

线程实现方式
- 轻量级进程程与内核线程 1比1
- 用户线程与内核线程 N比1
- 轻量级进程与用户进程 N:M
1:1线程模型
在 Linux 操作系统编程中,往往都是通过 fork()函数创建一个子进程来代表一个内核中的线程。一个进程调用 fork() 函数后,系统会先给新的进程分配资源,例如,存储数据和代码的空间。然后把原来进程的所有值都复制到新的进程中,只有少数值与原来进程的值(比如 PID)不同,这相当于复制了一个主进程。
采用 fork() 创建子进程的方式来实现并行运行,会产生大量冗余数据,即占用大量内存空间,又消耗大量 CPU 时间用来初始化内存空间以及复制数据。
轻量级进程 能够共享主进程数据
相对于 fork() 系统调用创建的线程来说,LWP 使用 clone() 系统调用创建线程,该函数是将部分父进程的资源的数据结构进行复制,复制内容可选,且没有被复制的资源可以通过指针共享给子进程。因此,轻量级进程的运行单元更小,运行速度更快。LWP是跟内核线程一对一映射的,每个 LWP 都是由一个内核线程支持。
N比1的线程模型
1:1 线程模型由于跟内核是一对一映射,所以在线程创建、切换上都存在用户态和内核态的切换,性能开销比较大。除此之外,它还存在局限性,主要就是指系统的资源有限,不能支持创建大量的 LWP。
该线程模型是在用户空间完成了线程的创建、同步、销毁和调度,已经不需要内核的帮助了,也就是说在线程创建、同步、销毁的过程中不会产生用户态和内核态的空间切换,因此线程的操作非常快速且低消耗。
N:M模型
N:1 线程模型的缺点在于操作系统不能感知用户态的线程,因此容易造成某一个线程进行系统调用内核线程时被阻塞,从而导致整个进程被阻塞。
N:M 线程模型是基于上述两种线程模型实现的一种混合线程管理模型,即支持用户态线程通过 LWP 与内核线程连接,用户态的线程数量和内核态的 LWP 数量是 N:M 的映射关系。
而 Go 语言是使用了 N:M 线程模型实现了自己的调度器,它在 N 个内核线程上多路复用(或调度)M 个协程,协程的上下文切换是在用户态由协程调度器完成的,因此不需要陷入内核,相比之下,这个代价就很小了。
