

一. 架构
- 数据模型 1.1 基础概念 表(table):列式存储,支持高表&宽表(上亿行,上百万列) 行(row):每一行由唯一的行键确定 列族(columnFamily):每一行包含一个或多个列族,是列的集合 列(column):列式存储,列是最基本单位,可能有多个版本的值 时间戳(Timestamp):列的不同版本之间用时间戳区分 单元格(cell):列的每一个版本是一个单元格,是存储的基本单位 HBase最基本的单位是列(column),一列或者多列形成一行(row),若干行数据组成了一张表(table)。听起来是一个非常普通的列式存储数据库,但是,它和传统数据库有很大的不同。
1.2 与传统数据库的区别 a. HBase的每一行由唯一的行键确定 在某种程度上,行键相当于传统数据库的primary key,区别在于,primary key是可选的,而HBase的每张表都必然会有行键。除了行键之外,HBase表不能对列添加索引。HBase是一个<key, value>形式的数据库,行键就是它的key。
b. HBase引入了列族(columnFamily)的概念 HBase是一个列式存储的数据库,因此列的使用是非常灵活的,不必在表定义的时候就定好列名,但是必须在建表的时候定义好列族名字。 一张HBase表存储的列的数量可以是无限的,但是列族的数量最好控制在2-3个(原因在备注中[1]) 列必须属于某个列族,不同列族之间可以有同名列 列族的作用是,将那些数据量和属性相似的列聚集在一起,以便我们给这些列定义一些共同的存储方式属性(e.g. 数据压缩,保存到读缓存中) c. HBase的列值可以有多版本 在HBase表中,行键、列族、列名和时间戳才能唯一确定一个值。每个值是一个单元格(cell),是存储的基本单位。每一行数据的每一列,都可以存储多个值,每个版本的值之间通过时间戳确定,在存储的时候,这些值也按照时间戳逆序排列,保证客户端永远读到最新的数据。但是,每个列族可以存储的最大版本数是确定的,并且是在建表的时候就定义好的。
另外,单元格的时间戳是可以由用户自行指定的,如果不指定,服务器就会将接收到写请求的服务器时间作为单元格的时间戳。通常情况下,最好不要自己指定时间戳,因为客户端总是难以保证,指定的时间戳是按照写顺序递增的。
d. 反范式化 HBase是一个NoSQL(Not-only-SQL)数据库,不提供复杂的查询方式,包括join。另外,相对于MySQL,HBase的可扩展性很好,存储资源要廉价很多。因此,在设计数据库的时候,我们总是倾向于反范式化,以方便后期的数据查询
1.3 数据模型抽象 HBase实际上是按照谷歌的bigtable实现的,而谷歌在bigtable论文的开篇就介绍了bigtable的特点:A Bigtable is a sparse, distributed, persistent multidimensional sorted map。所以HBase在本质上,是一张有序的多维map,数据模型可以抽象成:
<rowKey : columnFamily : qualifier : timestamp, value>
这样的优点是,HBase只存储有值的单元格,对于一张稀疏表来说,可以节省很多存储空间;但是,为每个cell都存储了rowKey, columnFamily, qualifier,因此cf的名字不要太长。
