

一般情况下
scrapy是这样的
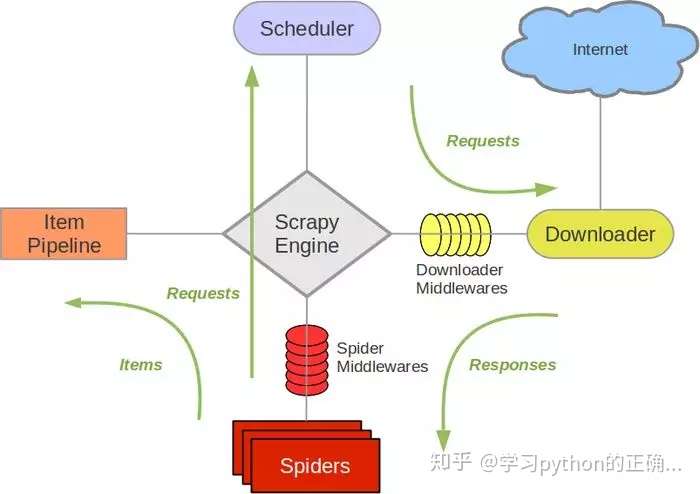
可以看到
1、调度器 Scheduler 会调度 Requests 队列中的请求
2、然后将每个请求交给下载器 Downloader 下载
3、这时候就会得到相应的 item 数据交给 item Pipeline 处理
如果我们希望有多个爬虫
来爬取一个网站的数据
那么我们的请求队列就要共享而不能说都是 Request 队列要不然爬到的数据就都乱套了

所以我们需要一个共享的队列
就比如说你希望一块蛋糕能被快速吃掉
你叫来了小明
可是小明只有一张嘴啊
于是你又叫来了他的 py 们小红和小紫

但是你总不能说给他们每人各一块蛋糕吧
你是希望一块蛋糕被快速吃掉
你要他们 3 张嘴一起吃掉 同一块蛋糕
你把他们的嘴比作爬虫
把蛋糕比作要爬取的网站
是不是就比较容易理解了

那么多个爬虫如何共享一个请求队列以及如何搭建分布式部署爬虫呢
接下来就是
学习 Python 的正确姿势

我们需要用到 redis 队列来共享
巧的是scrapy-redis这个库就可以使用 redis 队列

在此之前我们先搞几台服务器
一台用来搭建 redis一台用来搭建数据库再搞三台来运行爬虫
服务器买起
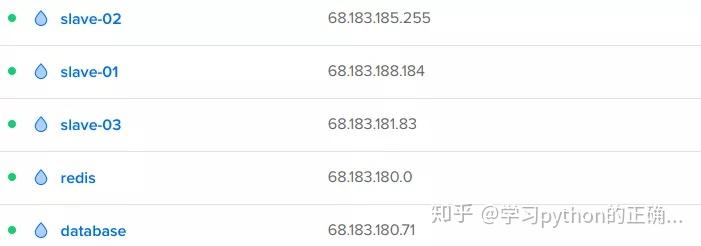
别问我哪来这么多服务器
有钱任性(良心帅b喊起来)

