

ZooKeeper version: 3.6.0
ZooKeeper 的启动
ZooKeeper 是如何启动的?!!这个问题要从哪里找答案呢?
1. zkServer.sh
我们启动它时,是怎么跑的? 让我想想,哦,对了
./zkServer.sh start
是的了,就是这样!
ok,那就简单了,我们先来看下这个 zkServer.sh 文件
case $1 in
start)
# ...
nohup "$JAVA" $ZOO_DATADIR_AUTOCREATE "-Dzookeeper.log.dir=${ZOO_LOG_DIR}" \
"-Dzookeeper.log.file=${ZOO_LOG_FILE}" "-Dzookeeper.root.logger=${ZOO_LOG4J_PROP}" \
-XX:+HeapDumpOnOutOfMemoryError -XX:OnOutOfMemoryError='kill -9 %p' \
-cp "$CLASSPATH" $JVMFLAGS $ZOOMAIN "$ZOOCFG" > "$_ZOO_DAEMON_OUT" 2>&1 < /dev/null &
# ...
;;
esac
我们看到,当我们执行 zkServer.sh start 的时候,其实跑到了这里,而这里,会以 java cp 的方式启用 $ZOOMAIN 这个主类。往上看
if [ "x$JMXDISABLE" = "x" ] || [ "$JMXDISABLE" = 'false' ]
then
echo "ZooKeeper JMX enabled by default" >&2
if [ "x$JMXPORT" = "x" ]
then
# for some reason these two options are necessary on jdk6 on Ubuntu
# accord to the docs they are not necessary, but otw jconsole cannot
# do a local attach
ZOOMAIN="-Dcom.sun.management.jmxremote -Dcom.sun.management.jmxremote.local.only=$JMXLOCALONLY org.apache.zookeeper.server.quorum.QuorumPeerMain"
else
# ...
ZOOMAIN="-Dcom.sun.management.jmxremote -Dcom.sun.management.jmxremote.port=$JMXPORT -Dcom.sun.management.jmxremote.authenticate=$JMXAUTH -Dcom.sun.management.jmxremote.ssl=$JMXSSL -Dzookeeper.jmx.log4j.disable=$JMXLOG4J org.apache.zookeeper.server.quorum.QuorumPeerMain"
fi
else
echo "JMX disabled by user request" >&2
ZOOMAIN="org.apache.zookeeper.server.quorum.QuorumPeerMain"
fi
可以看到,这里虽然区分了几种情况,但都是往 ZOOMAIN 中添加启动变量,但最终,这个主类,它还是它:
org.apache.zookeeper.server.quorum.QuorumPeerMain
于是我们知道了 zk 的启动类。
2. QuorumPeerMain
下面我们把 zk 的源码拉下来,通过这个主类一步步往里面看。源码 clone 看 GitHub
下载完成后(需要依次 mvn clean install),我们找到这个类,可以看到:
通过 main 方法 调用 initializeAndRun , 这个方法先读取 config ,然后启动一个类似清洁工的线程,之后根据传入的参数,来判断是启用 ensemble 模式还是 standalone 模式。
这里我们看 ensemble 模式。
org.apache.zookeeper.server.quorum.QuorumPeerMain#runFromConfig
-
这个方法,初始化了一个十分重要的对象,即 QuorumPeer !! zk 的核心类之一。稍后我们会说到它。我们看这个方法还干了些什么了不得的事情。
-
之前
zoo.cfg里设置的什么 tickTime, initLimit,syncLimit 啥的,都会在这个方法里完成初始化。 -
选举算法(你随便找下,就能看到,现在 zk 只支持 3,也就是 FastLeaderElection 算法),myid,database 等的初始化
-
QuorumVerifier 类,维护着 ensemble 内所有初始化时的所有 server 信息,之后说选举是不是过半了,就是通过它来做判断的
-
ServerCnxnFactory 类,负责 server 到 client 的通信,主要有 NIO 和 Netty 两种实现,默认为 NIO, 可以通过配置
zookeeper.serverCnxnFactory来使用 Netty -
others
之后就会运行 quorumPeer.start() 也就是起了一个线程,不过这个线程会去竞争 cpu 时间片,获得后就会 run 起来
3. QuorumPeer
这个类负责维护这个 server 在运行期间的所有事物,或者说,一个 server ,其实就是一个 quorumPeer 。为什么这样说?
