利用tenserflow对 y = 0.1x + 0.3 进行拟合
要求每二十次输出一下偏置和权重,直到拟合成功
- 先引入tenserflow 和 numpy
import tensorflow as tf
import numpy as np
- 创建训练集
x_data = np.random.rand(100).astype(np.float)
#生成100个随机数列,在tenserflow中大部分的数据的type定义为float32
y_data = x_data *0.1 + 0.3
# 我们要预测的函数的偏置w就是0.1,权重b就是0.3
开始创建tenserflow结构
- 权重
Weights = tf.Variable(tf.random_uniform([1],-1.0,1.0))
# Weights必须大写,#Variable是位置的参数变量[1]表示一维数列,随机数列生成的范围是-1 - 1.0之间
- 偏置
biases = tf.Variable(tf.zeros([1]))
# 初始值给他一个0,他会一步一步学习,把这个初始值从0学习到0.3
- 预测函数
y = Weights *x_data +biase
- 损失函数
loss = tf.reduce_mean(tf.square(y-y_data))
# (y预测-真实)^2
- 优化器(梯度下降算法)
optimizer = tf.train.GradientDescentOptimizer(0.5)
#这是一个优化器,这里面采用的是梯度下降算法,学习速率是0.5,一般情况下这个学习速率是要小于1的
train = optimizer.minimize(loss)
# 利用设定好的优化器对损失函数进行优化,minimize是为了找到最优解
- 注意,如果运用了tenserflow中的Variables(可变参数),就要进行初始化
init = tf.initialize_all_variables()
# 初始化所有可变参数
tenserflow结构全部结束
- 定义会话
sess = tf.Session()
sess.run(init)
#Session相当于一个指针,指向要处理的地方,处理的地方就被激活起来了
#激活init,这一步非常重要
12.设定每20次就输出一下权重和偏执
for step in range(201):
sess.run(train)
if step % 20 == 0:
print(step,sess.run(Weights),sess.run(biases))
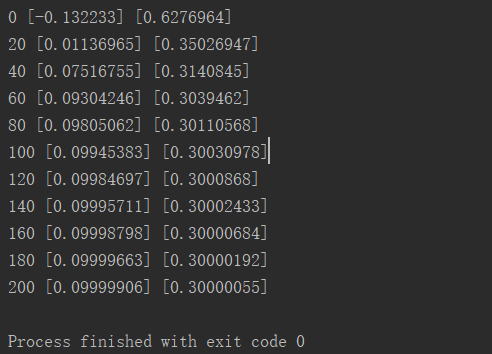
运行结果如下: