前言
本文适用于给没有任何目录的pdf添加目录/书签。
本文并未提出创新。 只是把前辈的东西抄写了一遍,以便日后查验,在此感谢提出这个方法的前辈。
这是本人第一次在掘金写文章,如有错误,恳请大家批评指正!
需要准备的东西
- FreePic2Pdf, 用于给pdf添加目录的。
- SysTools PDF Unlocker,用于解锁pdf。有时下载的pdf收保护,无法编辑,可以用这个软件解锁。非必须
- 会正则表达式,但是用到的不多。正则表达式基础学习
- 一个可以使用正则表达式来进行查找替换功能的编辑器,如Visual Studio Code
开始
在这里,我使用一本扫描版的pdf
提取目录
基于使用的例子, pdf目录结构和编辑器的中的对应关系如下图:

最省事的方法
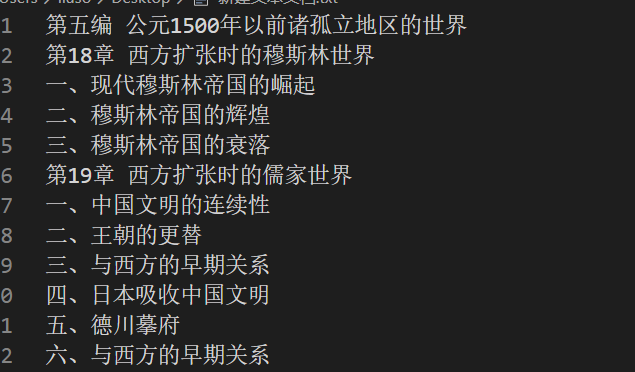
