

Mysql的高级用法:group by;having;左连接;子查询(带in);行转列。
1、 行转列:
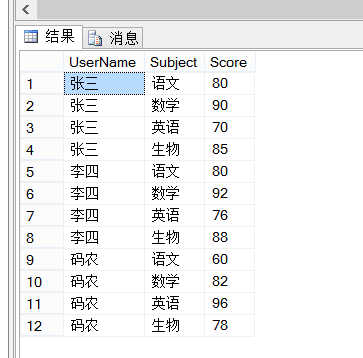
e.g:测试数据准备 CREATE TABLE [StudentScores] ( [UserName] NVARCHAR(20), --学生姓名 [Subject] NVARCHAR(30), --科目 [Score] FLOAT, --成绩 )
INSERT INTO [StudentScores] SELECT '张三', '语文', 80 INSERT INTO [StudentScores] SELECT '张三', '数学', 90 INSERT INTO [StudentScores] SELECT '张三', '英语', 70 INSERT INTO [StudentScores] SELECT '张三', '生物', 85 INSERT INTO [StudentScores] SELECT '李四', '语文', 80 INSERT INTO [StudentScores] SELECT '李四', '数学', 92 INSERT INTO [StudentScores] SELECT '李四', '英语', 76 INSERT INTO [StudentScores] SELECT '李四', '生物', 88 INSERT INTO [StudentScores] SELECT '码农', '语文', 60 INSERT INTO [StudentScores] SELECT '码农', '数学', 82 INSERT INTO [StudentScores] SELECT '码农', '英语', 96 INSERT INTO [StudentScores] SELECT '码农', '生物', 78
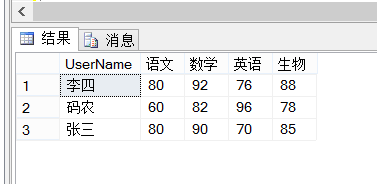
行转列SQL: select * from 表名 AS P pivot (SUM(score) for p.student in ([语文],[数学],[英语],[生物]) ) AS T
2、 列转行
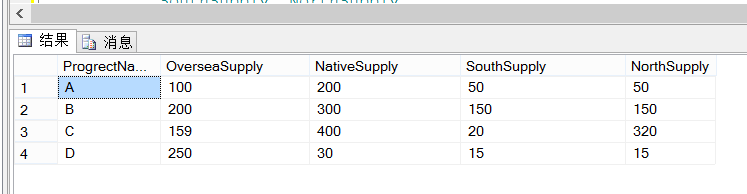
e.g: 测试数据准备 CREATE TABLE ProgrectDetail ( ProgrectName NVARCHAR(20), --工程名称 OverseaSupply INT, --海外供应商供给数量 NativeSupply INT, --国内供应商供给数量 SouthSupply INT, --南方供应商供给数量 NorthSupply INT --北方供应商供给数量 )
INSERT INTO ProgrectDetail SELECT 'A', 100, 200, 50, 50 UNION ALL SELECT 'B', 200, 300, 150, 150 UNION ALL SELECT 'C', 159, 400, 20, 320 UNION ALL
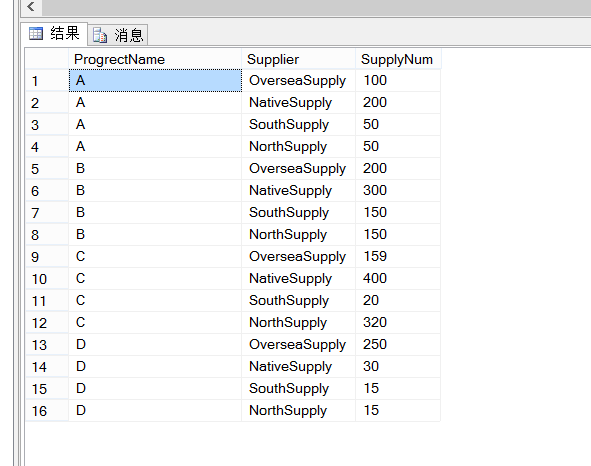
SQL: SELECT P.ProgrectName,P.Supplier,P.SupplyNum FROM ( SELECT ProgrectName, OverseaSupply, NativeSupply, SouthSupply, NorthSupply FROM ProgrectDetail )T UNPIVOT ( SupplyNum FOR Supplier IN (OverseaSupply, NativeSupply, SouthSupply, NorthSupply ) ) P
MySQL三大范式和反范式:
1. 第一范式
