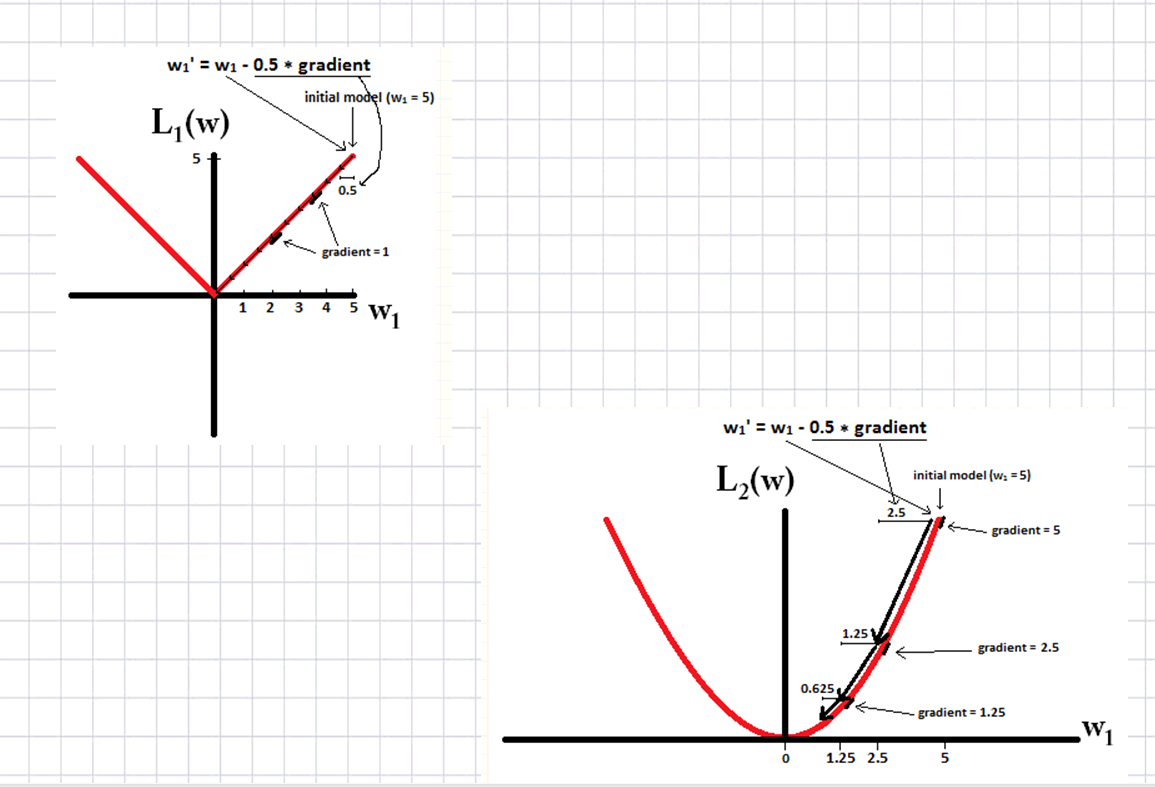
L1导致稀疏,L2导致平缓
在什么情况下使用L1,什么情况下使用L2?
L1和L2的差别,为什么一个让绝对值最小,一个让平方最小,会有那么大的差别呢?我看到的有两种几何上直观的解析:
下降速度:
我们知道,L1和L2都是规则化的方式,我们将权值参数以L1或者L2的方式放到代价函数里面去。然后模型就会尝试去最小化这些权值参数。而这个最小化就像一个下坡的过程,L1和L2的差别就在于这个“坡”不同,如下图:L1就是按绝对值函数的“坡”下降的,而L2是按二次函数的“坡”下降。所以实际上在0附近,L1的下降速度比L2的下降速度要快,所以会非常快得降到0。不过我觉得这里解释的不太中肯,当然了也不知道是不是自己理解的问题。
总结就是:L1会趋向于产生少量的特征,而其他的特征都是0,而L2会选择更多的特征,这些特征都会接近于0。Lasso在特征选择时候非常有用,而Ridge就只是一种规则化而已。
- 数据集扩增(data augmentation)
曾经有大牛这样说过:训练模型有时候不是由于算法好赢了,而是由于拥有海量的数据才赢了。
由此可见,海量的训练数据,对于训练出更好的模型至关重要! 在机器学习中,算法本身并不能决出胜负,不能武断地说这些算法谁优谁劣,由于数据对算法性能的影响非常大。
- Dropout 通过改动神经网络本身来实现
L1、L2正则化是通过改动代价函数来实现的,而Dropout则是通过改动神经网络本身来实现的,它是在训练网络时用的一种技巧(trike),它的流程例如以下:
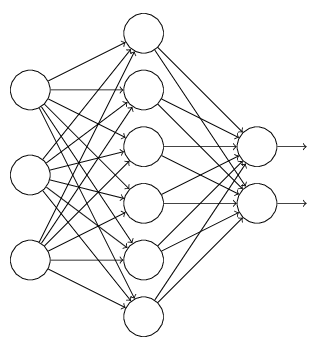
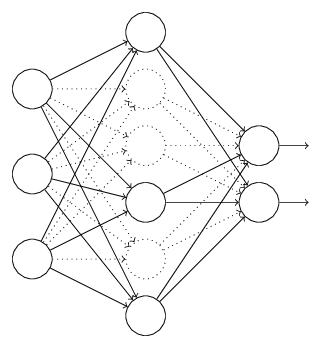
以上就是一次迭代的过程,在第二次迭代中,也用相同的方法,仅仅只是这次删除的那一部分隐层单元,跟上一次删除掉的肯定是不一样的。由于我们每一次迭代都是“随机”地去删掉一部分。
第三次、第四次……都是这样,直至训练结束。
- 提前终止(Early stopping)
对模型进行训练的过程即是对模型的参数进行学习更新的过程,这个参数学习的过程往往会用到一些迭代方法,如梯度下降(Gradient descent)学习算法。Early stopping便是一种迭代次数截断的方法来防止过拟合的方法,即在模型对训练数据集迭代收敛之前停止迭代来防止过拟合。
Early stopping方法的具体做法是,在每一个Epoch结束时(一个Epoch集为对所有的训练数据的一轮遍历)计算validation data的accuracy,当accuracy不再提高时,就停止训练。这种做法很符合直观感受,因为accurary都不再提高了,在继续训练也是无益的,只会提高训练的时间。那么该做法的一个重点便是怎样才认为validation accurary不再提高了呢?并不是说validation accuracy一降下来便认为不再提高了,因为可能经过这个Epoch后,accuracy降低了,但是随后的Epoch又让accuracy又上去了,所以不能根据一两次的连续降低就判断不再提高。一般的做法是,在训练的过程中,记录到目前为止最好的validation accuracy,当连续10次Epoch(或者更多次)没达到最佳accuracy时,则可以认为accuracy不再提高了。此时便可以停止迭代了(Early Stopping)。这种策略也称为“No-improvement-in-n”,n即Epoch的次数,可以根据实际情况取,如10、20、30……
- 从数据预处理角度
对原始数据通过PCA, t-SNE等降维技术进行降维处理
以上便是我对数据拟合一些看法和观点
