

Java序列化与ByteBuffer序列化生成内容大小比较
User类定义如下:
public class User implements Serializable {
private String userName;
private String password;
}
Java自带序列化,结果为ObjectOutputStream 字节编码长度:109
User user = new User();
user.setUserName("test");
user.setPassword("test");
ByteArrayOutputStream os =new ByteArrayOutputStream();
ObjectOutputStream out = new ObjectOutputStream(os);
out.writeObject(user);
byte[] testByte = os.toByteArray();
System.out.print("ObjectOutputStream 字节编码长度:" + testByte.length + "\n");
使用ByteBuffer序列化结果为ByteBuffer 字节编码长度:16
ByteBuffer byteBuffer = ByteBuffer.allocate( 2048);
User user = new User();
user.setUserName("test");
user.setPassword("test");
byte[] userName = user.getUserName().getBytes();
byte[] password = user.getPassword().getBytes();
byteBuffer.putInt(userName.length);
byteBuffer.put(userName);
byteBuffer.putInt(password.length);
byteBuffer.put(password);
byteBuffer.flip();
byte[] bytes = new byte[byteBuffer.remaining()];
System.out.print("ByteBuffer 字节编码长度:" + bytes.length+ "\n");
Java序列化与ByteBuffer序列化时间比较
Java自带序列化
User user = new User();
user.setUserName("test");
user.setPassword("test");
long startTime = System.currentTimeMillis();
for(int i=0; i<1000; i++) {
ByteArrayOutputStream os =new ByteArrayOutputStream();
ObjectOutputStream out = new ObjectOutputStream(os);
out.writeObject(user);
out.flush();
out.close();
byte[] testByte = os.toByteArray();
os.close();
}
long endTime = System.currentTimeMillis();
System.out.print("ObjectOutputStream 序列化时间:" + (endTime - startTime) + "\n");
使用ByteBuffer序列化
long startTime1 = System.currentTimeMillis();
for(int i=0; i<1000; i++) {
ByteBuffer byteBuffer = ByteBuffer.allocate( 2048);
byte[] userName = user.getUserName().getBytes();
byte[] password = user.getPassword().getBytes();
byteBuffer.putInt(userName.length);
byteBuffer.put(userName);
byteBuffer.putInt(password.length);
byteBuffer.put(password);
byteBuffer.flip();
byte[] bytes = new byte[byteBuffer.remaining()];
}
long endTime1 = System.currentTimeMillis();
System.out.print("ByteBuffer 序列化时间:" + (endTime1 - startTime1)+ "\n");
运行结果
ObjectOutputStream 序列化时间:29
ByteBuffer 序列化时间:6
使用 Protobuf 序列化替换 Java 序列化
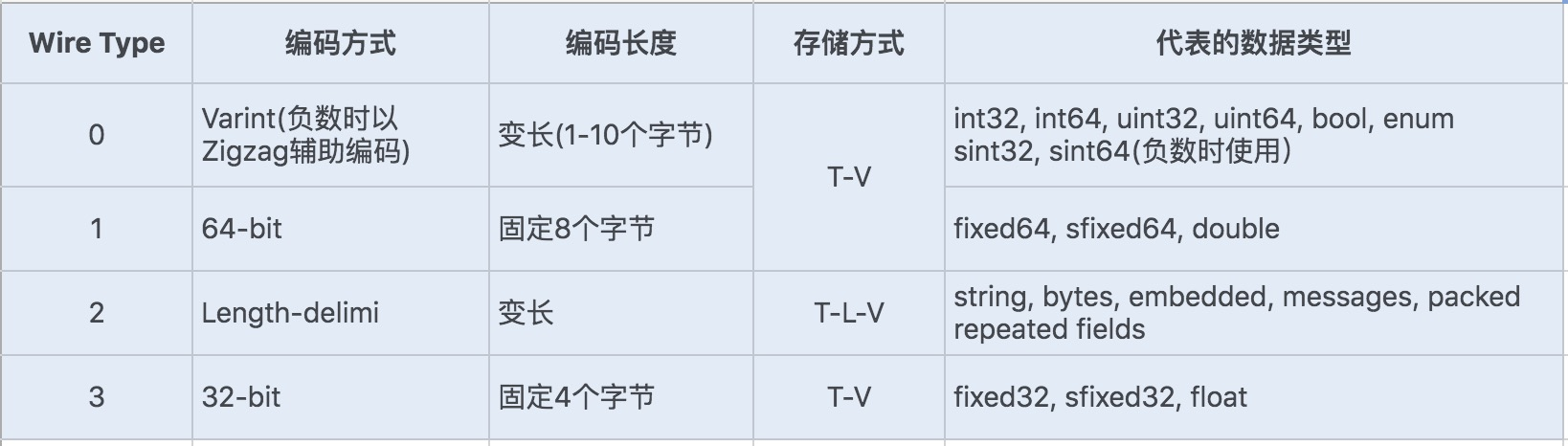
Protocol Buffers 是一种轻便高效的结构化数据存储格式。它使用 T-L-V(标识 - 长度 - 字段值)的数据格式来存储数据,T 代表字段的正数序列 (tag),Protocol Buffers 将对象中的每个字段和正数序列对应起来,对应关系的信息是由生成的代码来保证的。在序列化的时候用整数值来代替字段名称,于是传输流量就可以大幅缩减;L 代表 Value 的字节长度,一般也只占一个字节;V 则代表字段值经过编码后的值。这种数据格式不需要分隔符,也不需要空格,同时减少了冗余字段名。
定义一个消息类型
syntax = "proto3";
message SearchRequest {
string query = 1;
int32 page_number = 2;
int32 result_per_page = 3;
}
指定字段类型
在上面的例子中,所有字段都是标量类型:两个整型(page_number和result_per_page),一个string类型(query)。当然,你也可以为字段指定其他的合成类型,包括枚举(enumerations)或其他消息类型。
## 分配标识号 正如你所见,在消息定义中,每个字段都有唯一的一个数字标识符。这些标识符是用来在消息的二进制格式中识别各个字段的,一旦开始使用就不能够再改变。注:[1,15]之内的标识号在编码的时候会占用一个字节。[16,2047]之内的标识号则占用2个字节。所以应该为那些频繁出现的消息元素保留 [1,15]之内的标识号。切记:要为将来有可能添加的、频繁出现的标识号预留一些标识号。
最小的标识号可以从1开始,最大到2^29 - 1, or 536,870,911。不可以使用其中的[19000-19999]( (从FieldDescriptor::kFirstReservedNumber 到 FieldDescriptor::kLastReservedNumber))的标识号, Protobuf协议实现中对这些进行了预留。如果非要在.proto文件中使用这些预留标识号,编译时就会报警。同样你也不能使用早期保留的标识号。