有时候,提供下载的网站上会提供目录,如下图

这样的话,直接将目录内容复制到文字编辑器中,就完成提取目录了,如图:
注:这个目录是没有页码的,有的网站提供页码,如果有页码将页码也复制进来即可
有的时候直接百度目录可能会有奇效!
文字型pdf
如果使用的pdf是文字型pdf,就是可以复制文字的那种。直接将pdf中书本的目录复制到文字编辑器中,微调格式,最后达到与最省事的方法中的效果一致
扫描型pdf(后续的步骤将在此基础上)
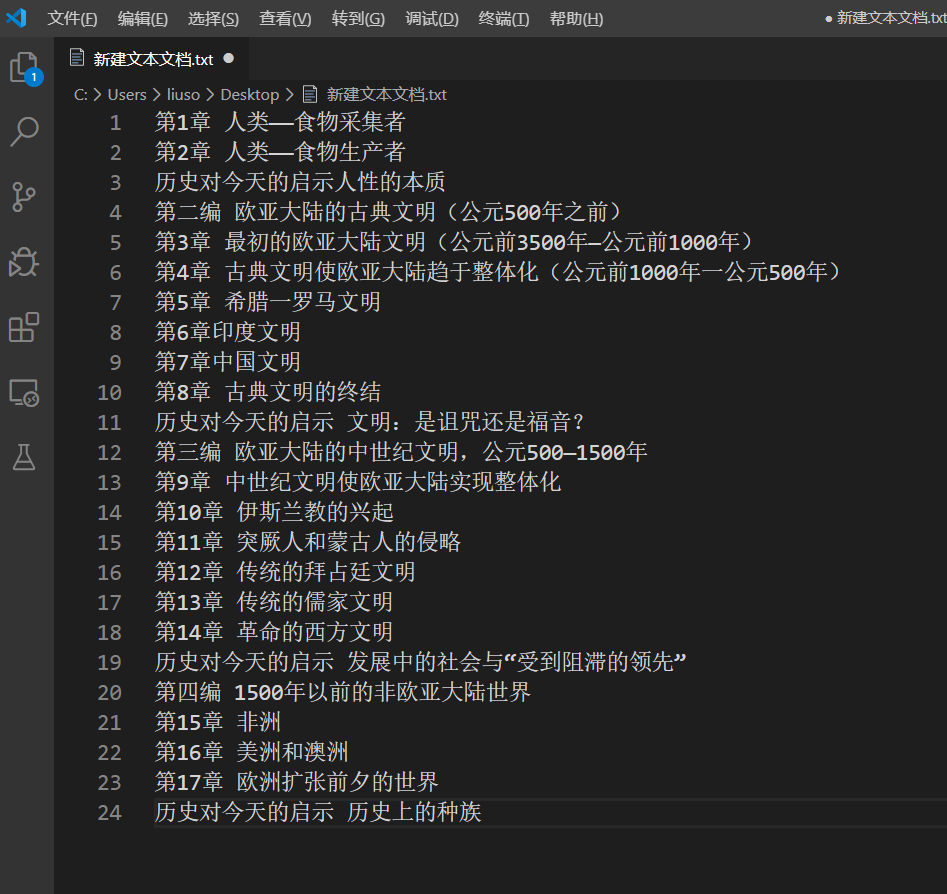
如果使用的扫描型的pdf,那制作目录时就有点棘手了,因为文字无法复制,下载的网页又不提供目录的话,就只能手动的在编辑器中输入。还有一种方法时使用OCR文字识别,这样可以减少手动的工作量,尤其是在文件较大的pdf中。