1.Spark Streaming的特点
1.使用方便

2.容错能力

3.火花整合

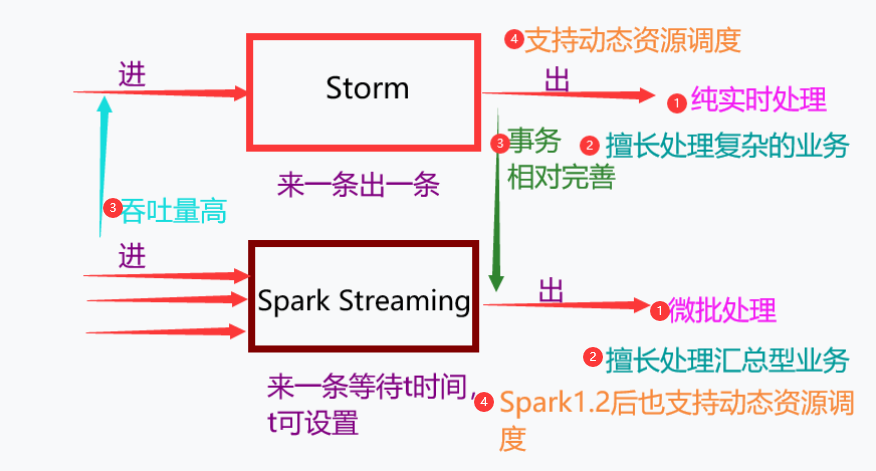
2.Storm 和 Spark Streaming 的区别
3.Spark Streaming初始
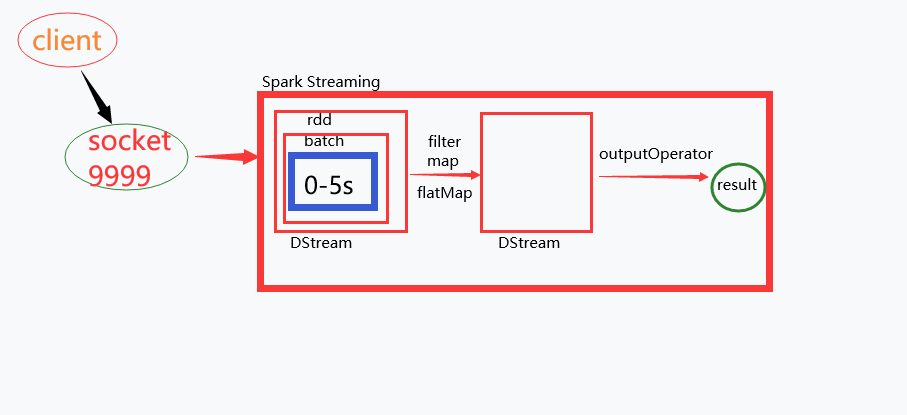
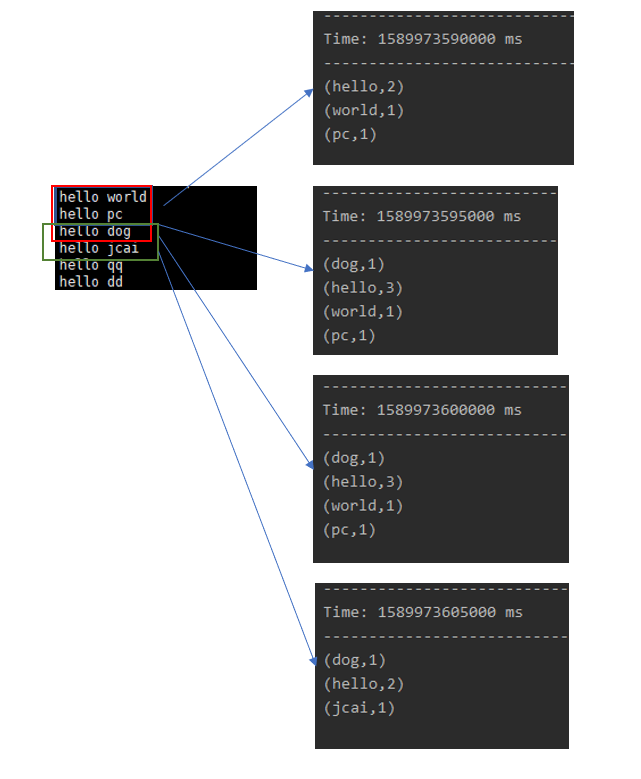
2.Spark Streaming处理数据时,首先启动一个job,这个job使用一个task来一直接收数据,将一段时间内接收到的数据封装在一个batch中,batch没有分布式计算特性,被封装到一个RDD中,这个RDD又被封装在DStream中,生成DStream之后,SparkStreaming启动job处理这个DStream,Spark Streaming底层操作就是DStream,DStream有自己的Transformation算子,懒执行,需要outputOperator类算子触发执行。
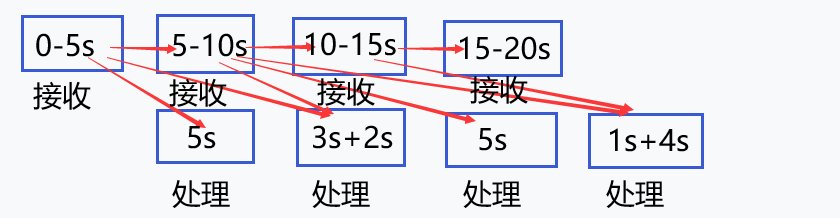
接收数据的一段时间可以由我们来控制,叫做batchInterval
假设batchInterval=5s,SparkStreaming处理这个批次数据的时间是3s