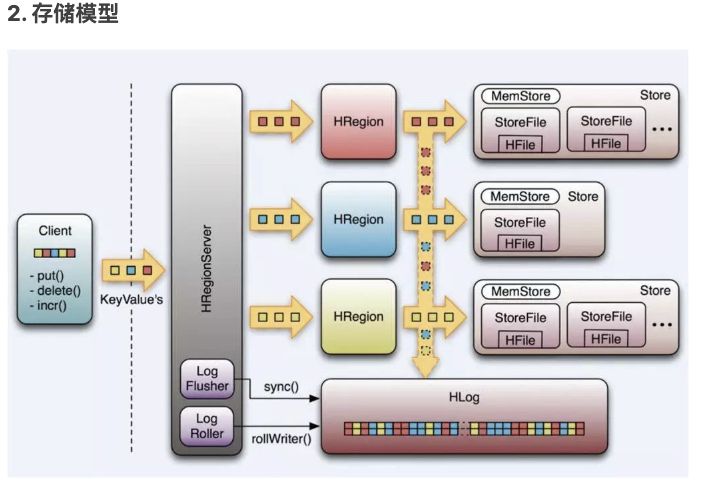
b. HLog:Write-Ahead-Log,写操作先写日志 HLog的作用是,当一台regionServer crash了,可以利用HLog来恢复内存中未持久化到硬盘中的数据。需要注意的是,同一台server上的所有region共用一个HLog实例,因为假如每个region拥有一个独立的HLog,服务器会花费很多时间在磁盘寻道上。
c. MemStore:写缓存,每个store拥有独立的写缓存 在HBase中,所有的写操作全部写到内存中,当写缓存(MemStore)写满,再刷写(flush)到磁盘中[2],形成一个新的文件。这样做的目的,是为了高速响应那些写请求。
d. HFile:磁盘文件 在存储上,HBase完全依赖HDFS,磁盘操作是直接调用HDFS的API(HDFS在维持data locality这一点上足够智能)。另外,之前提过HBase定义列族的一个原因是为了方便存储,事实上,同一列族的数据会被写到同一文件,因为存储特性本来就是按照列族定义的。HBase的数据在底层文件中时以KeyValue键值对的形式存储的,HBase没有数据类型,HFile中存储的是字节,这些字节按字典序排列。
e. 读缓存:同一server上所有region共用 既然HBase有写缓存,相对应的应该有读缓存。与写缓存不同的是,HBase的读缓存是同一server上的所有region共用的。当HBase读取磁盘上某一条数据时,HBase会将整个HFile block[3]读到cache中[4]。因此,当client请求临近的数据时,因为临近数据已经被缓存到内存中,HBase的响应会更快,也就是说,HBase鼓励将那些相似的,会被一起查找的数据存放在一起。另外,当我们在做全表扫描时,为了不刷走读缓存中的热数据,千万记得关闭读缓存的功能。
2.2 行键的索引 a. 行数据查找步骤 hbase:meta表查找,获取数据所在的region id 根据region id,到对应的region server上查找,在server上查找对应记录时,有三种方式 (1) 扫描缓存 (2) 块索引 (3) 布隆过滤器 b. rowKey索引:hbase:meta表 client会首先获取hbase:meta表的位置,再到对应的region server上读取这张表的内容(hbase:meta表其实就是一张HBase表)。读到这张hbase:meta表之后,client会缓存这张表,这张之后的查找就可以复用了。hbase:meta表的内容如下:
| key | value |
| ----------------------------------------------------------------- | ------------------------------------------------------------------------------------|
| | info:regioninfo (serialized HRegionInfo instance for this region) |