在这里,我使用一本扫描版的pdf,所以我使用OCR,将目录文字大致识别了出来,复制到编辑器中,进行调整,效果如下图:
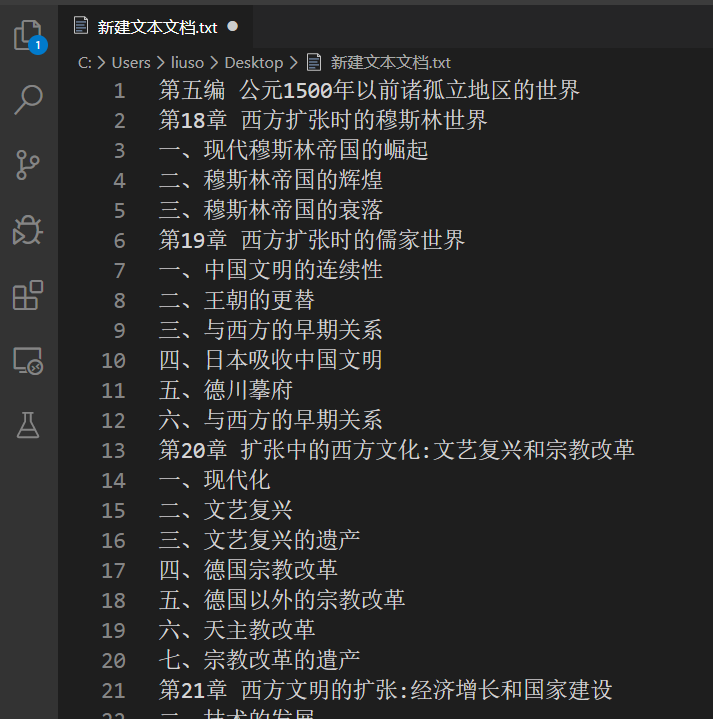
页码并未给出,因为OCR并未给出页码,这个只能受累自己添加。╮(╯▽╰)╭
在此,我添加页码的格式是标题+一个空格+页码
给提取后的目录添加页码(如果复制目录时页码一并复制的可以跳过本节)
由于我用的OCR无法识别出页面,所以,我只能手动的增加页码。最终如下图(累死我了):
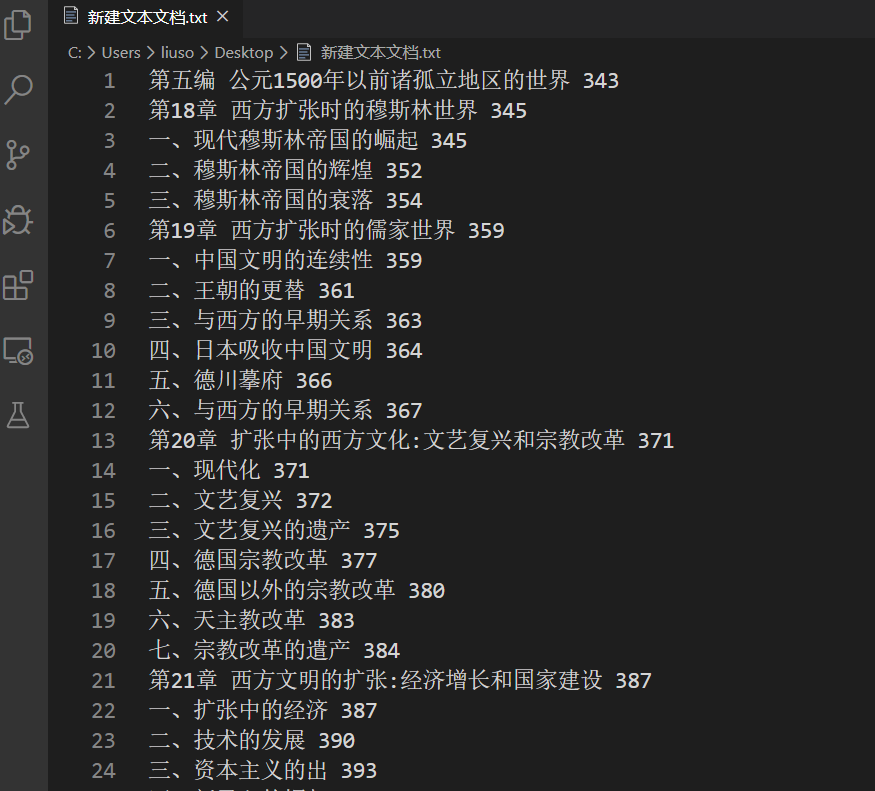
格式化编辑器里的目录,使之满足FreePic2Pdf的要求
FreePic2Pdf这个软件如果想目录分层次结构 , 是使用\t(制表符)来完成的