zk 在运行期间,无非就是和 client 通信,和各个 server ,和 leader 通信,而这个类所持有的各个对象,就是干这些事情的。
3.1 QuorumPeer.start()
我们先来看看 start 的时候,做了什么
public synchronized void start() {
// 验证 myid 正确性
if (!getView().containsKey(myid)) {
throw new RuntimeException("My id " + myid + " not in the peer list");
}
// 装载 zk database
loadDataBase();
startServerCnxnFactory();
try {
adminServer.start();
} catch (AdminServerException e) {
LOG.warn("Problem starting AdminServer", e);
System.out.println(e);
}
// 开启一轮选举
startLeaderElection();
startJvmPauseMonitor();
super.start();
}
做了些验证等其他操作后,开启了一轮选举,我们看下这个方法做了什么
public synchronized void startLeaderElection() {
try {
// 很明显,我们初始时状态就是 LOOKING,所以会初始化一张自己的选票
if (getPeerState() == ServerState.LOOKING) {
currentVote = new Vote(myid, getLastLoggedZxid(), getCurrentEpoch());
}
} catch (IOException e) {
RuntimeException re = new RuntimeException(e.getMessage());
re.setStackTrace(e.getStackTrace());
throw re;
}
// 初始化选举算法
this.electionAlg = createElectionAlgorithm(electionType);
}
protected Election createElectionAlgorithm(int electionAlgorithm) {
Election le = null;
switch (electionAlgorithm) {
// 1,2 都会抛异常
case 3:
// QuorumCnxManager 负责选举期间所有的 TCP 连接!!!
// 为什么这个类要在这里初始化?
// 因为他要负责监听选举
QuorumCnxManager qcm = createCnxnManager();
QuorumCnxManager oldQcm = qcmRef.getAndSet(qcm);
if (oldQcm != null) {
LOG.warn("Clobbering already-set QuorumCnxManager (restarting leader election?)");
oldQcm.halt();
}
QuorumCnxManager.Listener listener = qcm.listener;
if (listener != null) {
// listener 负责监听所有连接
listener.start();
FastLeaderElection fle = new FastLeaderElection(this, qcm);
// 开启选举线程
fle.start();
le = fle;
} else {
LOG.error("Null listener when initializing cnx manager");
}
break;
default:
assert false;
}
return le;
}
3.2 FastLeaderElection
这里,我们先看下 FLE(FastLeaderElection) 的类图
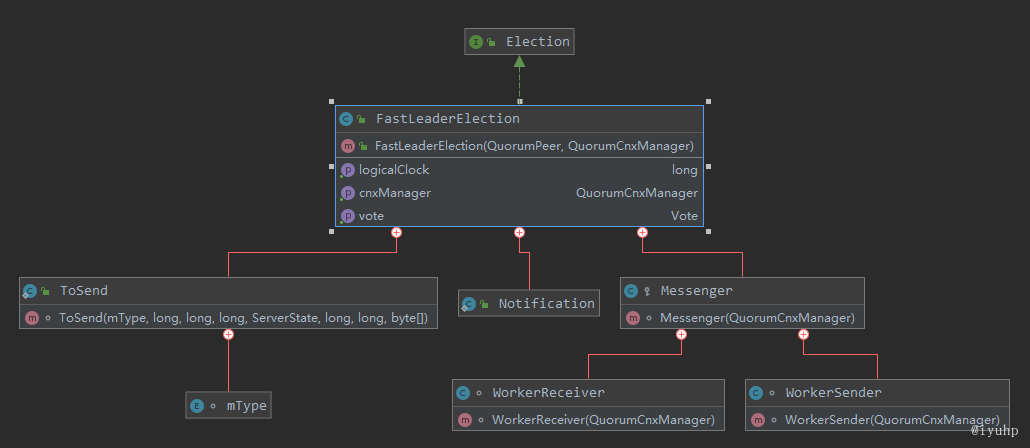
FLE 主要持有的对象有
-
ToSend:就是一个封装类,用来封装发送的消息体
-
Notification:也是一个封装类,用来告知其他 server,vote 发生了变化的实体
-
Messenger:真正干事情的,用于发送和接受选举期间的选票,其中:
- WorkerReceiver:接收选票
- WorkerSender:发送选票
-
FastLeaderElection 里还有两个很重要的变量,我们从名字也能很好理解
- sendqueue LinkedBlockingQueue<ToSend> : 用来接收需要发送的选票队列
- recvqueue LinkedBlockingQueue<Notification> : 用来接收从其他 server 发过来的选票队列
我们可以看到 FLE 虽然有个 start() 方法,可是它并不是一个线程类! 在 start 之后,它事实上是初始化了 Messenger ,之后 Messenger 去初始化 WorkerReceiver 和 WorkerSender ,这两个是线程类,并且被 start 了。
也就是说,这两货开始干活了: 这两货会根据接收/发送的选票的各种状态,分别塞给 sendqueue 和 recvqueue
- sendqueue 最终被前文提到的
QuorumCnxManager消费,由它发送给其他 server - recvqueue 最终由 fle 在计算选票时候消费,以此来确定 leader 的诞生
3.3 QuorumPeer.run()
简单介绍完 FLE ,现在我们回到 QuorumPeer 这个类,之前我们在 QuorumPeerMain 里 start 了这个线程,现在,它,终于争取到了 cpu 时间片,它可以 run 了!!!