服务器有了搭建起来呗
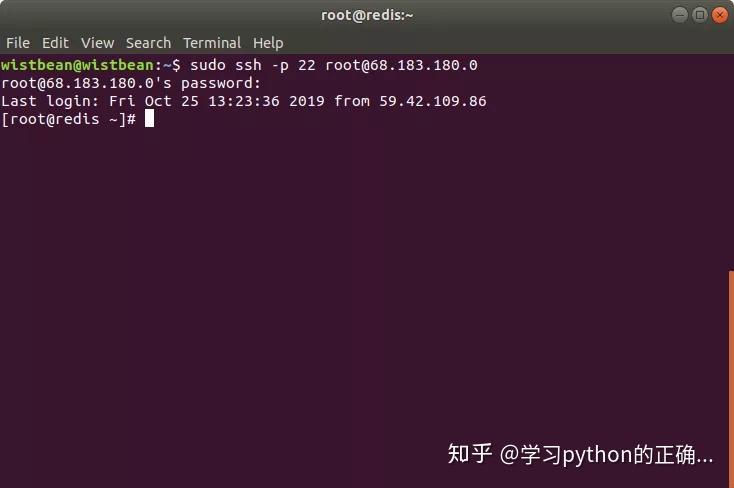
先把 redis 装上
连接到 redis 服务器
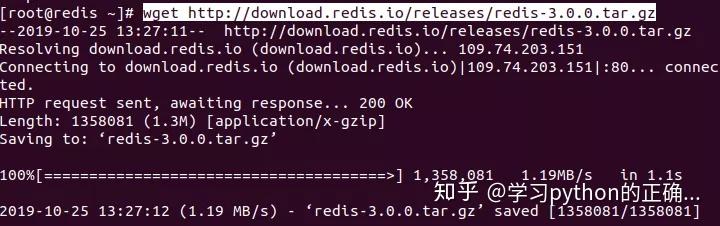
下载 redis
解压到 /usr/local 下
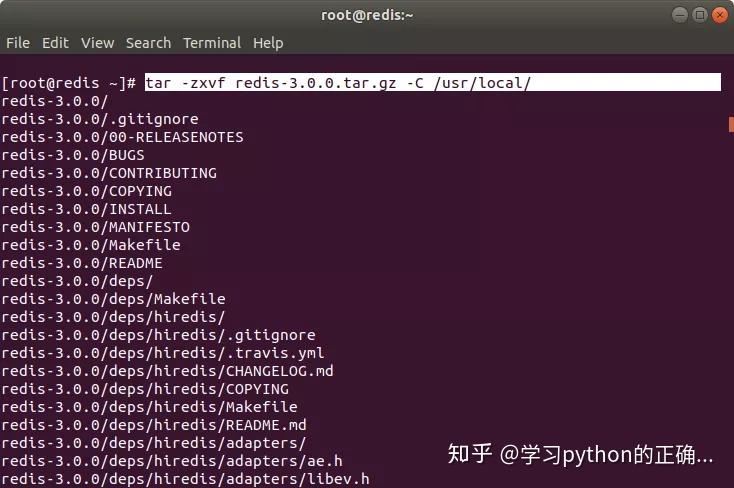
解压完之后
进入