第一章节
第一小节(前面一个\t)
第一部分(前面二个\t)
所以,我们的目标是下图:
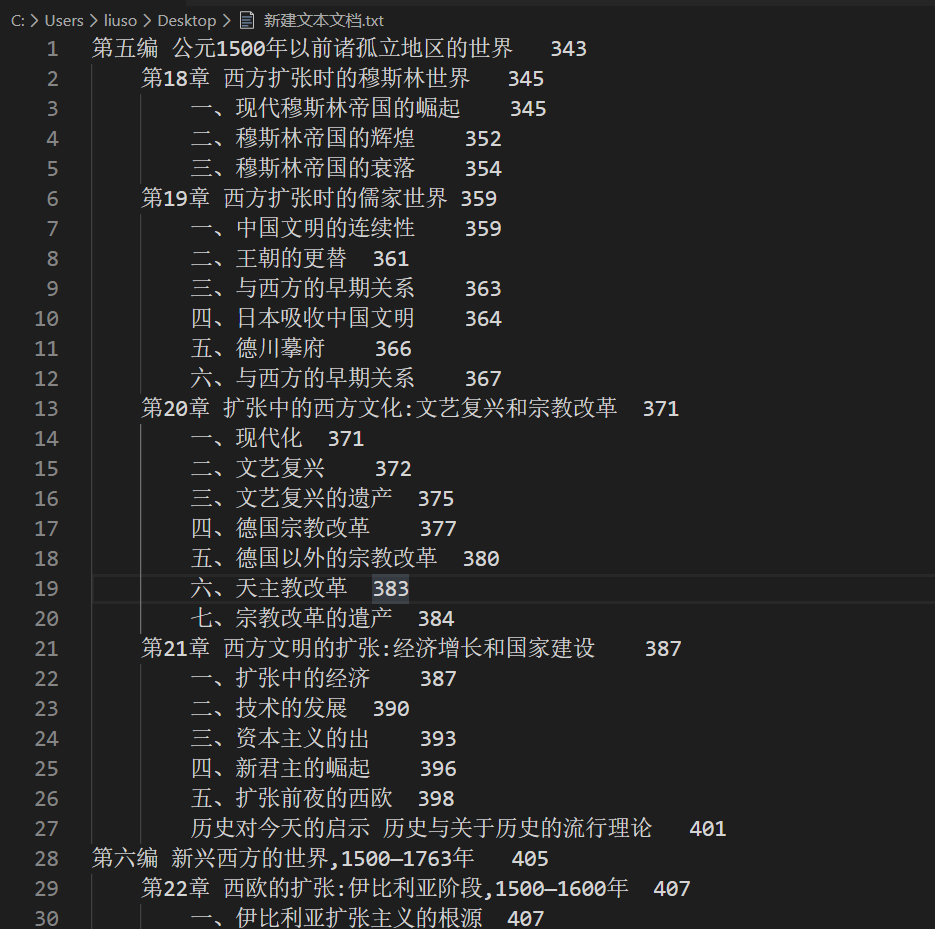
处理第一层标题
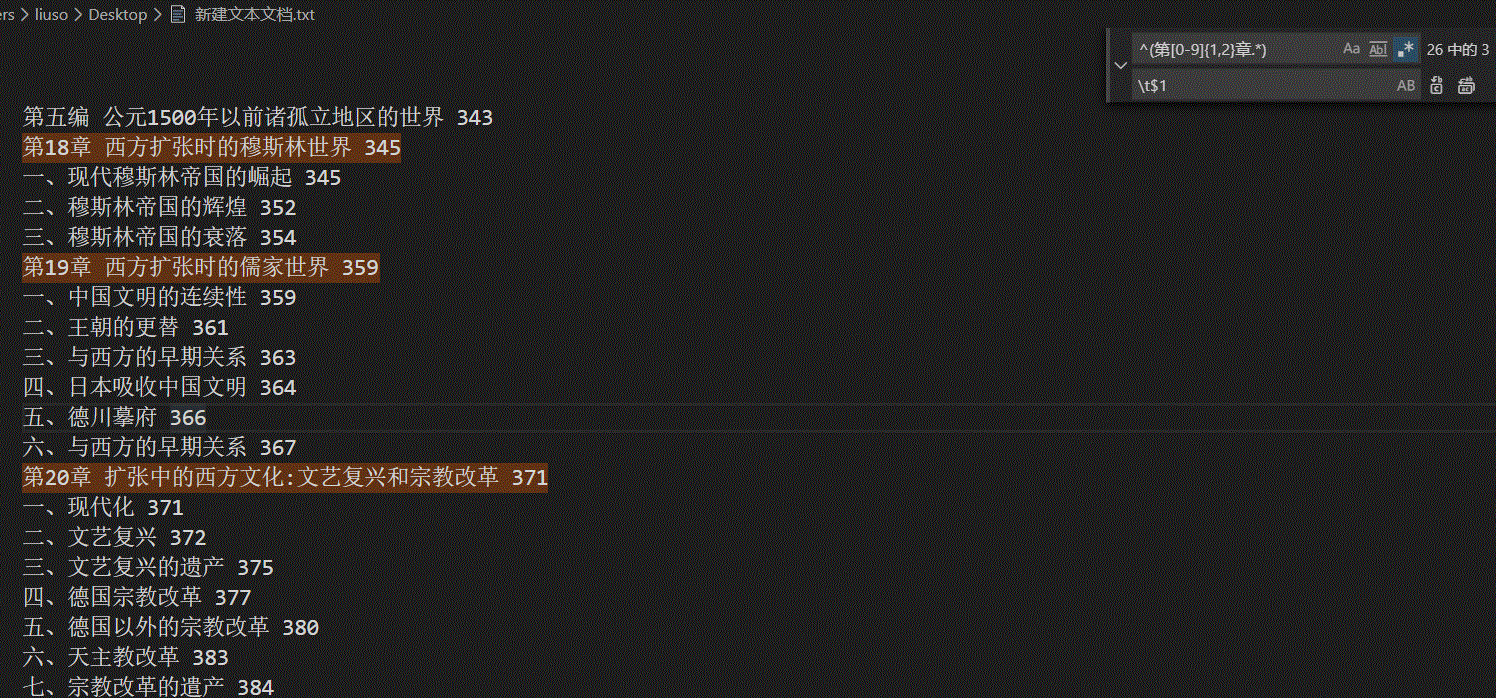
我们要使用正则表达式来处理,根据本文中pdf的目录结构,最顶层结构是第X编,它不用做任何处理。 第一层的结构是第X章我们要在前面加一个制表符,故查询正则表达式为^(第[0-9]{1,2}章.*), 替换正则表达为\t$1。具体操作如下图:
处理第二层标题
第二层标题的结构是n、标题,查询正则表达式为^(.、.+), 替换正则表达式为\t\t$1。如下图:
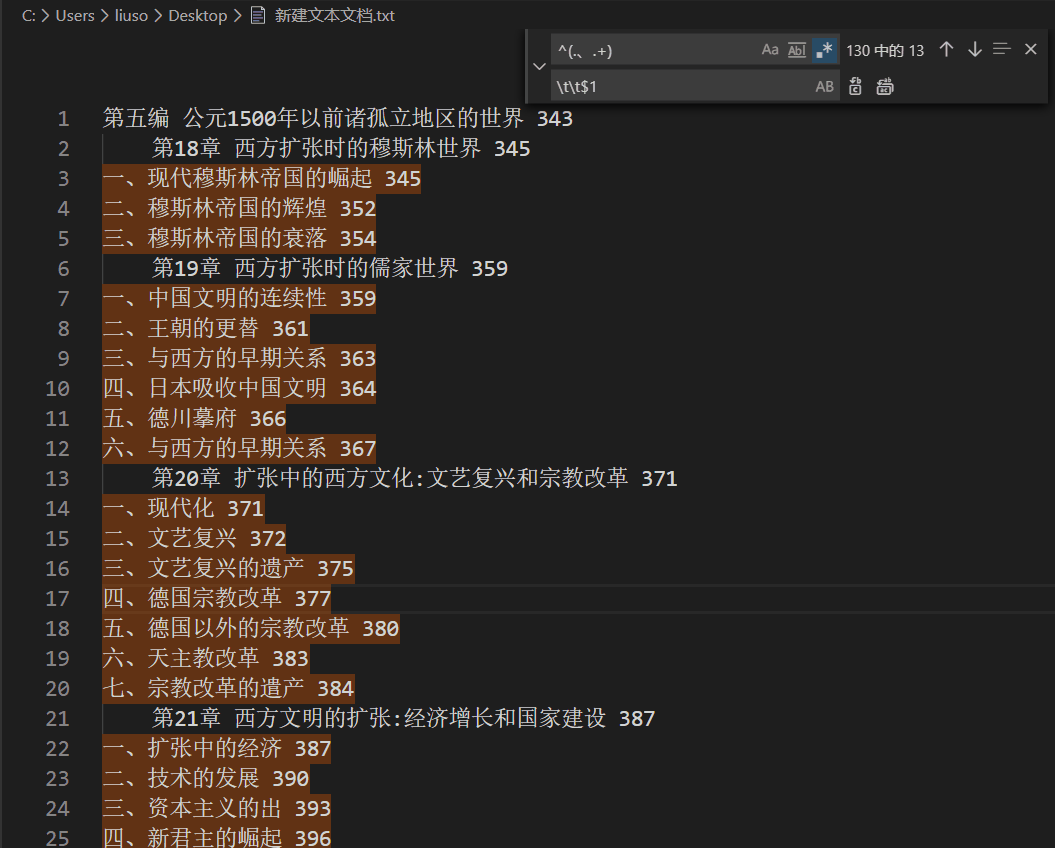
