

前言
本篇就是ES初级知识的最后一篇了,初识Index Template和Aggregation,发现这两块内容实在是相当复杂,在es提高中进行进一步探索。本篇简单了解一些它们是什么
Index Template
什么是Index Template
- Index Template - 帮助设定Mappings和Settings,并按照一定的规则,自动匹配到新创建的索引之上
- 模板仅在一个索引被新创建时,才会产生作用。修改模板不会影响已创建的索引
- 可以设定多个索引模板,这些设置会被“merge”在一起
- 可以指定“order”的数值,控制“merging”的过程
举例
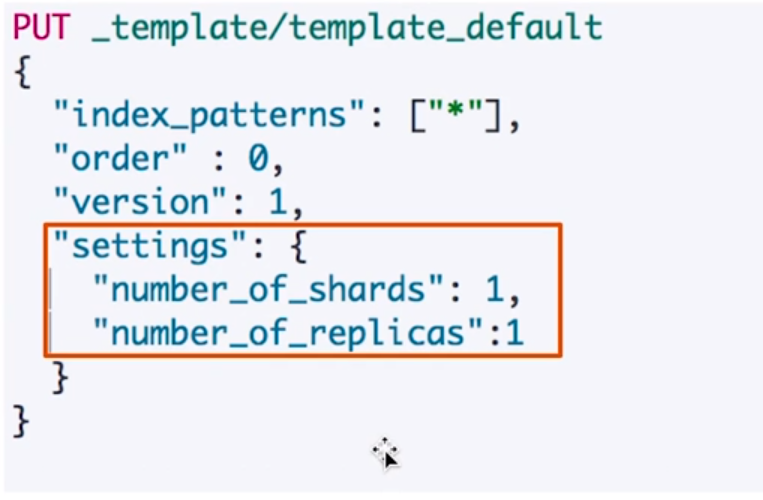
规则:所有索引创建时候,主分片和副本分片都是1
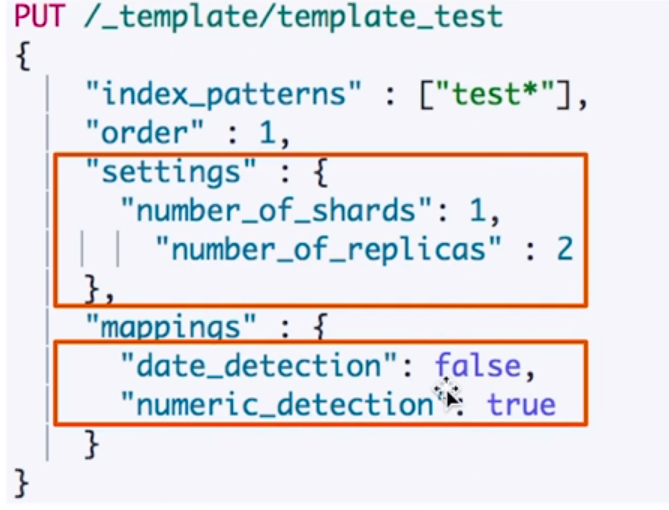
索引以index开头的,就把replica设置成2,
映射转换设置,关闭字符串自动转date,开启字符串自动转数字
工作方式
- 当一个索引被创建时
- 应用Elasticsearch默认的 settings 和 mappings
- 应用order数值低的Index Template中的设定
- 应用order高的Index Template中的设定,之前的设定会被覆盖
- 应用创建索引时,用户所指定的Setting和mapping,并覆盖之前模板的设定
Dynamic Template
- Dynamic Template是定义在某个索引的mapping中
- Template有一个名称
- 匹配规则是一个数组
