


概念:LADV是DataV内嵌的智能识别设计产品,能够迅速学习和识别手绘草图、信息图表、大屏截图等资料,并在DataV内自动生成可配置的可视化应用。有了LADV今后人人都能做可视化专家了!先来看看LADV的效果:

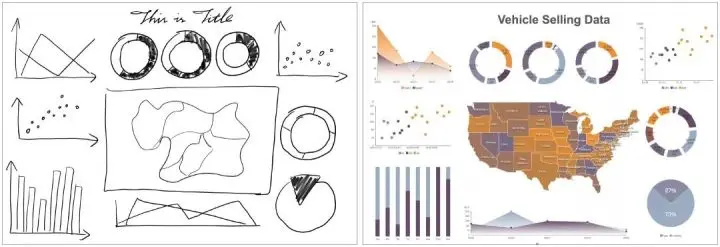 以上例子中,生成的可视化图表,均可以在DataV的环境下做进一步的样式调优和数据接入,最终发布为一个实时数据驱动展示的页面。
以上例子中,生成的可视化图表,均可以在DataV的环境下做进一步的样式调优和数据接入,最终发布为一个实时数据驱动展示的页面。
概念:LADV是DataV内嵌的智能识别设计产品,能够迅速学习和识别手绘草图、信息图表、大屏截图等资料,并在DataV内自动生成可配置的可视化应用。
有了LADV今后人人都能做可视化专家了!
先来看看LADV的效果:
以上例子中,生成的可视化图表,均可以在DataV的环境下做进一步的样式调优和数据接入,最终发布为一个实时数据驱动展示的页面。
1.LADV解决了什么问题?
简单来说,就是大幅降低数据可视化的设计成本。让用户在制作数据可视化应用时,可以将更多的精力投放在前期需求梳理、指标设计,和后期的数据探索、可视分析这些关键环节上。纵观数据可视化这个垂直领域,包括DataV在内的很多团队都在尝试降低可视化的实现的工程成本(如下图1, 2)。然而除了工程成本本身,数据可视化的设计效率极大的影响了数据挖掘效率。工业界可视化先驱如Tableau, Power BI等提出的解决方案是为用户提供不同的模版。但模版不可能完全贴合实际使用场景下的需求,很多用户在使用过程中,只能向可视化设计的高门槛以及冗长的制作时间妥协,选择近似的模版来解决。如何让各种背景的用户真正制作自己中意的数据可视化一直是一个难题。而DataV团队研发的LADV——一个基于深度学习的可视化生成系统,通过机器学习可视化案例的风格而生成数据可视化(如下图3),恰恰就是为了解决这个问题而生的。
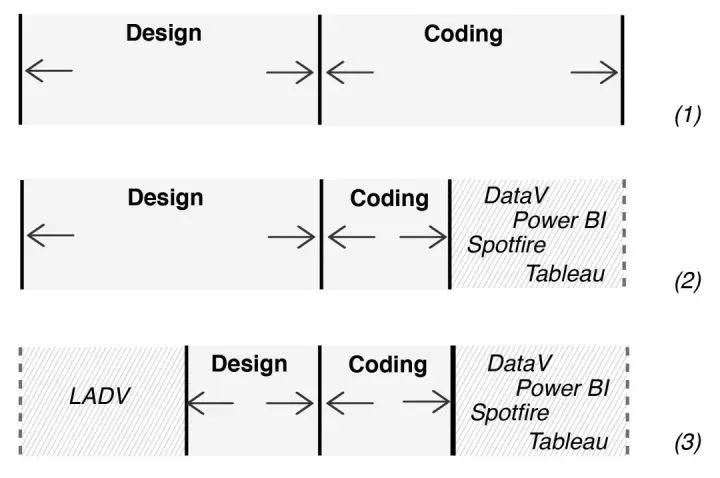
简单来说,就是大幅降低数据可视化的设计成本。让用户在制作数据可视化应用时,可以将更多的精力投放在前期需求梳理、指标设计,和后期的数据探索、可视分析这些关键环节上。
纵观数据可视化这个垂直领域,包括DataV在内的很多团队都在尝试降低可视化的实现的工程成本(如下图1, 2)。然而除了工程成本本身,数据可视化的设计效率极大的影响了数据挖掘效率。