确保数据表中每列(字段)的原子性。 如果数据表中每个字段都是不可再分的最小数据单元,则满足第一范式。 例如:user用户表,包含字段id,username,password
2. 第二范式
在第一范式的基础上更进一步,目标是确保表中的每列都和主键相关。 如果一个关系满足第一范式,并且除了主键之外的其他列,都依赖于该主键,则满足第二范式。 例如:一个用户只有一种角色,而一个角色对应多个用户。则可以按如下方式建立数据表关系,使其满足第二范式。 user用户表,字段id,username,password,role_id role角色表,字段id,name 用户表通过角色id(role_id)来关联角色表
3. 第三范式
在第二范式的基础上更进一步,目标是确保表中的列都和主键直接相关,而不是间接相关。 例如:一个用户可以对应多个角色,一个角色也可以对应多个用户。则可以按如下方式建立数据表关系,使其满足第三范式。 user用户表,字段id,username,password role角色表,字段id,name user_role用户-角色中间表,id,user_id,role_id 像这样,通过第三张表(中间表)来建立用户表和角色表之间的关系,同时又符合范式化的原则,就可以称为第三范式。
4. 反范式化
反范式化指的是通过增加冗余或重复的数据来提高数据库的读性能。 例如:在上例中的user_role用户-角色中间表增加字段role_name。 反范式化可以减少关联查询时,join表的次数。
Mysql性能优化
1、速度优化之建立索引
1、索引分四类:
index ---- 普通索引,数据可以重复
fulltext ---- 全文索引,用来对大表的文本域(char,varchar,text)进行索引
unique ---- 唯一索引,要求所有记录都唯一
primary key ---- 主键索引,也就是在唯一索引的基础上相应的列必须为主键
2、使用索引需注意:
(1). 只对 where 和order by 需要查询的字段设置索引,避免无意义的硬盘开销;
(2). 组合索引支持前缀索引;
(3). 更新表的时候,如增删记录,MySQL会自动更新索引,保持树的平衡;因此更多的索引意味着更多的维护成本;
3、索引建立原则
(1). 尽量减少like,但不是绝对不可用,”xxxx%” 是可以用到索引的
(2). 表的主键、外键必须有索引
(3). 谁的区分度更高(同值的最少),谁建索引,区分度的公式是count(distinct(字段))/count(*)
(4). 单表数据太少,不适合建索引
(5). where,order by ,group by 等过滤时,后面的字段最好加上索引
(6). 如果既有单字段索引,又有这几个字段上的联合索引,一般可以删除联合索引
(7). 联合索引的建立需要进行仔细分析;尽量考虑用单字段索引代替
(8). 联合索引: mysql 从左到右的使用索引中的字段,一个查询可以只使用索引中的一部份,但只能是最左侧部分。例如索引是key index(a,b,c). 可以支持 a|a,b|a,b,c3种组合进行查找,但不支持b,c进行查找.当最左侧字段是常量引用时,索引就十分有效。
(9). 前缀索引: 有时候需要索引很长的字符列,这会让索引变得大且慢。通常可以索引开始的部分字符,这样可以大大节约索引空间,从而提高索引效率。其缺点是不能用于ORDER BY和GROUP BY操作,也不能用于覆盖索引 Covering index(即当索引本身包含查询所需全部数据时,不再访问数据文件本身)。
(10). NULL会导致索引形同虚设
4、禁用索引
- like “ %xxx ”
- not in , !=
- 对列进行函数运算的情况(如 where md5(password) = “xxxx”)
- WHERE index=1 OR A=10
- 存了数值的字符串类型字段(如手机号),查询时记得不要丢掉值的引号,否则无法用到该字段相关索引,反之则没关系