安装一波
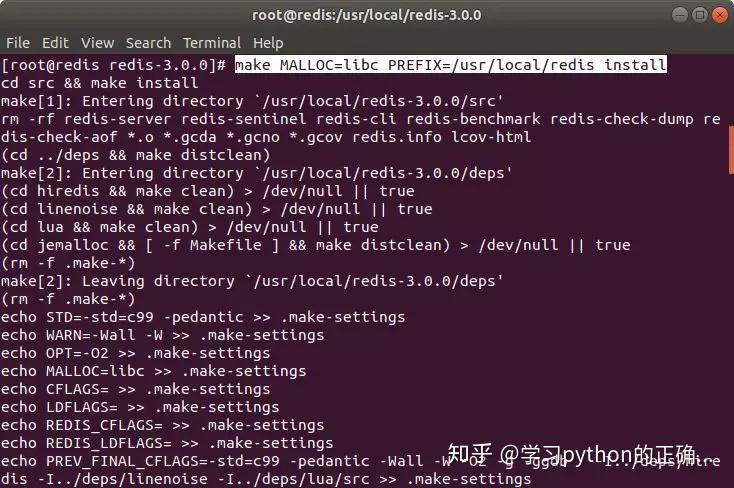
安装完之后可以顺便复制一下 redis 所需的配置文件

接着进入 bin 目录

启动 redis
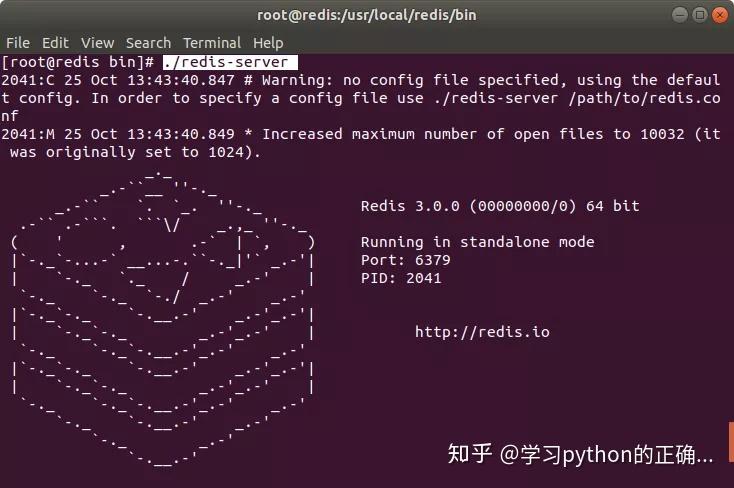
没毛病
使用本地连接一下

恩~连上了

redis 搭建完
接着我们来搭建数据库的服务器
把 MongoDB 给装上
先连接到数据库的服务器上
下载 mongoDB
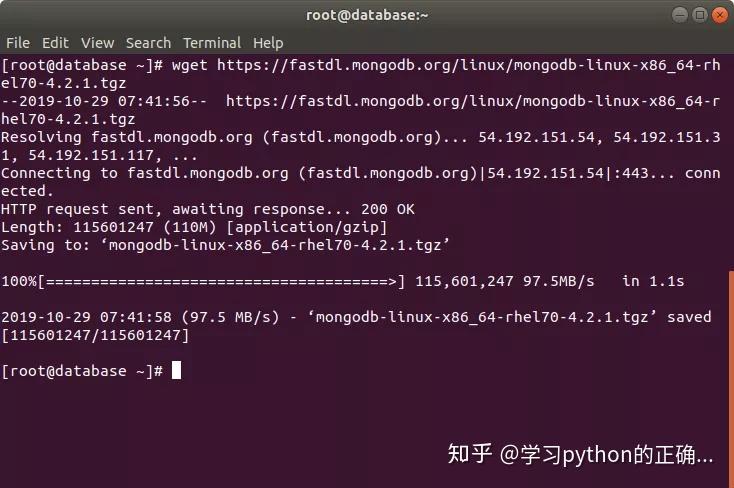
解压一波
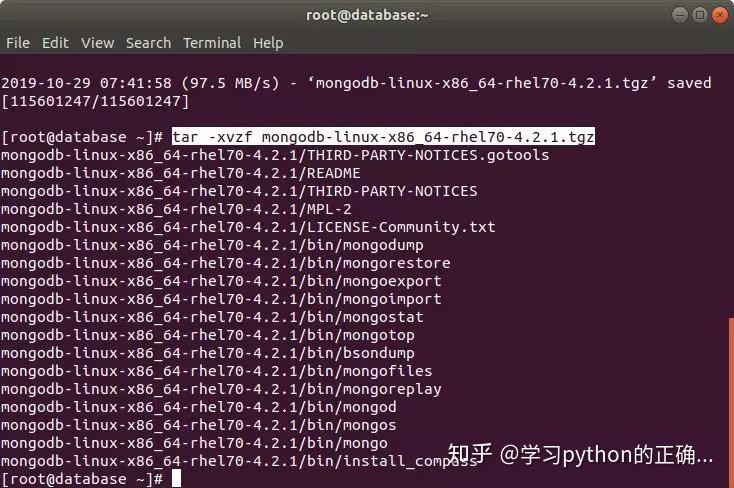
把解压下来的文件夹
轻轻的移动一下位置