工业界可视化先驱如Tableau, Power BI等提出的解决方案是为用户提供不同的模版。但模版不可能完全贴合实际使用场景下的需求,很多用户在使用过程中,只能向可视化设计的高门槛以及冗长的制作时间妥协,选择近似的模版来解决。如何让各种背景的用户真正制作自己中意的数据可视化一直是一个难题。而DataV团队研发的LADV——一个基于深度学习的可视化生成系统,通过机器学习可视化案例的风格而生成数据可视化(如下图3),恰恰就是为了解决这个问题而生的。
2.颠覆可视化设计和搭建流程
2.1 传统流程
数据可视化设计需要多方配合,就DataV举例如下图传统流程,有产品和分析同学进行需求调研,而设计同学会根据所需图表进行高保真设计, 最后会交由前端同学进行还原。这样的流程由于需要多方协同,导致效率变慢。更重要的是,这样的流程致使很多没有设计能力的用户缺少创建属于自己可视化的能力。
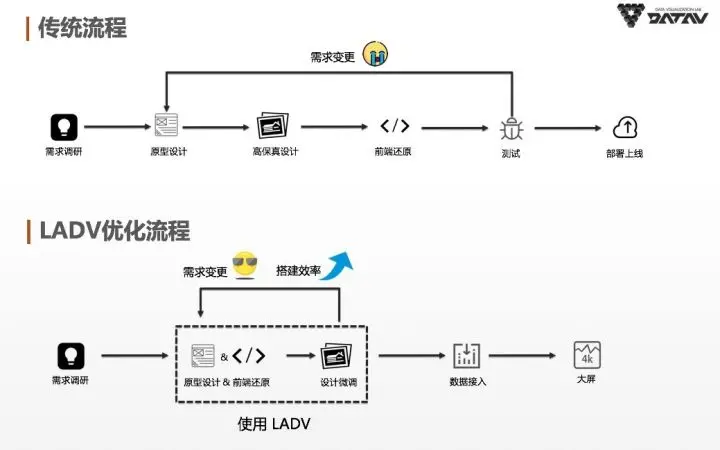
数据可视化设计需要多方配合,就DataV举例如下图传统流程,有产品和分析同学进行需求调研,而设计同学会根据所需图表进行高保真设计, 最后会交由前端同学进行还原。这样的流程由于需要多方协同,导致效率变慢。更重要的是,这样的流程致使很多没有设计能力的用户缺少创建属于自己可视化的能力。
2.2 LADV优化流程
通过LADV,我们设计了一种新的可视化创建流程。如上图所示,LADV极大减少了传统的设计流程,新的流程支持通过图片进行原型设计及前端还原,并支持后续的设计微调。
通过LADV,我们设计了一种新的可视化创建流程。如上图所示,LADV极大减少了传统的设计流程,新的流程支持通过图片进行原型设计及前端还原,并支持后续的设计微调。
3.技术方案
3.1.1 图表识别模型技术
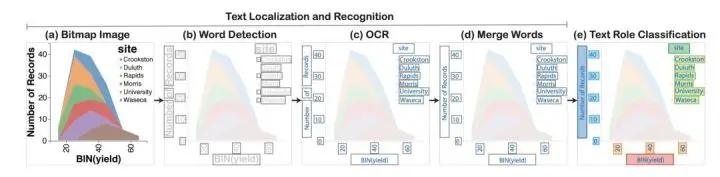
深度学习技术在近些年来得到飞速发展,在不同领域都取得优异的成绩。包括在数据图表分类领域也取得了很大的进展,如学术界的Revision, ChartSense 等。但大多数的模型仅仅能够进行图片分类,而非物体识别(换句话说,不仅进行图片分类,同时识别该类型图片所在的位置)。现有的方案中最优的也只是能够通过OCR技术识别文字的位置及内容(如下图),很难做到识别图表及图表的位置,如柱状图,饼图等。更何况物体识别所需的图表在可视化图片中的相对位置等信息,更是让这些数据看起来是不可能完成搜集的。
然而DataV又恰恰拥有数以万计的数据可视化模版数据,所以我们通过DataV的数据训练了可以识别图表位置及类型的物体识别模型,这也是物体识别模型首次应用于数据图表领域。同时,LADV不仅仅能够识别图表的类型及位置,还可以将可视化界面的颜色进行提取。从而将原案例风格中更多的维度迁移到机器生成的数据可视化界面中。
