

(一)字符和字符集
字符(character)是各种文字和符号的总称,包括各国家文字,标点符号,图形符号,数字等。字符集(character set)是多个字符的集合,字符集的种类较多,每个字符集包含的字符个数不同,常见的字符集名称:ASCII字符集,GB2312字符集,GB18030,Unicode字符集等。计算机要准确的处理各种字符集文字,就需要进行字符编码,以便计算机能够识别和存储各种文字。字符编码(character encoding)是把字符集中的各种字符通过一定的规则编码计算机能够识别的二进制,以便文本在计算机中存储和通信网络传递。
(二)字符集和字符编码的关系
对于一个字符集来说要正确编码和解码一个字符需要三个关键的元素:字库表,编码字符集(其实就是字符集),字符编码。其中字库表是一个相当于所有可读或者可显示字符的数据库,字库表决定了整个字符集能够表示的所有字符的范围。编码字符集,即用一个编码值code point来表示一个字符在字库表中的位置。字符编码,记录编码字符集和实际存储数值之间的转换关系,一般来说都会直接将code point的值作为编码后的值直接存储。例如在ASCII字符集中A的编码值为65,而编码后A的数值是 01000001,也就是十进制的65的二进制转换结果。字符集和字符编码的关系如图-1所示
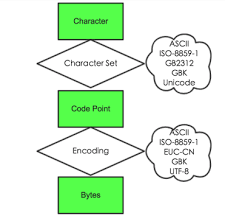
图-1
(三)编码和解码
解码
一串二进制数,使用一种编码方式转换成字符,这个过程我们称为解码。就像解开密码一样,程序员可以选用任意的字符编码方式进行解码,但往往只有一种字符编码方式可以解开密码从而显示出正确的文字,而使用错误的编码方式,就会产生其他不合理的字符,这就是我们通常说的--乱码
编码
一串已经解码后的字符,我们也可以选用任何类型的字符编码重新转换成一串二进制,这个过程就是编码,我们也可以称为加密过程,无论使用哪一种编码方式进行编码,最终都是产生计算机可识别的二进制数,但如果对应的字符集的字库表不包含目标字符,则无法正确的编码,这将导致不可逆的乱码。例如:像ISO-8859-1的字库表中不包含中文,因此哪怕将中文字符使用ISO-8859-1进行编码,再使用ISO-8859-1进行解码,也无法显示出正确的中文字符
乱码就是编码和解码使用的编码方式不一致,或者编码时其字库表中不包含相应字符所导致的结果
(四)常见的字符集和对应的字符编码
常见的字符集有:ASCII字符集,GB2312字符集,BIG5字符集,GB18030字符集,Unicode字符集
ASCII字符集
字符编码:ASCII
编码方式:在计算机存储单元中,一个ASCII码值占一个字节
GB2312字符集
字符编码:GB2312
编码方式:它是用双字节表示的,前面的字节为第一字节,又称“高字节”,后面的为第二字节,“低字节”
BIG5字符集
字符编码:BIG5
编码方式:BIG5 也采用双字节存储方法
Unicode字符集
字符编码:UTF8、UTF16、UTF32
编码方式:
UTF8:下文详解UTF8的编码方式
UTF16: 2 个字节表示一个字符
UTF32:将每一个 unicode 代码点表示为相同值的 32 位整数
(五)UTF8
UTF-8(Unicode Transformation Format)是针对Unicode的一种可变长度字符编码,它可以使用1~4个字节表示一个字符,根据不同的符号而改变字节长度。UTF8是Unicode的实现方式之一
编码方式
UTF-8使用1~4字节为每个字符编码:
- 一个US-ASCIl字符只需1字节编码(Unicode范围由U+0000~U+007F)。
- 带有变音符号的拉丁文、希腊文、西里尔字母、亚美尼亚语、希伯来文、阿拉伯文、叙利亚文等字母则需要2字节编码(Unicode范围由U+0080~U+07FF)。
- 其他语言的字符(包括中日韩文字、东南亚文字、中东文字等)包含了大部分常用字,使用3字节编码。
- 其他极少使用的语言字符使用4字节编码
参考资料