如果还有更多层标题 , 那么也依照次方法进行分层
处理特殊标题
我们可以看到目录里还有一些不符合规律的标题,如"历史对今天的启示......", 我们需要将其调整到合适位置,可以用正则表达式,也可以手动的去调整
将页面号设置成符合要求的格式
每个标题后面跟着的页码非常重要 , 如果想要在pdf点击标题就跳转到相应的页的话 , 那么一定要设置好。
- 标题到页面只能是一个\t
- 复制从标题到页码中间的空格 , 选择替换成\t即可
我们使用正则表达式找到页码相关的部分,然后将前面的空格替换为\t。
查询表达式为(\s{1,1})([0-9]{1,3}), 替换表达式为\t$2 如下图
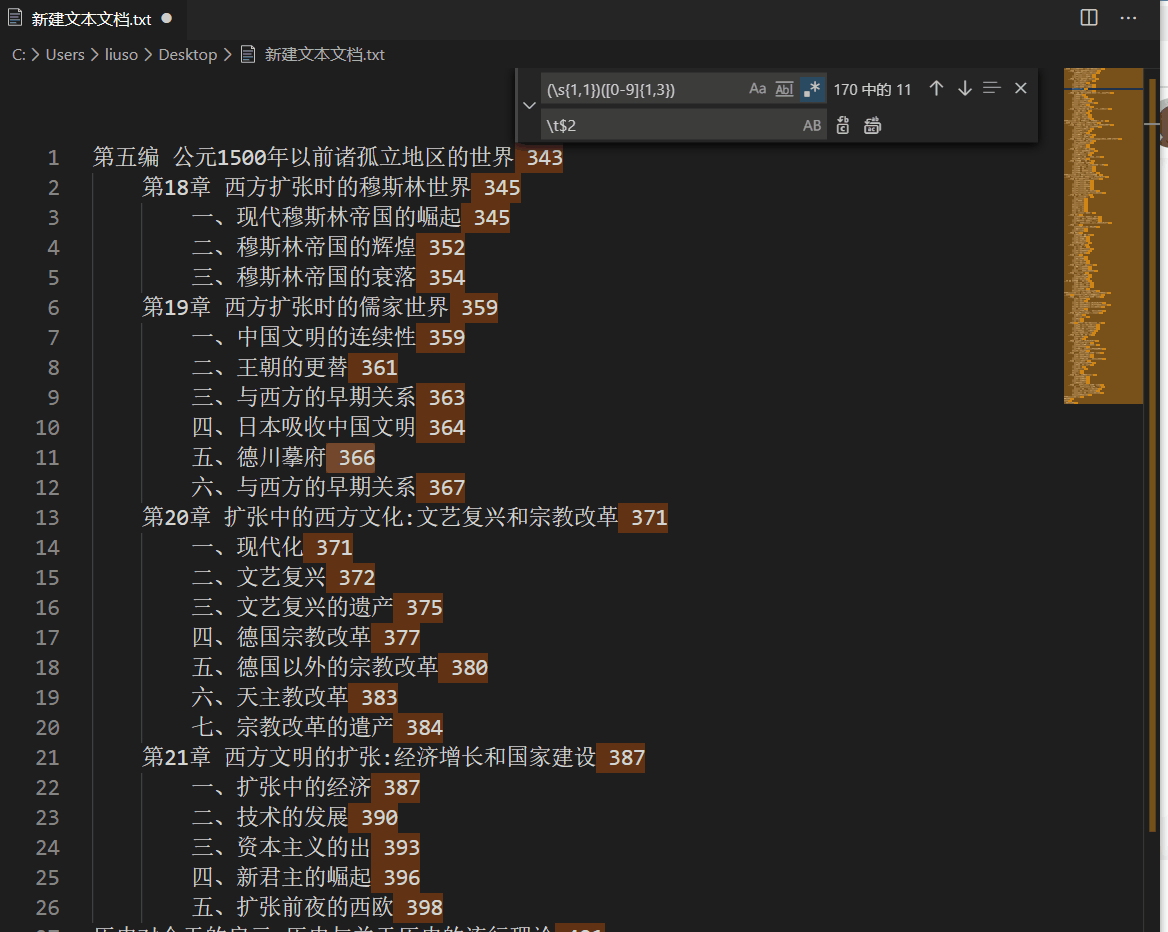
经检查无误后,提取目录的工作就大功告成了!