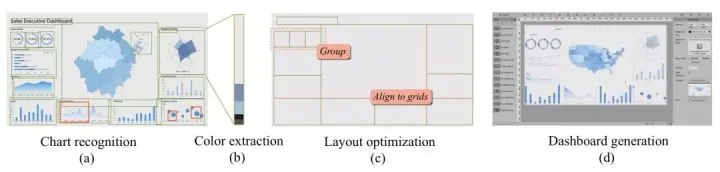
深度学习技术在近些年来得到飞速发展,在不同领域都取得优异的成绩。包括在数据图表分类领域也取得了很大的进展,如学术界的Revision, ChartSense 等。但大多数的模型仅仅能够进行图片分类,而非物体识别(换句话说,不仅进行图片分类,同时识别该类型图片所在的位置)。
现有的方案中最优的也只是能够通过OCR技术识别文字的位置及内容(如下图),很难做到识别图表及图表的位置,如柱状图,饼图等。更何况物体识别所需的图表在可视化图片中的相对位置等信息,更是让这些数据看起来是不可能完成搜集的。
然而DataV又恰恰拥有数以万计的数据可视化模版数据,所以我们通过DataV的数据训练了可以识别图表位置及类型的物体识别模型,这也是物体识别模型首次应用于数据图表领域。同时,LADV不仅仅能够识别图表的类型及位置,还可以将可视化界面的颜色进行提取。从而将原案例风格中更多的维度迁移到机器生成的数据可视化界面中。
3.1.2 识别结果优化
在得到识别结果的基础上,我们进行了对识别结果的优化。例如我们使用了Grid Design这样的设计规范,来避免由识别导致的布局误差(如上图a,c),并能够将存在布局不规范的原图进行规范。
在得到识别结果的基础上,我们进行了对识别结果的优化。例如我们使用了Grid Design这样的设计规范,来避免由识别导致的布局误差(如上图a,c),并能够将存在布局不规范的原图进行规范。
3.2 颜色识别模型技术
色彩是大屏展示不可或缺的成分之一,在使用颜色时不仅需要考虑美观度和协调性,还需要考虑到可读性。我们将从原始图片中提取颜色并在优化后加以应用。首先,从图片中提取颜色及其相应占比,一般来说在一个大屏中背景色的占比是最大的, 所以使用占比最大的颜色作为背景色。文本颜色将影响大屏的可读性,我们根据WCAG对比度标准计算出使得和背景色对比度达到7:1的文本颜色。接着对提取到的颜色进行过滤,去除背景色相似色和文本色相似色,然后对剩余的颜色进行聚类得到主色。最后使用色板生成方案生成色板并应用于大屏中。
色彩是大屏展示不可或缺的成分之一,在使用颜色时不仅需要考虑美观度和协调性,还需要考虑到可读性。我们将从原始图片中提取颜色并在优化后加以应用。首先,从图片中提取颜色及其相应占比,一般来说在一个大屏中背景色的占比是最大的, 所以使用占比最大的颜色作为背景色。文本颜色将影响大屏的可读性,我们根据WCAG对比度标准计算出使得和背景色对比度达到7:1的文本颜色。接着对提取到的颜色进行过滤,去除背景色相似色和文本色相似色,然后对剩余的颜色进行聚类得到主色。最后使用色板生成方案生成色板并应用于大屏中。