QuourmPeer 中包含的几种状态:
- ServerState : 标记当前 server 状态
- LOOKING:该状态下会发起选举
- OBSERVING:表明处于观察者状态
- FOLLOWING:跟随者状态
- LEADING:领导者状态
- ZabState:标记 zab 协议的状态
- ELECTION :选举阶段
- DESCOVERY:发现阶段,和各个 follower/observer 建立 tcp 连接
- SYNCHRONIZATION:同步阶段,和各个 follower 同步信息
- BROADCAST:广播阶段
// 源码参见 org.apache.zookeeper.server.quorum.QuorumPeer#run
// 这里对代码做了精简处理
public void run() {
// 设置 jmx
try {
while (running) {
switch (getPeerState()) {
case LOOKING:
if (Boolean.getBoolean("readonlymode.enabled")) {
// readonly 模式下的必要处理 [1]
setCurrentVote(makeLEStrategy().lookForLeader());
// ...
} else {
// 这个标志和配置里的 version 有关
// version 和 zk 的 dynamic 配置有关
// 暂时还没有去看这块的东西,后面把这里的坑填上
if (shuttingDownLE) {
shuttingDownLE = false;
startLeaderElection();
}
setCurrentVote(makeLEStrategy().lookForLeader());
}
break;
case OBSERVING,FOLLOWING,LEADING:
// 设置为 OBSERVER FOLLOWER LEADER
break;
}
}
}
这里就是负责发起选举的主流程。很简单,直接调用 FLE 的 lookForLeader 方法。职责明确。
3.4 lookForLeader()
一张选票,可能有以下几种问题:
- 选票数据出了问题,比如 tcp 传输过程中,某个数据包丢了...
- 投出这张选票的 server 没有权限(observer)
- 收到选票时,我自己的状态并不在 LOOKING 状态(什么时候会有这种情况呢? [4])
- 收到选票时, 其他 server 的选票不是 LOOKING 状态(这个下文会分析,可以先想一下)
- 正常的选票,你在寻找 leader(选票状态为 LOOKING),我也在寻找 leader (我的状态也是 LEADING)
上面的前三种情况,都会由 WorkReceiver 处理掉
后面的两种情况,WorkerReceiver 才会把选票放入 recvqueue 中,由下面的流程来处理。
在看下面的代码之前,先介绍下几个变量以及数据结构
- logicalclock:用来记录我自己的选举轮次
- todo
- Notification (处理后的一张选票)
- leader: long , 选票的 sid ,即 myid,这里选票要选举的那个 server 的 sid,不是自己的
- peerEpoch:投票人选举的 leader 所处的年代
- zxid:投票人选举的 leader 的 zxid
- sid: long ,投票人自己的 sid
- electionEpoch: 投票人的投票轮次,这个值会和我自己的 logicalclock 比较,判断是不是处于同一个轮次
- state: 投票人的 serverState
- qv:投票人的投票信息
zk 针对两张合法的选票,根据如下规则做比较
源代码: org.apache.zookeeper.server.quorum.FastLeaderElection#totalOrderPredicate
- epoch: 即待选 leader 所处的年代,选大的! 也就是 notification 中的 peerEpoch
- zxid: epoch 一样的时候,看待选 leader 的 zxid,选大的!