创建个 db 文件夹

开启 mongodb
这里顺便把 bind_ip 设置一下
这样才能被远程访问
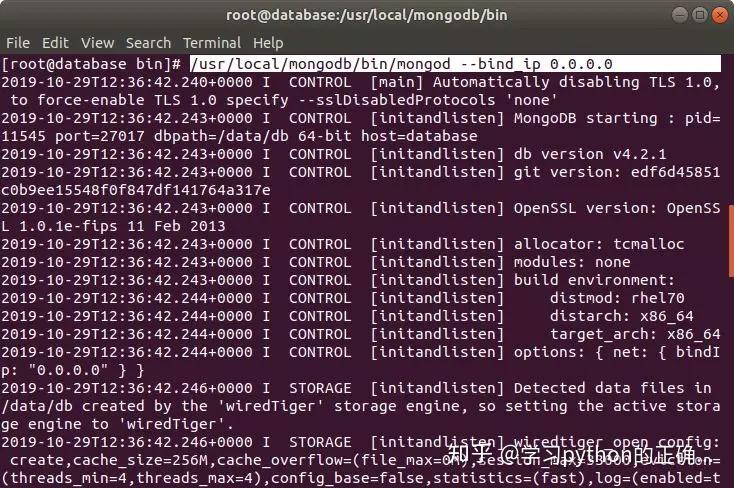
往下拉可以看到
mongoDB 监听的是 27017 端口
说明安装和启动成功
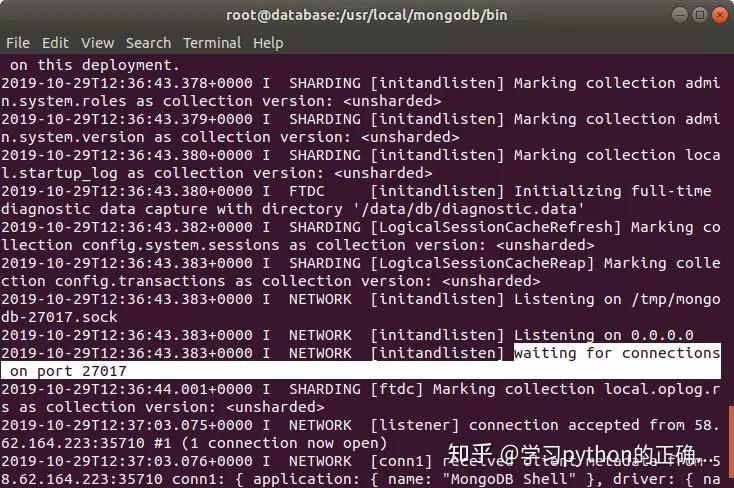
使用本地连接试试
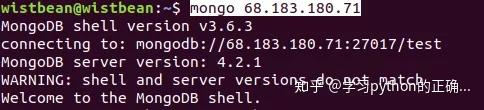
可以可以

接着我们需要在
爬虫服务器安装 Python3 环境
slave-02 和 slave-03 服务器
同上安装 python3
ok
环境搭起来了

回到我们之前写的代码
使用 scrapy 爬取 stackoverflow 上的所有 Python 问答
我们把它改成适用分布式的
将 Pipeline 中的数据库地址配置成
我们创建的 mongodb 数据库地址
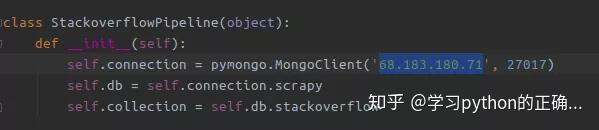
接着在 setting 中配置
redis 调度和去重
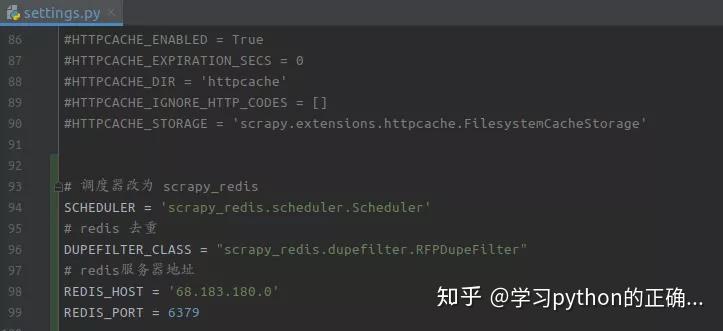
再设置一下延迟访问