3.3 文字及字体识别模型技术
在即将发布的版本中,LADV可以支持对文字及字体的识别,同时将识别到的文字及字体还原到生成可视化中。在字体识别中,我们使用了ResNet-18 作为识别的模型。从而实现了能够识别案例可视化中的字体,例如包括衬线体及无衬线体等。LADV同时使用了OCR等传统方案对文字进行了识别。
在即将发布的版本中,LADV可以支持对文字及字体的识别,同时将识别到的文字及字体还原到生成可视化中。在字体识别中,我们使用了ResNet-18 作为识别的模型。从而实现了能够识别案例可视化中的字体,例如包括衬线体及无衬线体等。LADV同时使用了OCR等传统方案对文字进行了识别。
3.4 识别图表映射
从 LADV 生成 DataV 大屏的过程主要分为两步——大屏基本配置生成和大屏配置优化。首先,我们将 LADV 识别得到的图表类型映射为 DataV 中的组件类型,同时结合图表的位置,使用默认的图表样式配置和数据配置,生成一份“JSON”格式的大屏的基本配置。在这一步中,我们主要解决了大屏内容和布局的生成,使用默认的样式配置和数据在视觉层面还远不能达到我们的需求,因此我们还要针对这两个部分进行优化。我们将 LADV 识别得到色彩信息作为大屏的主题配色,修改大屏相关色彩配置(如背景颜色和文字颜色),并遍历大屏中的每个组件,应用当前的主题配色,这个步骤使得大屏整体的色彩会更加丰富和和谐。这里需要注意的是,由于手绘稿的色彩相对比较单一,所以我们没有直接提取手绘稿的色彩信息,而是应用了一些内置的主题配色,对生成的大屏进行美化。除了色彩的优化外,我们根据识别得到的文字信息,修改文字类组件的字体、字号等样式配置,并使用识别得到的文字内容,作为文字组件的数据。完成以上步骤后,我们通过 DataV 提供的大屏生成接口,将最终的大屏配置导入到DataV 产品中生成为可交互的可视化大屏,用户可以在此基础上继续优化,完成最终的数据可视化。
从 LADV 生成 DataV 大屏的过程主要分为两步——大屏基本配置生成和大屏配置优化。首先,我们将 LADV 识别得到的图表类型映射为 DataV 中的组件类型,同时结合图表的位置,使用默认的图表样式配置和数据配置,生成一份“JSON”格式的大屏的基本配置。
在这一步中,我们主要解决了大屏内容和布局的生成,使用默认的样式配置和数据在视觉层面还远不能达到我们的需求,因此我们还要针对这两个部分进行优化。我们将 LADV 识别得到色彩信息作为大屏的主题配色,修改大屏相关色彩配置(如背景颜色和文字颜色),并遍历大屏中的每个组件,应用当前的主题配色,这个步骤使得大屏整体的色彩会更加丰富和和谐。这里需要注意的是,由于手绘稿的色彩相对比较单一,所以我们没有直接提取手绘稿的色彩信息,而是应用了一些内置的主题配色,对生成的大屏进行美化。