- myid:还一样怎么办? 选 myid 大的! 即 notification 中的 leader
// 同样对代码做了精简
// 源码参见 org.apache.zookeeper.server.quorum.FastLeaderElection#lookForLeader
public Vote lookForLeader() throws InterruptedException {
try {
// 用来存储有效选票(logicalClock == 选票.electionEpoch)的集合
// server 根据它来判断选举结果
Map<Long, Vote> recvset = new HashMap<Long, Vote>();
// 关于这个字段的详细解释以及 pr [2]
Map<Long, Vote> outofelection = new HashMap<Long, Vote>();
int notTimeout = minNotificationInterval;
// logicalclock 增加, 同时初始化一张自己的选票,并广播出去
synchronized (this) {
logicalclock.incrementAndGet();
updateProposal(getInitId(), getInitLastLoggedZxid(), getPeerEpoch());
}
sendNotifications();
SyncedLearnerTracker voteSet;
while ((self.getPeerState() == ServerState.LOOKING) && (!stop)) {
// 前文提到的 recvqueue ,这里从这个队列拿选票
Notification n = recvqueue.poll(notTimeout, TimeUnit.MILLISECONDS);
// 没有选票! 是什么情况呢? 还有这里为什么一种会重新发送,另一种又没有呢? [3]
if (n == null) {
if (manager.haveDelivered()) {
sendNotifications();
} else {
manager.connectAll();
}
} else if (validVoter(n.sid) && validVoter(n.leader)) {
// 投票人的 serverState
switch (n.state) {
case LOOKING:
// 投票人选举轮次大,说明之前的投票都无效,所以这里清空票箱
// 同时更新自己的 logicalclock,
if (n.electionEpoch > logicalclock.get()) {
logicalclock.set(n.electionEpoch);
recvset.clear();
// 比较两张选票并更新
if (totalOrderPredicate(n.leader, n.zxid, n.peerEpoch, getInitId(), getInitLastLoggedZxid(), getPeerEpoch())) {
updateProposal(n.leader, n.zxid, n.peerEpoch);
} else {
updateProposal(getInitId(), getInitLastLoggedZxid(), getPeerEpoch());
}
// 更新选票后,发送个其他 server
sendNotifications();
} else if (n.electionEpoch < logicalclock.get()) {
// 你的选举轮次比我小,我只能对你爱理不理了
break;
// 处于同一个选举轮次的时候,也是比较选票并更新
} else if (totalOrderPredicate(n.leader, n.zxid, n.peerEpoch, proposedLeader, proposedZxid, proposedEpoch)) {
updateProposal(n.leader, n.zxid, n.peerEpoch);
sendNotifications();
}
// 无效的选票都 break 掉了,到这里都是有效的选票,放入票箱
recvset.put(n.sid, new Vote(n.leader, n.zxid, n.electionEpoch, n.peerEpoch));
// 统计选票,这里需要说下,所有 update 操作,都会更新自己的 proposedLeader 等数据
// 所以这里 new Vote 参数,都是更新后的参数
voteSet = getVoteTracker(recvset, new Vote(proposedLeader, proposedZxid, logicalclock.get(), proposedEpoch));
// 超过半数
if (voteSet.hasAllQuorums()) {
// 这里的处理很有意思了,它会再次查看,从上面取出选票,到运行到这里的这段时间内
// 是不是又收到了选票,如果不仅收到了,还是一张最牛皮的,拿出来后,又塞了回去!
// 因为 break,而 n 不为空,会进入到外面的 while 循环,再次跑一遍上面的流程
// 那么,什么情况下,这张选票里的 leader 会当选呢?
// 很明显,超过半数的 server ,在收到这张选票之前,没有确定 server,那它就
// 有概率当选
while ((n = recvqueue.poll(finalizeWait, TimeUnit.MILLISECONDS)) != null) {
if (totalOrderPredicate(n.leader, n.zxid, n.peerEpoch, proposedLeader, proposedZxid, proposedEpoch)) {
recvqueue.put(n);
break;
}
}
// 到这里,leader 就能确定了
if (n == null) {
setPeerState(proposedLeader, voteSet);
Vote endVote = new Vote(proposedLeader, proposedZxid, logicalclock.get(), proposedEpoch);
leaveInstance(endVote);
return endVote;
}
}
break;
case OBSERVING:
break;
case FOLLOWING:
case LEADING:
// 可以思考下,什么情况,会跑到这里来 [5]
// 同一个选举轮次,什么情况呢?