假设batchInterval=5s,SparkStreaming处理这个批次数据的时间是8s
4.用Spark Streaming写wordcount
1.添加Spark Streaming依赖
<!-- https://mvnrepository.com/artifact/org.apache.spark/spark-streaming -->
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-streaming_2.12</artifactId>
<version>${spark.version}</version>
<!--<scope>provided</scope>-->
</dependency>
【注】:如果添加依赖正常但是导入时还是不行,就把.idea删掉,再Invalidate Caches / Restart,按提示重新设置
2.写代码
package com.jcai.spark.scala
import org.apache.spark.storage.StorageLevel
import org.apache.spark.streaming.dstream.DStream
import org.apache.spark.{SparkConf, SparkContext}
import org.apache.spark.streaming.{Seconds, StreamingContext, Time}
object SparkStreamingTest {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setMaster("local[2]").setAppName("test")
val ssc = new StreamingContext(conf, Seconds(5))
val lines = ssc.socketTextStream("ht-1", 9999, StorageLevel.MEMORY_AND_DISK_SER)
val words: DStream[String] = lines.flatMap(_.split(" "))
val wordsAndOne: DStream[(String, Int)] = words.map((_, 1))
val reduce: DStream[(String, Int)] = wordsAndOne.reduceByKey(_ + _)
reduce.print()
ssc.start()
ssc.awaitTermination()//等待被终结
ssc.stop()//调用不到
}
}
3.启动一台虚拟机

4.运行



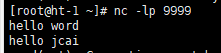
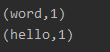