除了色彩的优化外,我们根据识别得到的文字信息,修改文字类组件的字体、字号等样式配置,并使用识别得到的文字内容,作为文字组件的数据。完成以上步骤后,我们通过 DataV 提供的大屏生成接口,将最终的大屏配置导入到DataV 产品中生成为可交互的可视化大屏,用户可以在此基础上继续优化,完成最终的数据可视化。
3.5 技术框架总结
在LADV的技术中,我们总结了目前LADV的技术框架,如下图。
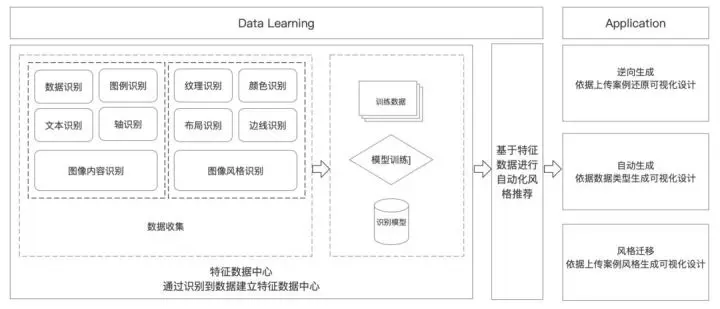
在LADV的技术中,我们总结了目前LADV的技术框架,如下图。
4.项目实例
4.1 LADV操作演示
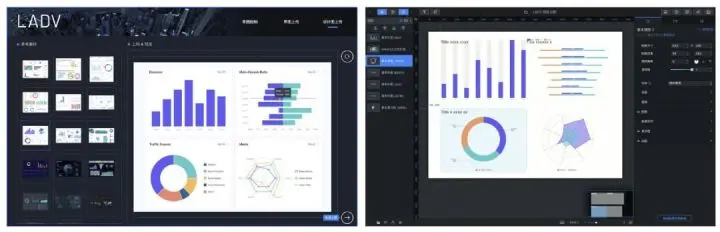
我们仅仅需要上传喜欢的数据可视化模版,就可以生成一份已在DataV内编辑好并可交互的可视化界面。同时,我们还可以对该模版进行继续编辑,以达到我们想要的结果。 下图左为选择案例模版页面,同时可以上传图片,并点击右下角上传案例。右侧图片为通过LADV学习而生成的可视化界面,并可在DataV内进行继续编辑。
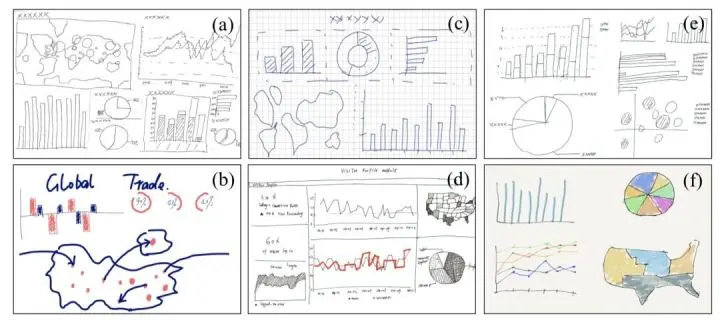
与此同时,LADV考虑到有些用户更倾向于优先绘制草图,因为草图可以抽象出不同的设计。所以,我们提供了可以快速将用户手绘的数据可视化草图通过识别来生成可视化界面的方法。通过与浙江大学 CAD实验室合作,DataV收集了近2,000张手绘设计稿,并通过物体识别模型进行训练。
我们仅仅需要上传喜欢的数据可视化模版,就可以生成一份已在DataV内编辑好并可交互的可视化界面。同时,我们还可以对该模版进行继续编辑,以达到我们想要的结果。 下图左为选择案例模版页面,同时可以上传图片,并点击右下角上传案例。右侧图片为通过LADV学习而生成的可视化界面,并可在DataV内进行继续编辑。
与此同时,LADV考虑到有些用户更倾向于优先绘制草图,因为草图可以抽象出不同的设计。所以,我们提供了可以快速将用户手绘的数据可视化草图通过识别来生成可视化界面的方法。通过与浙江大学 CAD实验室合作,DataV收集了近2,000张手绘设计稿,并通过物体识别模型进行训练。
4.2 用户反馈
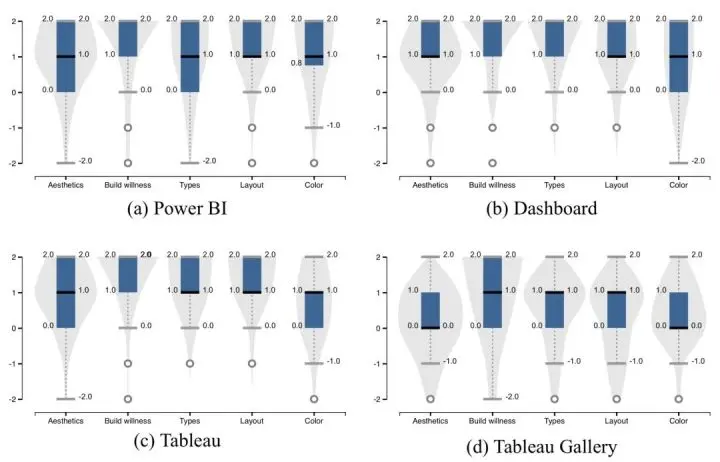