使用软件添加目录
以上步骤都完成后 , 那么就可以使用软件进行添加目录操作了.下面是软件使用截图
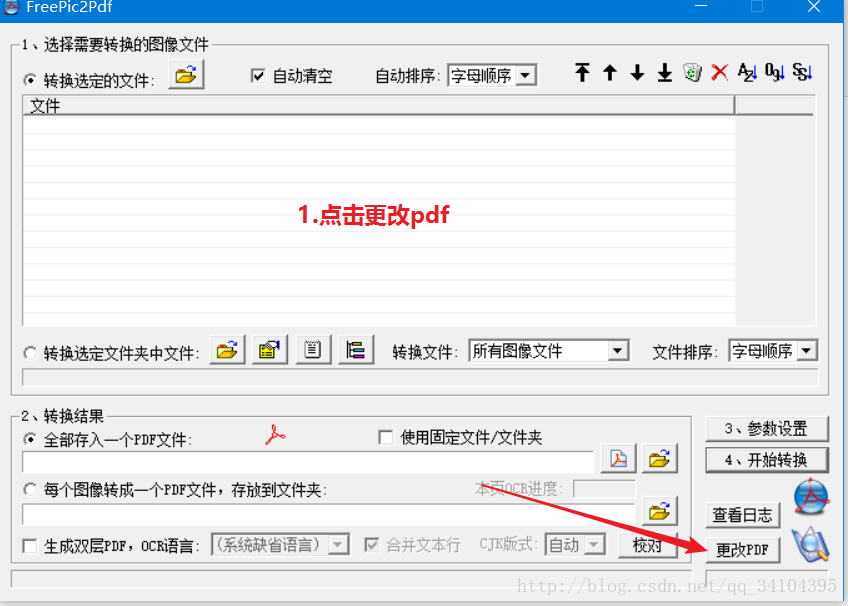
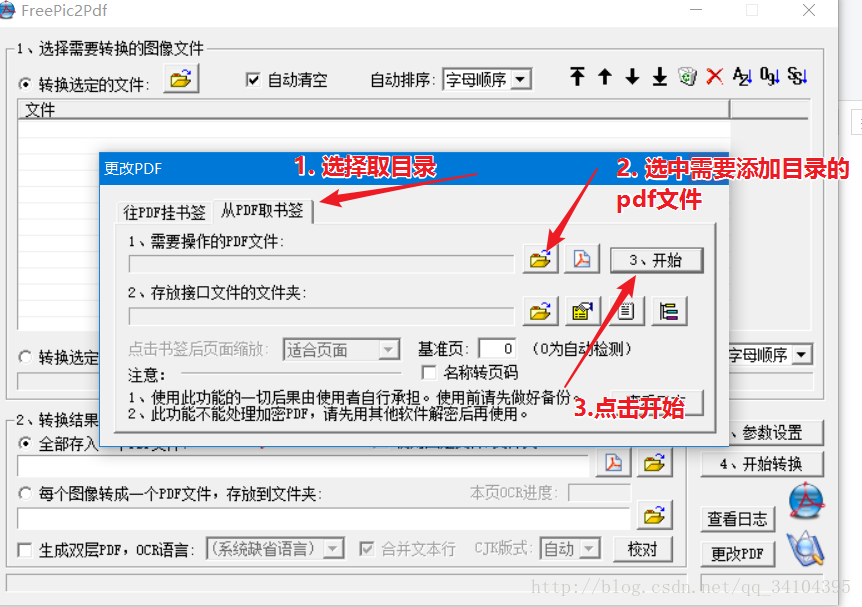