搞完了之后
将虚拟环境中的库打包一下

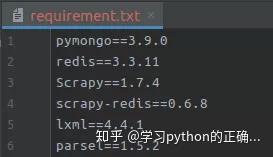
接着把项目
都扔到爬虫服务器上去
连接到爬虫服务器
可以看到刚刚传来的文件
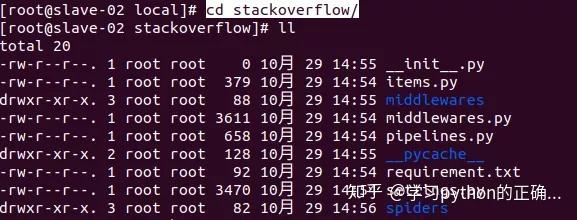
把刚刚在虚拟环境中
生成的第三方库列表
在服务器上一顿安装
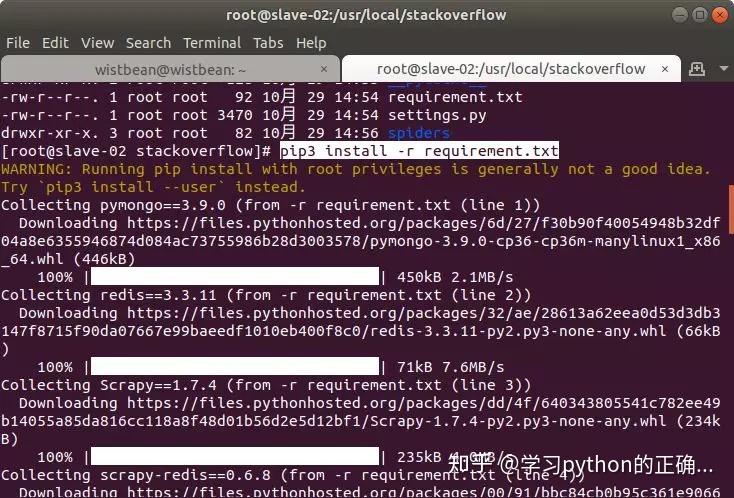
其它两台爬虫服务器
和上面一样安装所需要的库
都安装完之后
就终于可以都 TM 跑起来了
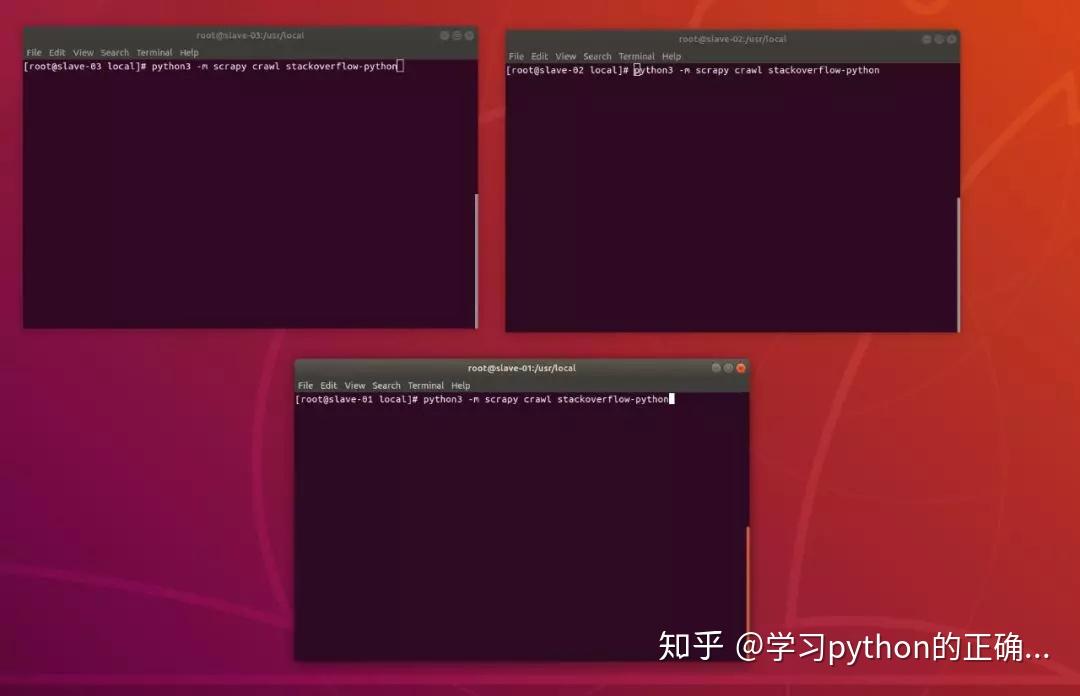
所有的爬虫
都特么给我跑起来
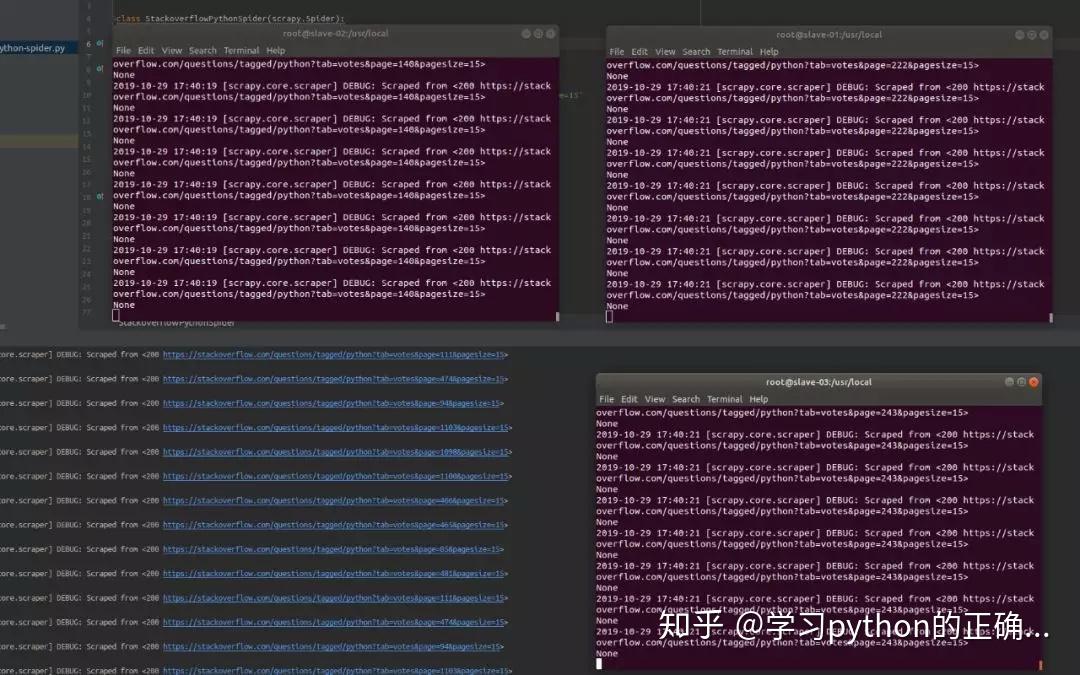
哈哈哈哈哈
4台机器开始一顿爬取