5.拓展
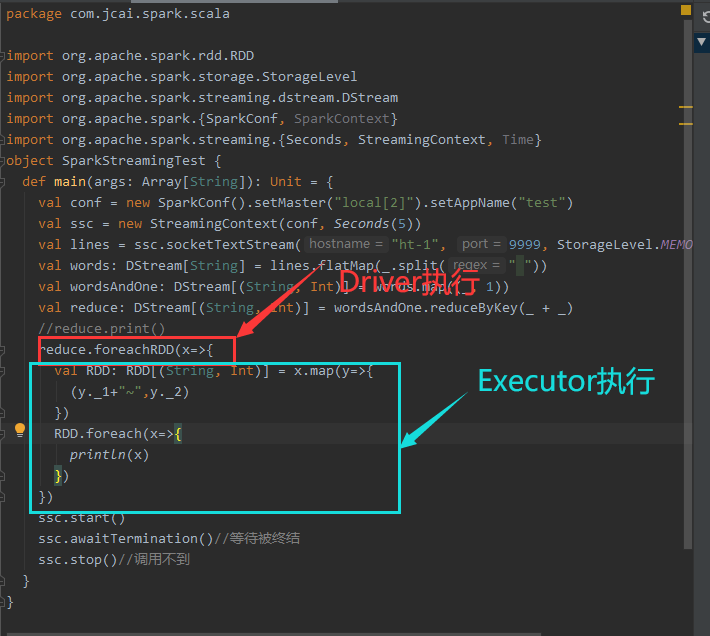
1.使用foreachRDD拿到DStream中的RDD
package com.jcai.spark.scala
import org.apache.spark.rdd.RDD
import org.apache.spark.storage.StorageLevel
import org.apache.spark.streaming.dstream.DStream
import org.apache.spark.{SparkConf, SparkContext}
import org.apache.spark.streaming.{Seconds, StreamingContext, Time}
object SparkStreamingTest {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setMaster("local[2]").setAppName("test")
val ssc = new StreamingContext(conf, Seconds(5))
val lines = ssc.socketTextStream("ht-1", 9999, StorageLevel.MEMORY_AND_DISK_SER)
val words: DStream[String] = lines.flatMap(_.split(" "))
val wordsAndOne: DStream[(String, Int)] = words.map((_, 1))
val reduce: DStream[(String, Int)] = wordsAndOne.reduceByKey(_ + _)
//reduce.print()
reduce.foreachRDD(x=>{
val RDD: RDD[(String, Int)] = x.map(y=>{
(y._1+"~",y._2)
})
RDD.foreach(x=>{
println(x)
})
})
ssc.start()
ssc.awaitTermination()//等待被终结
ssc.stop()//调用不到
}
}
虚拟机:
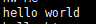
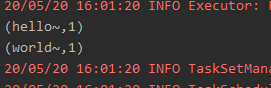
2)
2.updateStateByKey的使用
package com.jcai.spark.scala
import org.apache.spark.{SparkConf, SparkContext}
import org.apache.spark.storage.StorageLevel
import org.apache.spark.streaming.{Seconds, StreamingContext}
import org.apache.spark.streaming.dstream.DStream
object UpdateStateByKeyTest {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setMaster("local[2]").setAppName("test")
val ssc = new StreamingContext(conf, Seconds(5))
ssc.checkpoint("./checkpoint")
val addFunc = (currValues: Seq[Int], prevValueState: Option[Int]) => {
//通过Spark内部的reduceByKey按key规约。然后这里传入某key当前批次的Seq/List,再计算当前批次的总和
val currentCount = currValues.sum
// 已累加的值
val previousCount = prevValueState.getOrElse(0)
// 返回累加后的结果。是一个Option[Int]类型
Some(currentCount + previousCount)
}
val lines = ssc.socketTextStream("ht-1", 9999, StorageLevel.MEMORY_AND_DISK_SER)
val words: DStream[String] = lines.flatMap(_.split(" "))
val wordsAndOne: DStream[(String, Int)] = words.map((_, 1))
val counts = wordsAndOne.updateStateByKey[Int](addFunc)
counts.print()
ssc.start()
ssc.awaitTermination()//等待被终结
ssc.stop()//调用不到
}
}
虚拟机:
2)如果batchInterval小于10s,那么10s会将内存中的数据写入到磁盘一份,如果batchInterval大于10s,那么就以batchInterval为准,防止频繁的写HDFS
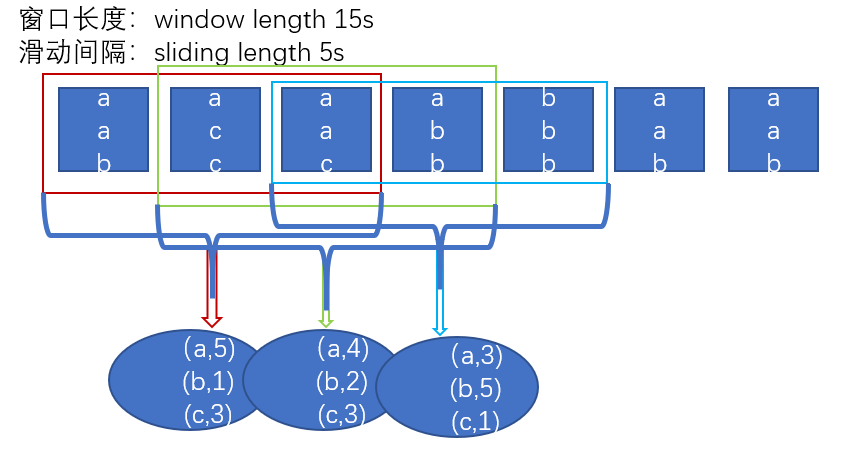
3.reduceByKeyAndWindow的使用
package com.jcai.spark.scala
import org.apache.spark.SparkConf
import org.apache.spark.storage.StorageLevel
import org.apache.spark.streaming.{Seconds, StreamingContext}
import org.apache.spark.streaming.dstream.DStream
object reduceByKeyAndWindowTest {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setMaster("local[2]").setAppName("test")