- 为匹配到字段设置Mapping
简单了解,后续详细扩展
Elasticsearch聚合分析
什么是聚合(Aggregation)
- Elasticsearch除搜索外,还可针对数据进行统计分析,这就是聚合
- 特点:实时性高
- 帮助进行搜索结果的过滤,无需再客户端进行分析逻辑了
- 应用:Kibana可视化报表-聚合分析
- 岗位分布
- 项目框架使用情况
- 薪水分布
- 地理位置分布
- 订单增长情况
- 等等···
- 通过聚合,可得到一个数据的概览,对全套的数据进行分析和总结,而不是寻找单个文档
- 如:客房数量
- 价格区间可预订的不同星级酒店的数量
- 高性能,只要一条语句,就可以从Elasticsearch得到分析结果
集合的分类
Bucket Aggregation- 一些列满足特定条件的文档集合
Metric Aggregation- 一些数据运算(最大最小平均值等),可以对文档字段进行统计分析
Pipeline Aggregation- 对其他的集合结果进行二次聚合
Matrix Aggregation- 支持对多个字段的操作并提供一个结果矩阵
Bucket & Metric
- Bucket - 一组满足条件的文档,类似于sql中的
group by - Metric - 一些系列的统计方法,类似于sql中的
count
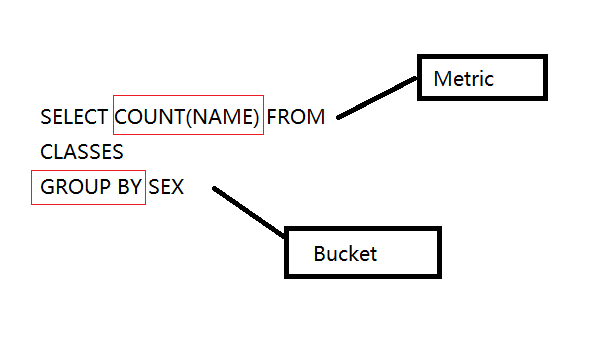
Bucket
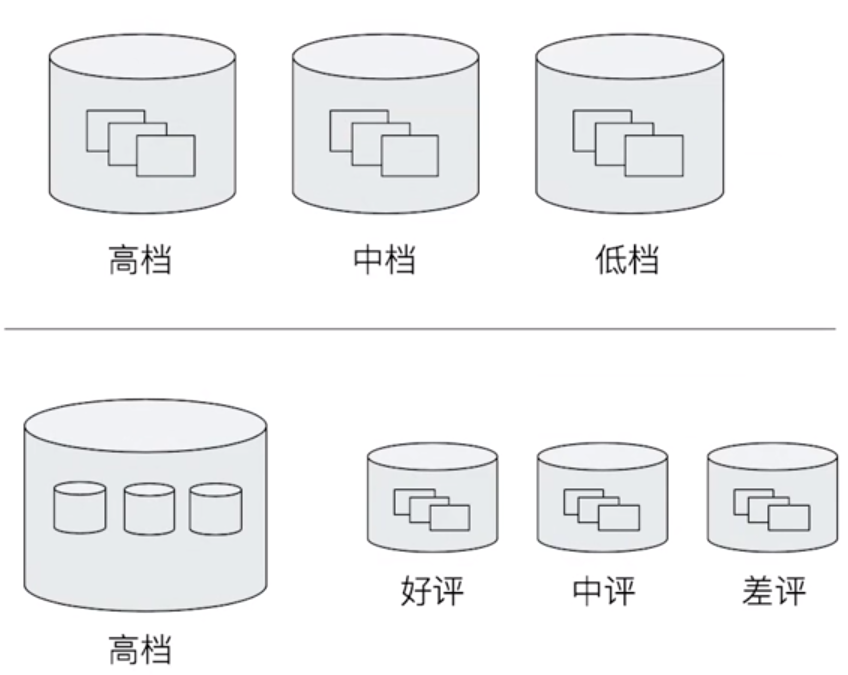
如图:商品可以分为高中低档,而在高档桶中,又可分为好中差类型