假设程序中默认创建两个线程为协程使用,在主线程中创建协程 ABCD…,分别存储在就绪队列中,调度器首先会分配一个工作线程 A 执行协程 A,另外一个工作线程 B 执行协程 B,其它创建的协程将会放在队列中进行排队等待。
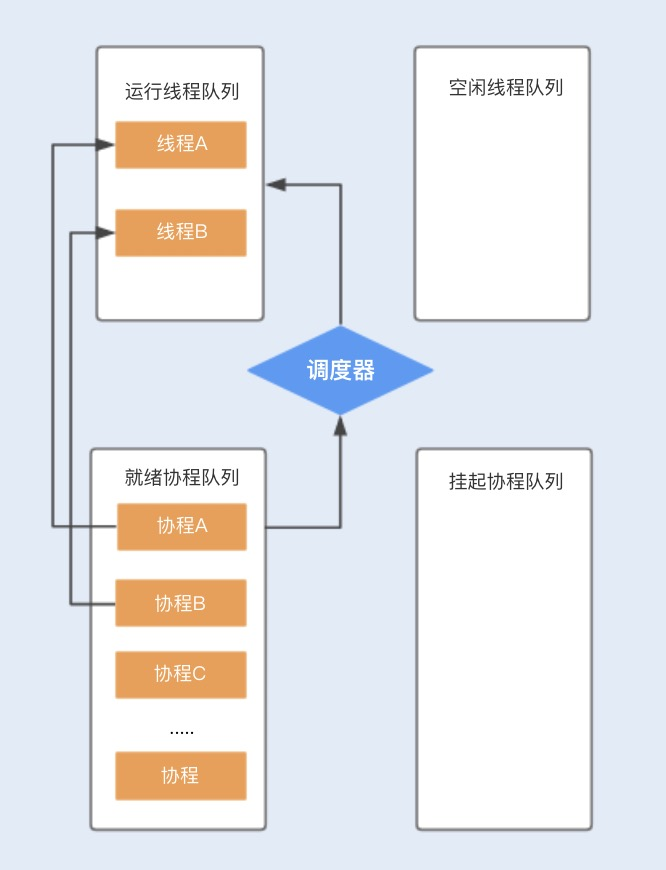
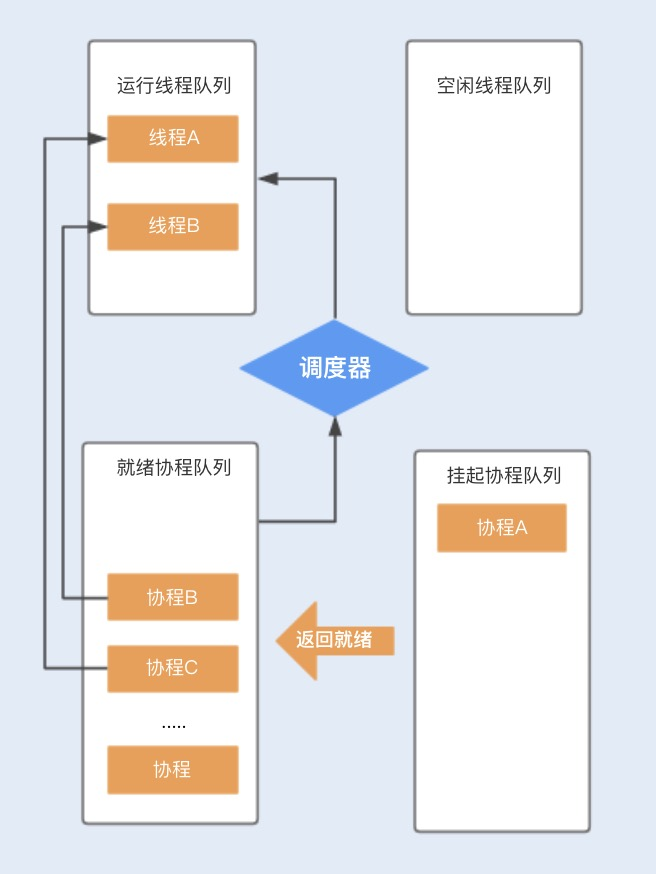
当协程 A 调用暂停方法或被阻塞时,协程 A 会进入到挂起队列,调度器会调用等待队列中的其它协程抢占线程 A 执行。当协程 A 被唤醒时,它需要重新进入到就绪队列中,通过调度器抢占线程,如果抢占成功,就继续执行协程 A,失败则继续等待抢占线程。
Java协程框架
- 在编译时使用 maven 插件;
- 在运行时调用 kilim.tools.Weaver 工具;
- 在运行时使用 kilim.tools.Kilim invoking 调用 Kilim 的类文件;
- 在 main 函数添加 if (kilim.tools.Kilim.trampoline(false,args)) return。
Kilim 框架包含了四个核心组件,分别为:任务载体(Task)、任务上下文(Fiber)、任务调度器(Scheduler)以及通信载体(Mailbox)。
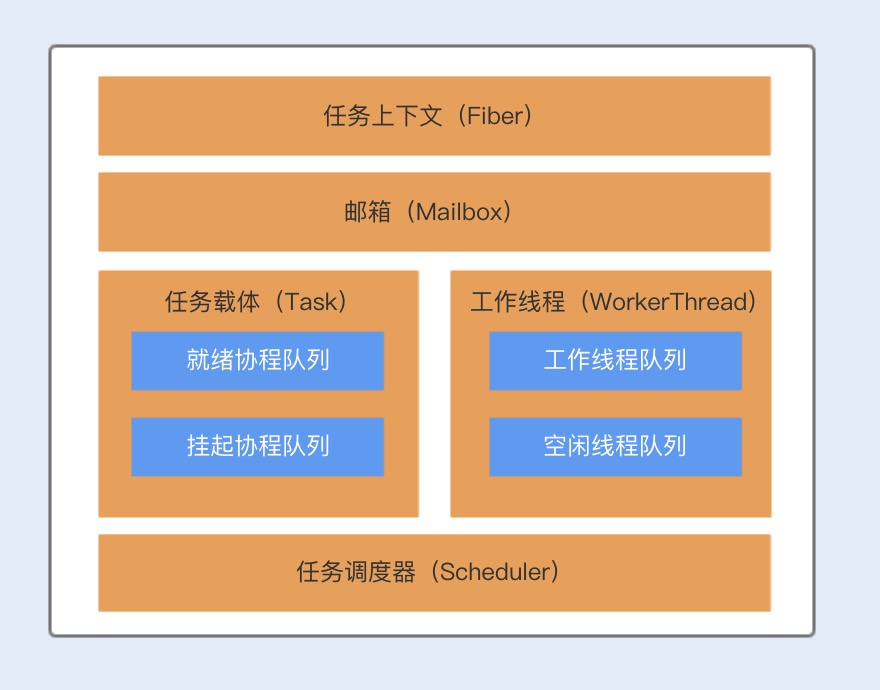
Task 对象主要用来执行业务逻辑,我们可以把这个比作多线程的 Thread,与 Thread 类似,Task 中也有一个 run 方法,不过在 Task 中方法名为 execute,我们可以将协程里面要做的业务逻辑操作写在 execute 方法中。
Fiber 对象与 Java 的线程栈类似,主要用来维护 Task 的执行堆栈,Fiber 是实现 N:M 线程映射的关键。
Scheduler 是 Kilim 实现协程的核心调度器,Scheduler 负责分派 Task 给指定的工作者线程 WorkerThread 执行,工作者线程 WorkerThread 默认初始化个数为机器的 CPU 个数。
Mailbox 对象类似一个邮箱,协程之间可以依靠邮箱来进行通信和数据共享。协程与线程最大的不同就是,线程是通过共享内存来实现数据共享,而协程是使用了通信的方式来实现了数据共享,主要就是为了避免内存共享数据而带来的线程安全问题。