val ssc = new StreamingContext(conf, Seconds(5))
ssc.sparkContext.setLogLevel("WARN")
val lines = ssc.socketTextStream("ht-1", 9999, StorageLevel.MEMORY_AND_DISK_SER)
val words: DStream[String] = lines.flatMap(_.split(" "))
val wordsAndOne: DStream[(String, Int)] = words.map((_, 1))
val res: DStream[(String, Int)] = wordsAndOne.reduceByKeyAndWindow((v1:Int, v2:Int) => {v1 + v2},Seconds(15),Seconds(5))
res.print()
ssc.start()
ssc.awaitTermination()//等待被终结
ssc.stop()//调用不到
}
}
4.reduceByKeyAndWindow的优化
/**
* 滑动窗口的优化
*/
/**
* 窗口操作优化的机制
* 比如说我们还是每隔五秒查看一下前十五秒数据,我们可以加上新进来的批次,再减去出去的批次,防止任务堆积
* 用优化机制必须设置checkpoint,不设置会报错
* 第一个参数是先加上新来的批次
* 第二个参数是减去出去的批次
* 第三个参数是窗口长度
* 第四个参数是滑动间隔
*/
ssc.checkpoint("./checkpoint1")
val res1: DStream[(String, Int)] = wordsAndOne.reduceByKeyAndWindow(
(v1: Int, v2: Int) => {v1 + v2},
(v1: Int, v2: Int) => {v1 - v2},
Seconds(15),
Seconds(15)
)
res1.print()
5.Transform的使用
package com.jcai.spark.scala
import org.apache.spark.SparkConf
import org.apache.spark.streaming.{Seconds, StreamingContext}
import org.apache.spark.streaming.dstream.{ ReceiverInputDStream}
object StreamingTransformTest {
def main(args: Array[String]): Unit = {
val sparkconf = new SparkConf().setMaster("local[2]").setAppName("test")
val ssc = new StreamingContext(sparkconf,Seconds(5))
/**
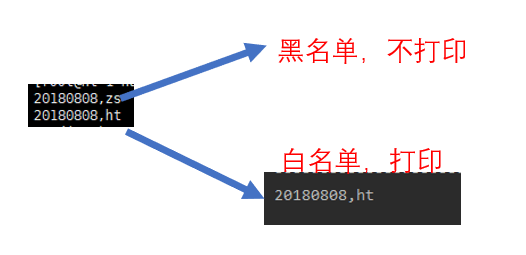
* 构建黑名单(要过滤的数据)
*/
val blacks = List("zs", "ls") // 一般这条在数据库中,用 read 读进来即可
val blacksRDD = ssc.sparkContext.parallelize(blacks)//转成RDD
.map(x => (x, true))
//将这个元素 x 重新定位为一个新字段 (x,true)
//(("zs","true"),("ls","true"))
val lines: ReceiverInputDStream[String] = ssc.socketTextStream("ht-1", 9999)
//20180808,zs 原来的格式
//zs,20180808,zs 处理后的格式
//取index=1的元素,然后在跟上它自身
val clicklogs = lines.map(x => (x.split(",")(1), x))
.transform(rdd => {
//blacksRDD进行map操作后它是RDD格式,此处的lines进行map操作后,它是DStream[U]格式,
//所以此处,要将DStream和RDD进行联合,就要使用transform算子,
//通过将RDD-to-RDD函数应用于源DStream的每个RDD来返回新的DStream。
//这可以用于在DStream上执行任意RDD操作。
rdd.leftOuterJoin(blacksRDD)
//进行表的左外连接 leftOuterJoin
//
// 端口传进来的数据,经过处理后
// zs,20180808,zs
// ls,20180808,ls
// ww,20180808,ww
//
// 黑名单中的数据
// (("zs","true"),("ls","true"))
//
//进行关联后的数据
// (zs:[<20180808,zs>,<true>]) x
// (ls:[<20180808,ls>,<true>]) x
// (ww:[<20180808,ww>,<false>]) ==> tuple 1
.filter(x => x._2._2.getOrElse(false) != true)
// 过滤(zs: [<20180808,zs> ,<true>])中,第二个元素的中的第二个元素,判断是否等于true,如果不为true,则返回false,
// 此处运行后,就只剩下为false的元素了 (ww:[<20180808,ww>,<false>]) ,只有这一条了
.map(x => x._2._1)
//取(zs,[<20180808,zs>,<true>])中第二个元素的第一个元素 (tuple的使用)
})
clicklogs.print() //在控制台打印信息 (这块结果应该是有问题的,它只显示最后一个), 应该在 filter或map这块,它是有问题的, 感觉问题在 map, 对元组的掌握,还有待提高
ssc.start()
ssc.awaitTermination()
}
}