可以看到 mongodb 都监听到了
这几台服务器的连接了
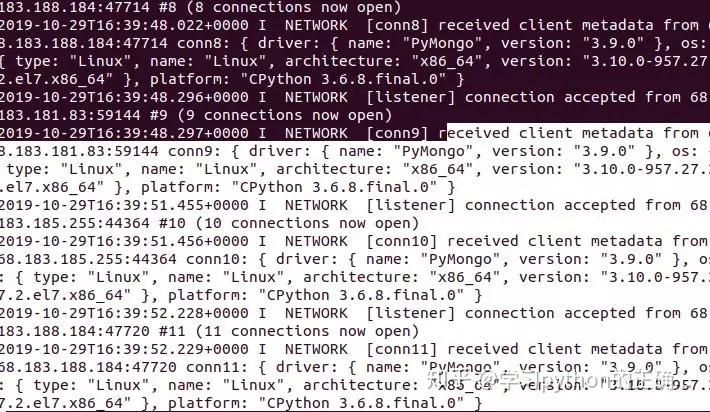
我们连到 redis 看看

可以看到
redis 在调度着请求的消息队列
以及过滤重复的请求
再连接到 mongodb 看看
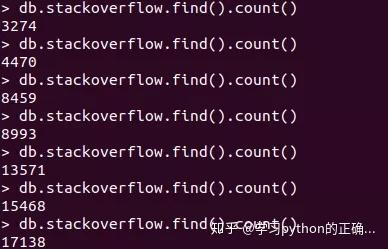
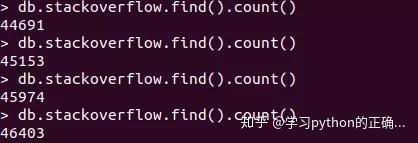
小帅b每隔一小会就查询一下
爬取下来的数量
可以看到
速度还是可以的

ok
以上就是分布式爬虫的
搭建及部署的过程了
当然了
数据库还可以搭建一下集群
数据库之间的连接最好设置账户
进行安全访问等
主要还是让你了解这个过程中
分布式爬虫的搭建和使用
以及体会它的可扩展性和高效性
那么咱们就到这里了
我们下回见,peace

扫一扫
学习 Python 没烦恼