// 我们都参与了投票,别人都搞完选出 leader 了,回复我的时候
if (n.electionEpoch == logicalclock.get()) {
recvset.put(n.sid, new Vote(n.leader, n.zxid, n.electionEpoch, n.peerEpoch, n.state));
voteSet = getVoteTracker(recvset, new Vote(n.version, n.leader, n.zxid, n.electionEpoch, n.peerEpoch, n.state));
if (voteSet.hasAllQuorums() && checkLeader(recvset, n.leader, n.electionEpoch)) {
setPeerState(n.leader, voteSet);
Vote endVote = new Vote(n.leader, n.zxid, n.electionEpoch, n.peerEpoch);
leaveInstance(endVote);
return endVote;
}
}
// 新的 server 加入稳定的 ensemble 时,会到这里
// 主要验证当前 leader 是不是真的被超半数的 follower 追随
outofelection.put(n.sid, new Vote(n.version, n.leader, n.zxid, n.electionEpoch, n.peerEpoch, n.state));
voteSet = getVoteTracker(outofelection, new Vote(n.version, n.leader, n.zxid, n.electionEpoch, n.peerEpoch, n.state));
if (voteSet.hasAllQuorums() && checkLeader(outofelection, n.leader, n.electionEpoch)) {
synchronized (this) {
logicalclock.set(n.electionEpoch);
setPeerState(n.leader, voteSet);
}
Vote endVote = new Vote(n.leader, n.zxid, n.electionEpoch, n.peerEpoch);
leaveInstance(endVote);
return endVote;
}
break;
}
}
}
return null;
}
}
到这里,即基本说完了 FLE 的大致算法。
我们总结下,无非几句话:
- 判断是不是同一个选举轮次。选举轮次只有在发起选举的时候才会更新。比我小的,我都不带理睬,相同或大的,根据 epoch , zxid , myid 比较并更新选票,同时重新发送自己的选票。