我们在通过谷歌图片搜索,尝试通过搜索3种不同的关键词得到的可视化案例来测试LADV,(1)Power BI, ( 2 ) Tableau, ( 3 ) Dashboard。同时我们还搜集了( 4 ) Tableau Gallery的可视化案例界面 我们发现,除了 Tableau Gallery,用户对所有的图表生成在美观上都给了很高的评价,并且,尽管Tableau Gallery目前美观分数最低(原因为较多infographic案例,不规则图表等),但用户依旧愿意基于LADV生成图去继续搭建,而非从零开始设计可视化的界面。这也意味着,LADV有能力彻底解放我们在可视化设计上的能力。
可见的将来,我们相信在设计可视化界面时,LADV可以参与到各个环节中。我们真诚的希望,LADV不仅能够帮助用户解决可视化的设计问题,同时能够激起用户对可视化设计的兴趣,进而通过可视化设计及图表布局,颜色等展示维度来影响数据的挖掘。
我们在通过谷歌图片搜索,尝试通过搜索3种不同的关键词得到的可视化案例来测试LADV,(1)Power BI, ( 2 ) Tableau, ( 3 ) Dashboard。同时我们还搜集了( 4 ) Tableau Gallery的可视化案例界面 我们发现,除了 Tableau Gallery,用户对所有的图表生成在美观上都给了很高的评价,并且,尽管Tableau Gallery目前美观分数最低(原因为较多infographic案例,不规则图表等),但用户依旧愿意基于LADV生成图去继续搭建,而非从零开始设计可视化的界面。这也意味着,LADV有能力彻底解放我们在可视化设计上的能力。
可见的将来,我们相信在设计可视化界面时,LADV可以参与到各个环节中。我们真诚的希望,LADV不仅能够帮助用户解决可视化的设计问题,同时能够激起用户对可视化设计的兴趣,进而通过可视化设计及图表布局,颜色等展示维度来影响数据的挖掘。
5.未来期待
最后,经过接近一年的努力, LADV通过与国内外学术界不同方式的合作受益良多,如国内可视化先驱浙江大学CAD实验室的陈为教授,并得到了TVCG主编Klaus Mueller教授的合作邀请。该功能已在企业版和专业版中上线,体验点击链接哦!
链接:data.aliyun.com/visual/data…本文原作者:言顾
本文为云栖社区原创内容,未经允许不得转载。
最后,经过接近一年的努力, LADV通过与国内外学术界不同方式的合作受益良多,如国内可视化先驱浙江大学CAD实验室的陈为教授,并得到了TVCG主编Klaus Mueller教授的合作邀请。
该功能已在企业版和专业版中上线,体验点击链接哦!
链接:data.aliyun.com/visual/data…
本文原作者:言顾
本文为云栖社区原创内容,未经允许不得转载。