- Elasticsearch提供了很多类型的Bucket,可用多种方式划分文档
- Term & Range (时间/年龄/位置)
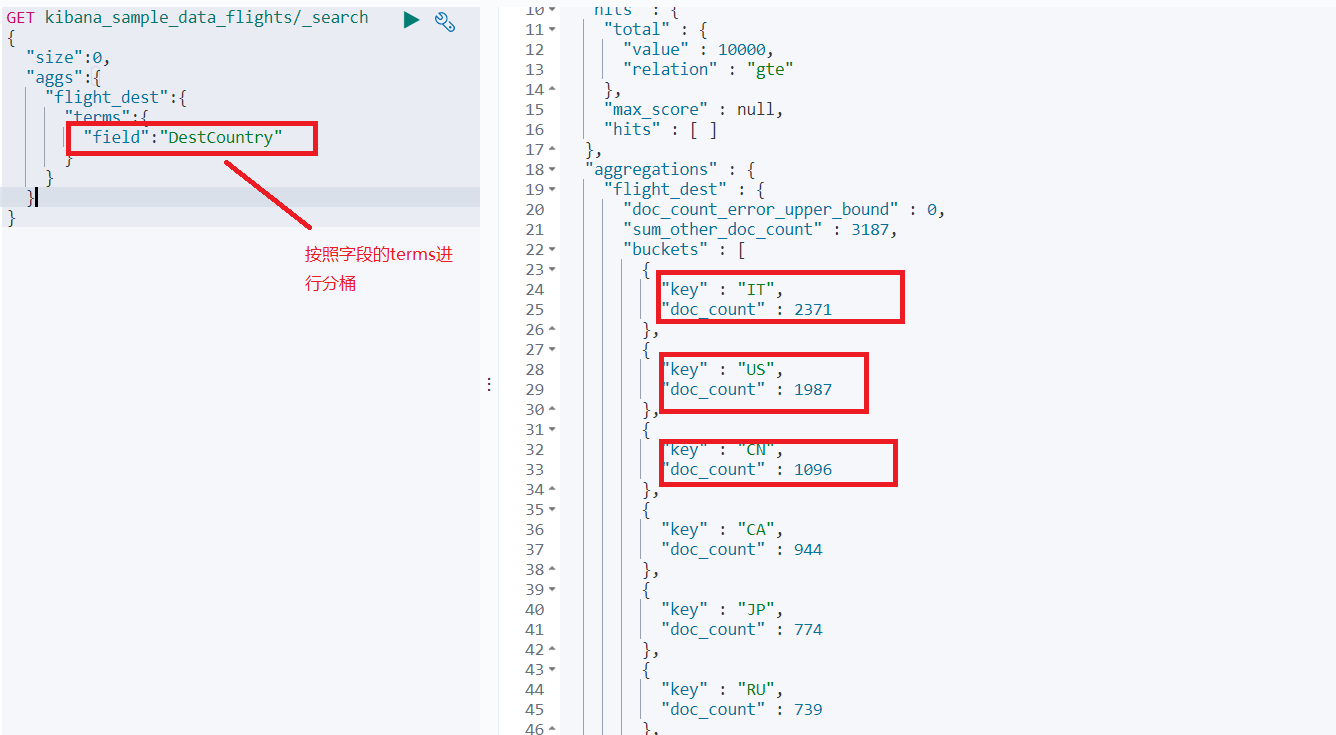
按照不同的目的地分桶,查询得到各个目的地统计结果
Metric
- Metric 基于数据集计算结果,除了支持在字段上进行计算,同样支持在脚本(painless script)产生的结果上进行计算
- 大多是Metric是数学计算,仅输出一个值
- min / max / sum / avg / cardinality
- 部分metric支持输出多个数值
- state(统计值,高低同时输出)
- percentiles(百分位,根据百分位数输出不通知)
- percentile_ranks
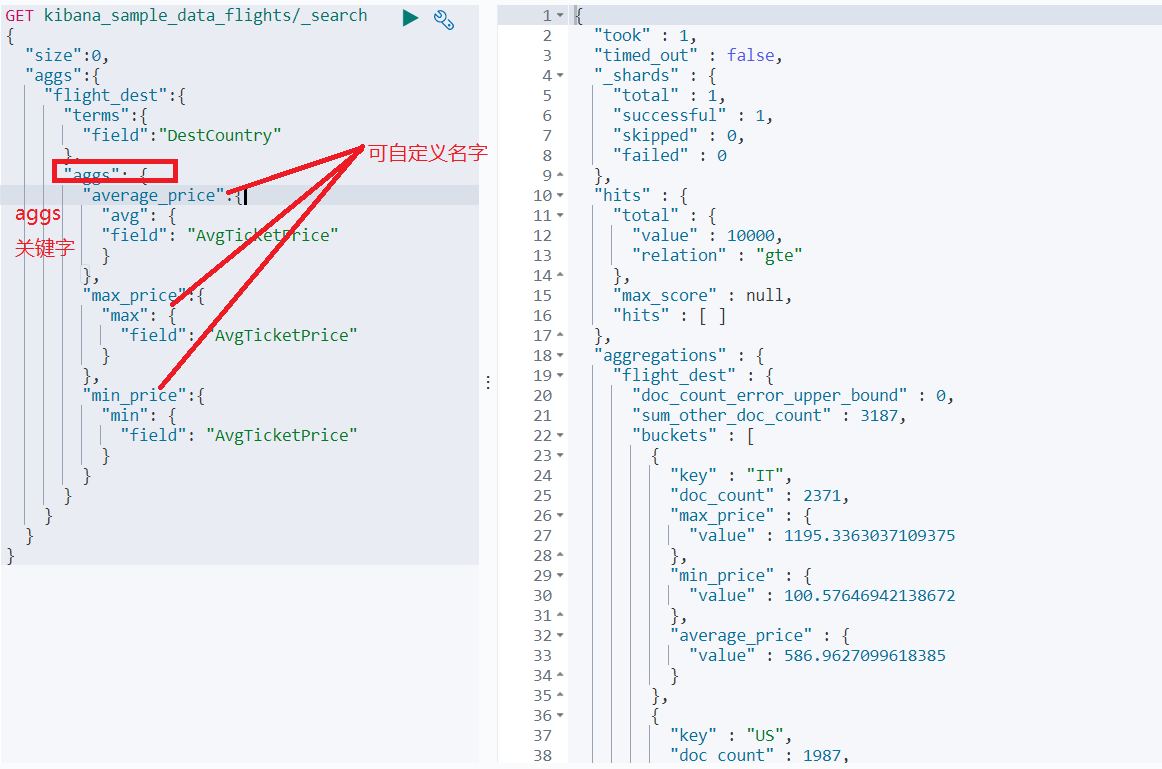
如图,查看航班目的地的统计信息,得到均价,最高最低价格
Matrix
可在多个字段上进行操作,基于请求文档的字段值,生成matrix结果。不同于桶聚合和度量聚合,matrix暂不支持脚本操作。
Pipeline
管道聚合,对其他聚合和相关度量的输出进行聚合。
总结
- Index Template可以定义Mappings和Settings,并自动的应用到新创建的索引之上,需要合理使用Index Template。
- Dynamic Template支持在具体的索引上指定规则,为新增加的字段指定相应的Mappings
- Elasticsearch提供了Bucket/Metric/Pipeline/Matrix四种方式的聚合