- 在收集到足够多的选票后,判断是否超过了半数(事实上,zk 还去检查了这个即将当选的 leader 的状态,可以说相当负责了)。超过的话,就进入下一个状态。
- 如果是半路杀出来的,即新的 server 加入,就检查当前 leader 的合法性,合法就加入其中。(如果不合法,自然会不断的发送选票,直到集群中大部分的 server 都观察到,因为这是一个 while 循环啊)
FLE Flow
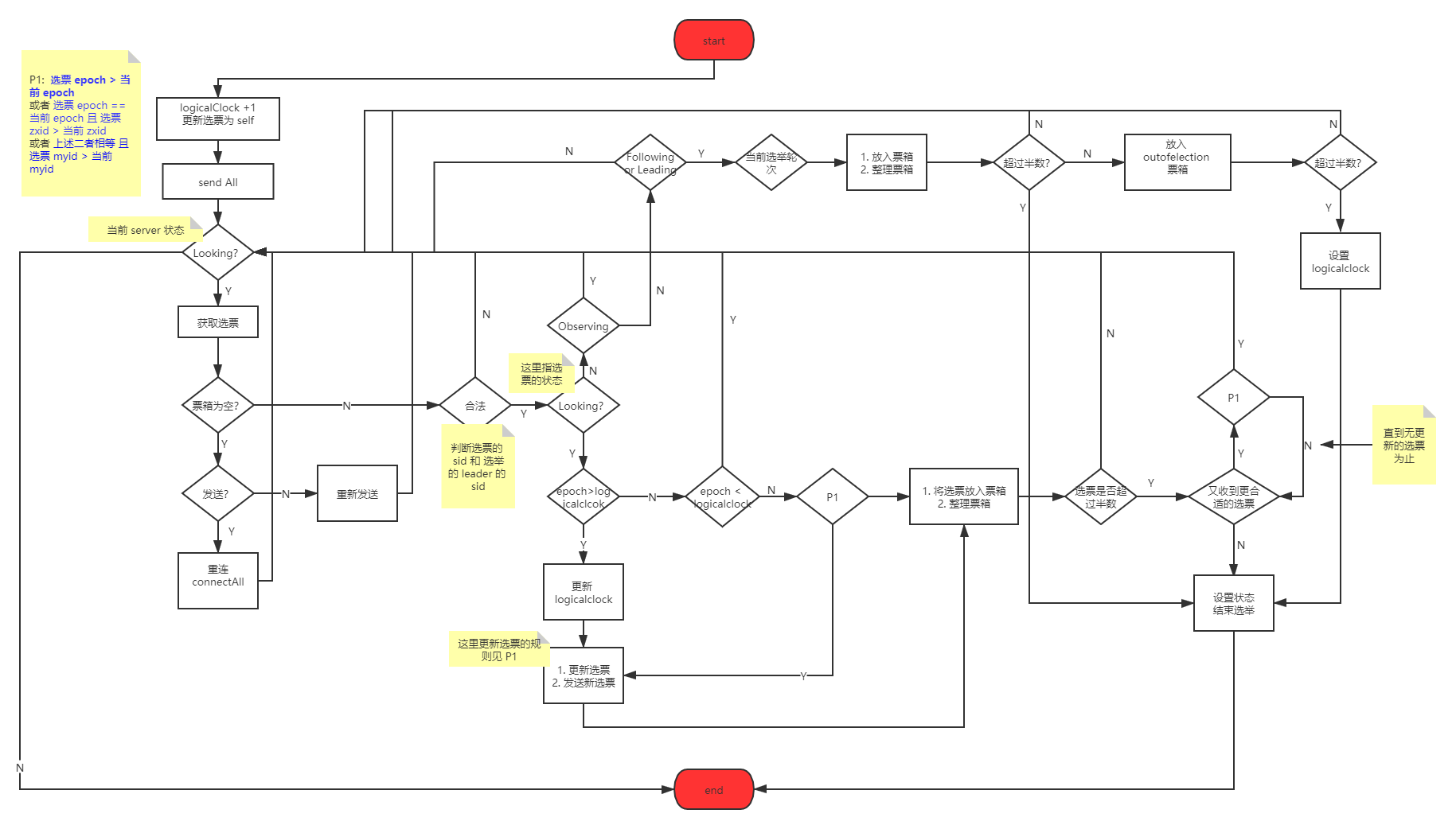
该流程图可能不是特别精确,少了些具体的流程,请务必批判着看。准确的说,所有的网络文章,你都得批判着看 :joy:
注释
[1]:
zk 提供 readonly 模式的 server 。 我们知道,当一台 server 与超过半数的 server 丢失连接后,就会停止工作,读写请求都不会处理。 但是使用该模式后,则该 server 仍然会处理 读 请求。虽然保证了可用性,但丢掉了一致性,也就是说,此时的 CAP 从 CP 转换到了 AP
[2]
[3]
什么情况下会收不到选票呢?
- 我已经发送了,是你们的问题,你们没有给我回复!!! 可能所有 server 都因为各种问题丢失了这条消息,那没办法,我只能再发一次了。那么这里需要担心选票重复的问题吗? of course not !我是用 set 存储选票的,你相同的选票,我覆盖一次就好了呗。
- 我以为我发送了,其实我并没有... 不好意思,是我的锅!!! 原来我和你们的连接出了问题,好吧,我重新连接一次。 可是这里,重新连接后 没有重新发送选票 , 为什么这样子?我们可以稍微看下它发送消息的机制,需要先建立连接,然后取出消息发送,所以如果压根就没有连上,那么就没有所谓的取出消息发送,所以这里并不需要再次发送消息。
[4]
- 当有新的 server 加入到一个稳定运行的 ensemble 时,这个新 server 会发起投票,我去回复这个新 server 发起的选举时,自己本身的状态,必然是 LEADING / FOLLOWING /OBSERVING
- 集群中,有 server 发现 leader 挂掉了,此时它会发起投票,可是我还没感知到 leader 的状态 ,依然还是之前的状态:FOLLOWING / OBSERING,我去回复时
[5]
- 我作为一个新 server ,发起投票时,别人回复给我的信息,会到这里
- 我及时发现 ensemble 里的 leader 挂掉了,发起新的选举时, 别人的回复会来这里
- 选举时,有一半的 server 完成了选举,我年纪大了,速度慢,发起投票后,别人的回复
- 我作为 Follower ,跑着跑着,竟然挂掉了,重新拉起来时,也会如此