经过上图这一步后,打开接口文件的文件夹
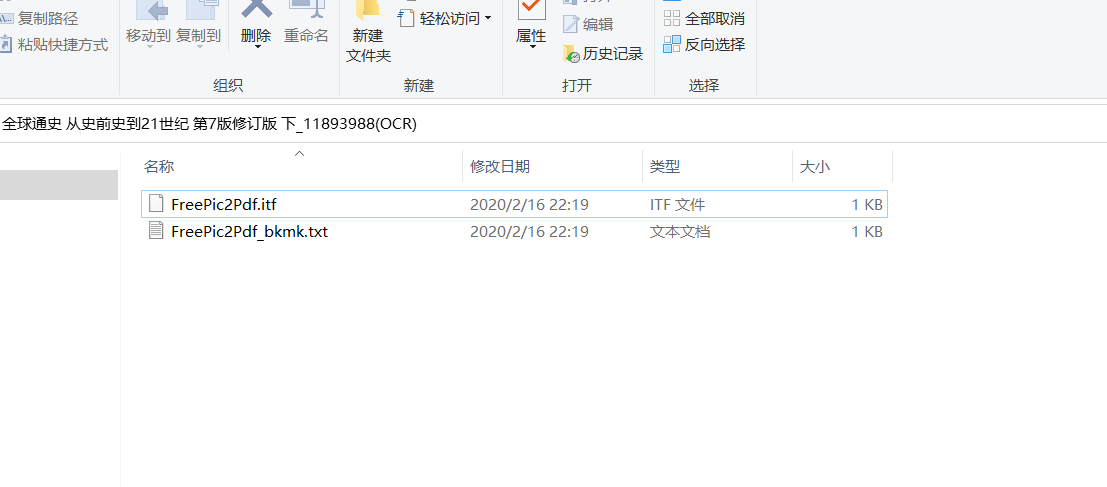
打开上图中的.txt文件
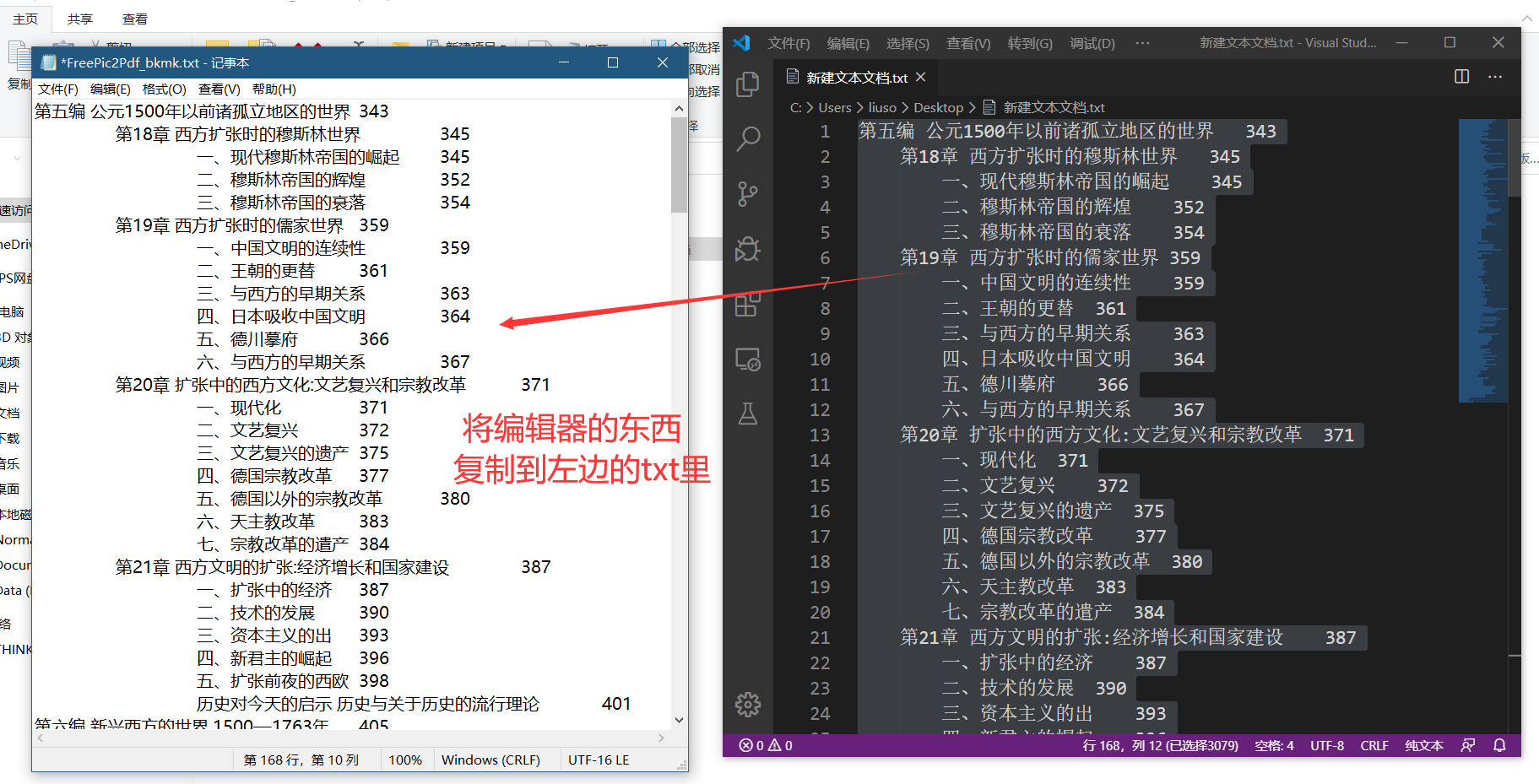
保存好修改后的txt文件,打开.itf文件,修改后保存