| Region key of the format ([table],[region start key],[region id]) | info:server (server:port of the RegionServer containing this region) |
| | info:serverstartcode (start-time of the RegionServer process containing this region)|
因此,通过查找hbase:meta表,client可以得知对应的数据存储在哪台server的那个region上,接下来就要到对应的server上查找相关数据了。
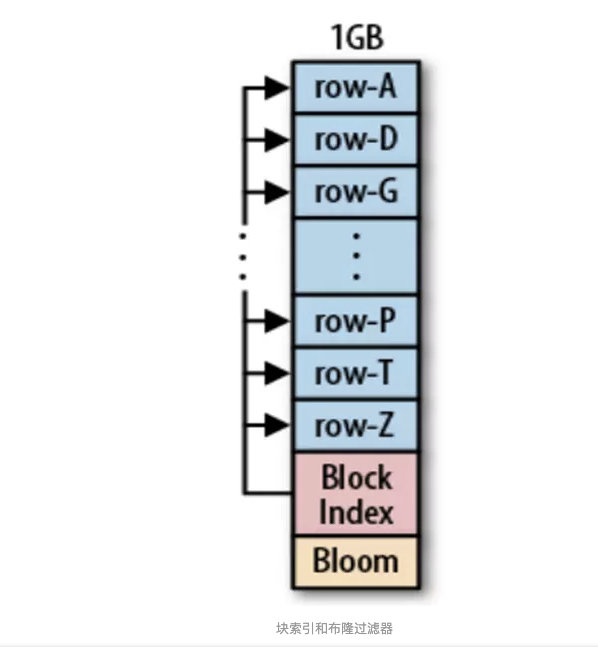
c. region server上的数据查找 当接收到一个读请求,server会初始化一个scanner查找内存中是否有相关数据;一个scanner查找硬盘文件中是否存储了相关数据。查找硬盘文件是一件相当繁重的体力活,为了加快文件查找,HBase借助了两个工具:块索引和布隆过滤器。
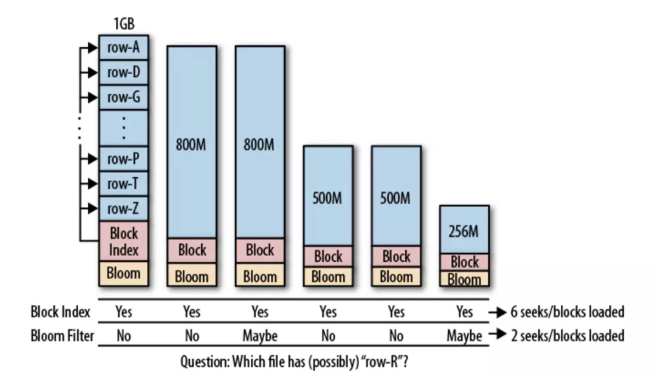
e. rowKey索引:布隆过滤器 虽然块索引帮助减少了需要读到内存中的数据,我们依然需要查找每个文件中的一个块,才能完成磁盘数据查找,而布隆过滤器则可以帮助我们跳过那些显然不包含目标数据的文件。因为布隆过滤器的特点是,能迅速判断一个数据集合中包不包含目标数据,判断结果有两种,不包含和可能包含。如下图所示,布隆过滤器能帮助跳过一些肯定不包含目标数据的文件。
HBase使用场景
2.6.1 适用场景 持久化存储大量数据(TB、PB) 对扩展伸缩性有要求 需要良好的随机读写性能 简单的业务KV查询(不支持复杂的查询比如表关联等) 能够同时处理结构化和非结构化的数据 订单流水、交易记录、需要记录历史版本的数据等
2.6.2 不适用场景 几千、几百万那种还不如使用RDBMS 需要类型列(不过已经可以用Phoniex on HBase解决这个问题) 需要跨行事务,目前HBase只支持单行事务,需要跨行必须依赖第三方服务 SQL查询(不过可以用Phoniex on HBase解决这个问题) 硬件太少,因为HBase依赖服务挺多,比如至少5个HDFS DataNode,1个HDFS NameNode(为了安全还需要个备节点),一个Zookeeper集群,然后还需要HBase自身的各节点 需要表间Join。HBase只适合Scan和Get,虽然Phoenix支持了SQL化使用HBase,但Join性能依然很差。如果非要用HBase做Join,只能再客户端代码做 2.7 行/列存储 2.7.1 简介 HBase是基于列存储的。本节对比下行列两种存储格式。 行/列存储 从上图可以看到,行列存储最大的不同就是表的组织方式不同。
2.7.2 数据压缩 列式存储,意味着该列数据往往类型相同,可以采用某种压缩算法进行统一压缩存储。
比如下面这个例子,用字典表的方式压缩存储字符串:
字典表 查询Customers列为Miller且Material列为Regrigerator的流程如下: 字典表查询
分别去两列的字典表找到对应的数字 将该数字回原表查询,得到行号组成的BitSet,即满足条件的行号位置的bit设为1,其余为0 将两个BitSet相与,得到最终结果BitSet 得到最终行号为6,去字典表拿出结果组装返回即可
