

一些需求中经常要我们实现一个排行榜,数据量少的话可以使用 RDB 数据库排序,数据量大可以自己实现算法或者使用 NoSQL 数据库排序,NoSQL 数据库中最方便的可能就是利用 Redis 的 zset 来实现了。 例如要实现一个玩家成就点数的排行榜:
>zadd r 100 A
"1"
>zadd r 200 B
"1"
>zadd r 200 C
"1"
>zadd r 300 D
"1"
>zrange r 0 -1 withscores
1) "A"
2) "100"
3) "B"
4) "200"
5) "C"
6) "200"
7) "D"
8) "300"
其中 B 和 C 的分数是一样的,这时我们可能想让先达到对应分数的人排在前面,相当于增加了一个排序维度。这时直接用 score 就不能实现了,需要做一些转换,这里分享几个我会用到的方法。
实现方法
假设我们需要一个三个维度的排序,第一维度是具体的数值,第二个维度是一个是否标志位,第三个维度是时间戳。其中氪金的(0否1是)和时间早的排序靠前。
以下是原始数据:
玩家 成就 是否氪金 时间戳
A 100 1 1571819021259
B 200 0 1571819021259
C 200 1 1571819021259
D 400 0 1571819021259
E 200 1 1571810001259
1. 利用 key 排序
如果后两个维度初始化后就不再变化的话,可以利用 Redis 的排序特性,将不变的维度写到 key 里,这样 score 相同时会用 key 来进行排序。
# 这里反转时间戳(9999999999999 - 1571810001259),让时间早的排在前面
>zadd r 100 A-1-8428180978740
"1"
>zadd r 200 B-0-8428180978740
"1"
>zadd r 200 C-1-8428180978740
"1"
>zadd r 400 D-0-8428180978740
"1"
>zadd r 200 E-1-8428189998740
"1"
>zrange r 0 -1 withscores
1) "A-1-8428180978740"
2) "100"
3) "B-0-8428180978740"
4) "200"
5) "C-1-8428180978740"
6) "200"
7) "E-1-8428189998740"
8) "200"
9) "D-0-8428180978740"
10) "400"
以上就是第一种方法了,实现起来非常简单。
score 存储格式
在介绍下两种方法前先来看看 zset 的 score 是怎么存储的,能保留多少精度,直接看跳表 node 的结构。
/*
* 跳跃表节点
*/
typedef struct zskiplistNode {
// 成员对象
robj *obj;
// 分值
double score;
// 后退指针
struct zskiplistNode *backward;
// 层
struct zskiplistLevel {
// 前进指针
struct zskiplistNode *forward;
// 跨度
unsigned int span;
} level[];
} zskiplistNode;
我们可以看到 score 是用 double 存储的,它是一个 IEEE 754 标准的 double 浮点数。(IEEE 754 标准的详细存储规则可以搜索其他文章,这里重点分析保留的精度)

-
S:符号位,第一段,占1位,0表示正数,1表示负数。
-
Exp:指数字,第二段,占11位,移码方式表示正负数,排除全0和全1表示零和无穷大的特殊情况,指数部分是−1022~+1023加上1023,指数值的大小从1~2046
-
Fraction:有效数字,占52位,定点数,小数点放在尾数最前面
实际数字 = (-1)^S * Fraction * 2^Exp (二进制计算)
double 存储的有效数据是第三段的52位,超出会损失精度,由于标准规定小数点是在有效数字最前面,所以实际可以存储 53 位数字。比如有个数字是 111___(53个1),有效数字位存储的是 .11___(52个1),计算时会在个位补1,得到1.11___(53个1),最大值为 2^53 = 9007199254740991,大概 log2^53 = 15.95 位。
可以看到只要保证有效数字小于等于9007199254740991就不会损失精度。
好了,现在有了理论基础,接下来看看我们可以怎么实现。
2. 二进制分段
第二种方法,可以利用二进制 64 位 long 分段存储各个维度。
首先时间戳如果全存储就太长了,可以通过一些计算缩小一些,先忽略毫秒,然后和一个大数计算差值。
int MAX_SECOND = 1861891200; // 2029.1.1 0:0:0
int sts = (MAX_SECOND - (int)(ts / 1000))
这样时间就缩小到了300000000以内。
接下来进行划分,首位标志位不用,剩下63位,然后我划分高33位存分数,1位存标志位,最后29位存时间戳,存储结构是这样的:
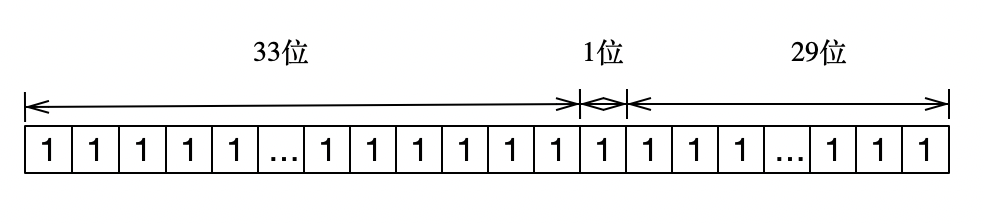
如果要不损失精度,第一段可存储位数 = 53 - 1 - 29 = 23。
第一段最大值 = 2^33 = 8589934591,不损失精度 = 2^23 = 8388607。
第三段最大值 = 2^29 = 536870911。
- 使用时可以适当缩短第三段时间戳的长度,或者不追求时间戳一定精确的话,第一段分数可以超出不损失精度的长度,也只会损失一点时间戳的精度而已。
然后就可以用下面的方法计算 score 了,因为是二进制,可以全用位运算。
int size1 = 33;
int size2 = 1;
int size3 = 29;
long d1Max = maxBySize(size1);
long d2Max = maxBySize(size2);
long d3Max = maxBySize(size3);
// 计算 score
public long genScore(long d1, long d2, long d3) {
return ((d1 & d1Max) << (size2 + size3)) | ((d2 & d2Max) << size3) | (d3 & d3Max);
}
// 计算增加 value 值
public void incValue(long d1) {
return ((d1 & d1Max) << (size2 + size3)) | ((0 & d2Max) << size3) | (0 & d3Max);
}
// 根据二进制长度计算最大值
private long maxBySize(int len) {
long r = 0;
while (len-- > 0) {
r = ((r << 1) | 1);
}
return r;
}
增加高位分数的话直接把低维度设为0,计算出分数后调用 ZINCRBY 就行了。
改变低位维度值的话就不能调用 ZINCRBY 了,需要调用ZADD,我们用自旋加 CAS 更新,防止覆盖掉新更新的值。
/**
* 设置维度值
*
* @param key zset key
* @param value zset value
* @param d2 第二位
* @param d3 第三位
* @return
*/
public boolean setD(String key, String value, Long d2, Long d3) {
long start = System.currentTimeMillis();
Long oldScore;
long score;
byte[] originBytes;
do {
if ((System.currentTimeMillis() - start) > 2000) {
return false;
}
long d1 = 0;
originBytes = zscoreBytes(key, value);
oldScore = convertZscore(originBytes);
if (originBytes != null) {
// 根据 score 获取原始值
d1 = getD1ByScore(oldScore);
}
// 如果不设置新值就获取原始值
if (d2 == null) {
// 根据 score 获取原始值
d2 = getD2ByScore(oldScore);
}
// 如果不设置新值就获取原始值
if (d3 == null) {
// 根据 score 获取原始值
d3 = getD3ByScore(oldScore);
}
// 生成新值
score = genScore(d1, d2, d3);
} while (!compareAndSetDimension(key, value, originBytes, score));
return true;
}
Long SUCCESS = 1L;
String script = "if (((not (redis.call('zscore', KEYS[1], ARGV[1]))) and (ARGV[2] == '')) " +
"or redis.call('zscore', KEYS[1], ARGV[1]) == ARGV[2]) " +
" then redis.call('zadd',KEYS[1],ARGV[3],ARGV[1]) return 1 else return 0 end";
// CAS 设置值
private boolean compareAndSetDimension(String setKey, String key, byte[] oldScore, long newScore) {
Long result = redisTemplate.execute((RedisCallback<Long>) connection -> {
try {
return connection.eval(script.getBytes(), ReturnType.fromJavaType(Long.class), 1, setKey.getBytes(),