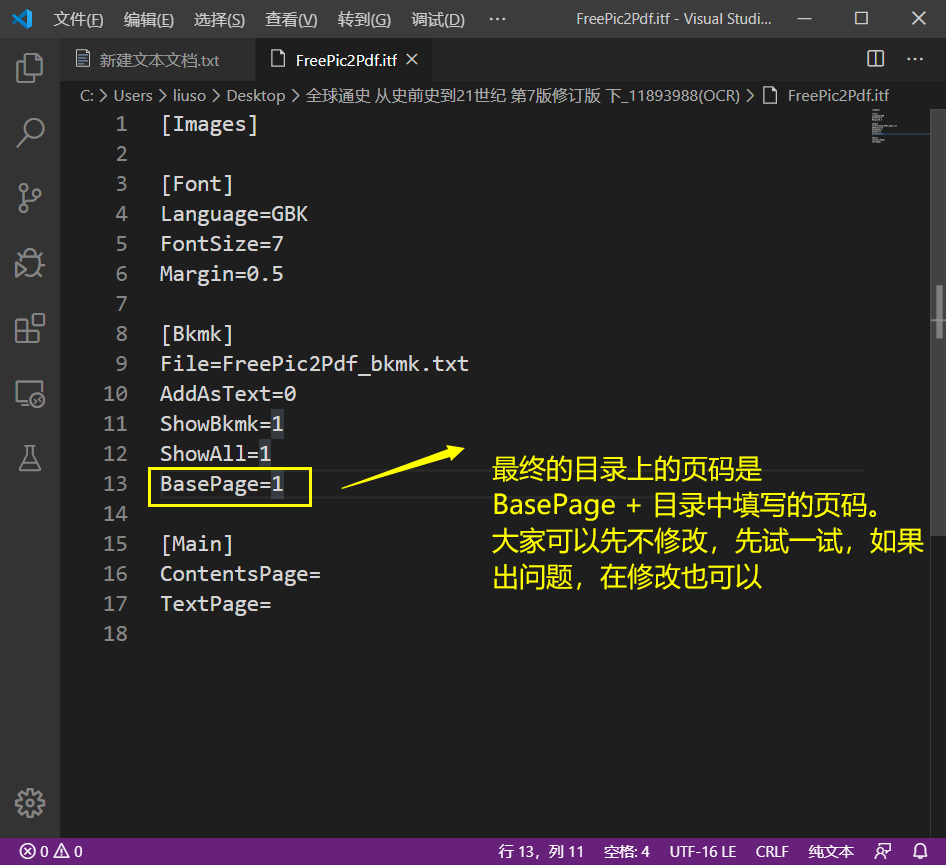
可以查看目录和页码对上还是对不上,如果对不上,就修改这个BasePage
最后一步如下图
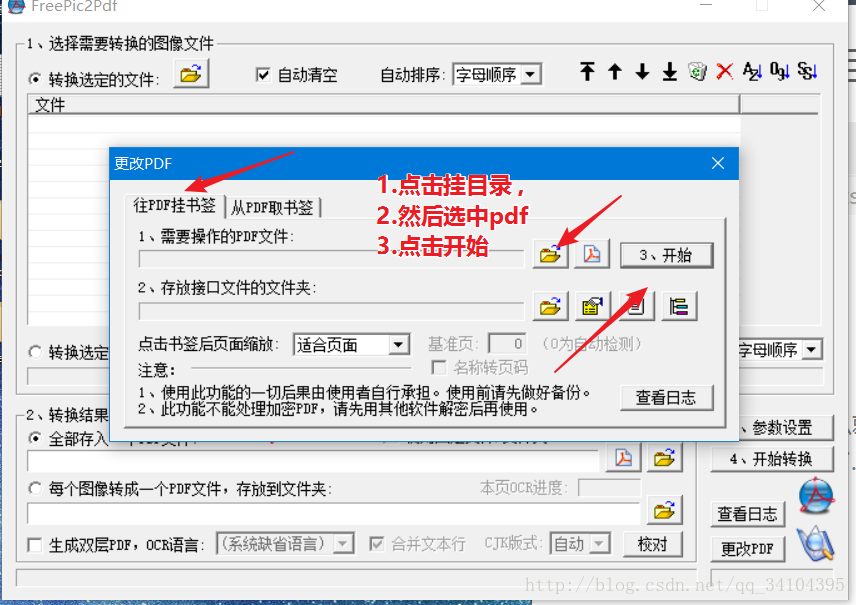
最终效果图