key.getBytes(), oldScore, om.writeValueAsBytes(newScore));
} catch (JsonProcessingException e) {
throw new RuntimeException(e);
}
});
return SUCCESS.equals(result);
}
// 获取原始值
public byte[] zscoreBytes(String key, String value) {
String script = "return redis.call('zscore', KEYS[1], ARGV[1])";
return redisTemplate.execute((RedisCallback<byte[]>) connection -> connection.eval(script.getBytes(),
ReturnType.fromJavaType(String.class),
1, key.getBytes(), value.getBytes()));
}
这里初始 score 值获取使用的是 zscoreBytes() 而不是redisTemplate.opsForZSet().score()是为了防止损失精度,这个方法返回的 score 值其实是可能损失精度的,我们看源码分析下:
直接进到最底层的执行方法 zscore
// class RedisCommandBuilder
Command<K, V, Double> zscore(K key, V member) {
notNullKey(key);
return createCommand(ZSCORE, new DoubleOutput<>(codec), key, member);
}
DoubleOutput 将 Redis 的返回值转成 Double
// 将 Redis 返回值转成 Double
public class DoubleOutput<K, V> extends CommandOutput<K, V, Double> {
public DoubleOutput(RedisCodec<K, V> codec) {
super(codec, null);
}
// 方法参数 bytes 就是 Redis 返回的原始值了,是个字符串
@Override
public void set(ByteBuffer bytes) {
output = (bytes == null) ? null : parseDouble(decodeAscii(bytes));
}
}
Redis 原始的返回值其实是个类似 1.3094266712875436e+18 的字符串,DoubleOutput 在转换成 Double 的时候有可能会损失精度,用 BigDecimal 转的话是不会丢精度的。
String a = "1.3094266712875436e+18";
long value = new BigDecimal(a).longValue();
所以要不损失精度的话,可以修改下原始方法重新打个包或者用 lua 取出来原始的字符串再转成自己需要的值。
最后利用 genScore 方法就可以生成score值并排序了
# genScore(100, 1, 290072179)
>zadd r 108201125491 A
"1"
# genScore(200, 0, 290072179)
>zadd r 215038436979 B
"1"
# genScore(200, 1, 290072179)
>zadd r 215575307891 C
"1"
# genScore(400, 0, 290072179)
>zadd r 429786801779 D
"1"
# genScore(200, 1, 290081199)
>zadd r 215575316911 E
"1"
>zrange r 0 -1 withscores
1) "A"
2) "108201125491"
3) "B"
4) "215038436979"
5) "C"
6) "215575307891"
7) "E"
8) "215575316911"
9) "D"
10) "429786801779"
3. 直接拆分 double
可以用二进制拆分当然也可以直接拆分十进制数,为了方便,还可以用小数划分维度,比如将分数放在整数位,标志位和时间戳放在小数位。
A 100.1290072179
B 200.0290072179
C 200.1290072179
D 400.0290072179
E 200.1290081199
不过这样不丢精度存储的分数比二进制拆分小。
原理和二进制拆分一样,就不赘述了。
总结
数据量不大的情况下直接使用 RDB 就可以了,比较方便。用 Redis 的时候,一级以外的维度不变的情况下可以直接用 key 排序,比较简单,如果维度会更新,可以使用拆分二进制或十进制的方法存储,二进制的优点是存储的数比较大,而且可以用位运算,十进制的优点是计算简单,可读性比较好。各个维度的长度还可以做成配置项,这样就可以满足不同的业务需求了。
如果有发现错误或者有别的方法欢迎留言交流
同时欢迎关注我的公众号~

