

先想是不是,再问为什么!
基于笔者目前的知识水平本文将对并发进行浅层次的解读,或者说对一些基本的概念进行简单的梳理。希望可以通过本文,可以对并发有一个大概的认知,在后面的深层次的理解打好基础。若然还有更加深入的学习,依旧会借平台撰写自己的体会与心得,同时也向前辈们学习,增长自己见识。
在前面有关于欲穷千里目之JVM (五)一文中,曾经对volatile关键字进行过简单的阐述,简单叙述了volatile关键字的可见性、有序性、禁止指令重排以及不保证原子性的特点。本文将根据这一条线,一直往下捋,可JUC并不是简单就能说清楚,会有发散的知识点,以及在本文后会在对一些知识点的扩充,JUC是可以写一个系列,鉴于笔者当前水平,尽可能的写写所知道。
volatile关键字
当一个变量被volatile关键字修饰时,对于其他线程来说是可见的。在内存层面来说:当写一个volatile变量时,虚拟机会把该线程对应的本地内存中共享变量值刷新到主内存;当读一个volatile变量时,虚拟机会把该线程对应的本地内存中共享变量值设置为无效,线程接下来将从主内存重新读取共享变量也就是实现了缓存一致。在底层的执行指令中,被volatile关键字修饰的共享变量会出现Lock前缀指令,多核线程处理器将处理器缓存行的数据写入到系统内存中,写操作使得其他CPU已经存在的缓存的数据无效,在其他CPU执行其他线程操作,需要将内存中的数据重新读取。值得注意的是:volatile关键字仅能保证单个共享变量的的读写具有原子性,因此往往需要加入锁的互斥机制来保证整个临界区代码执行的原子性。
CAS算法
CAS(Compare-And-Swap)是一种硬件对并发是支持,针对多处理器的操作而设计的处理器中一种特殊指令,用于管理对共享数据的并发访问,是一种无锁的非阻塞算法的实现。
CAS主要包含三个操作数:需要读写的内存值、进行比较的值、准备写入的新值,也就是说只要当需要读写的内存值与进行比较的值相等的情况下,才会将原来的内存值替换为新的值。这样说起来好像有点绕,举个例子:当释放人犯时,需要监牢的人犯与名册上的人犯是一致,一致才会将这名人犯释放,同时关押新的人犯。这就会引发一个问题:不可能每时每刻都保证去验证这么人犯与名册一致,万一买通了查看名册的人,只有在查名册的时候通知人犯回到监牢,其余时间人犯做了其他罪案就不管,这就是经典的ABA问题。
ABA问题
在上文的例子已经很形象的说明ABA问题,术语阐述就是:需要读写的内存值已经做了其他操作变化了值,但是最后通过系类操作又变回到原来的值,再进行CAS算法时这个值已经不是最初那个值,但是它不知道。怎么解决这个问题?加一个版本号来解决,每一次对变量进行操作就对版本号进行标记,当其他线程调用这个变量发现版本号不一致,就更新自己的版本号,直到版本号一致才进行操作。
Atomic原子类
根据操作数据的类型,JUC包中的原子类分为四大类:基本数据类型、数组类型、引用类型以及对象属性修改类型。原子类主要利用 CAS 算法 + volatile 关键字+ native 方法来保证原子操作,从而避免 synchronized 的高开销,其中native方法是unsafe类,这就保证了多线程下使用原子类不要加锁就可实现线程安全,提高效率。Atomic原子类的具体使用方法和源码分析将会在日后有机会再进行解读(如果还有后文的话),提到原子类就不得不说原子操作的原理。
原子操作原理
处理器如何实现原子操作
处理器依靠总线+锁+缓存锁定机制来实现原子操作。 使用总线锁保证原子性,如果多个CPU同时对共享变量进行写操作(i++),缓存一致性以及内存屏障,通常无法得到期望的值。CPU使用总线锁来保证对共享变量写操作的原子性,当CPU在总线上输出lock信号时,其他CPU的请求将被阻塞住,于是该CPU可以独占共享内存。
使用缓存锁保证原子性,频繁使用的内存地址的数据会缓存于CPU的cache中,那么原子操作只需在CPU内部执行即可,不需要锁住整个总线。缓存锁是指在内存中的数据如果被缓存于CPU的cache中,并且在lock操作期间被锁定,那么当它执行锁操作写回到内存时,CPU修改内部的内存地址,并允许它的缓存一致性来保证操作的原子性,因为缓存一致性机制会阻止同时修改由两个以上处理器缓存的内存区域数据。当其他CPU回写被锁定的cache行数据时候,会使cache行无效。
Java如何实现原子操作
Java使用了锁和循环CAS的方式来实现原子操作。使用循环CAS实现原子操作,虚拟机的CAS操作使用了CPU提供的CMPXCHG指令来实现,自旋式CAS操作的基本思路是循环进行CAS操作直到成功为止(自旋式CAS会加大开销,它并不是线程唤醒机制)。
使用锁机制实现原子操作,锁机制保证了只有获得锁的线程才能给操作锁定的区域。虚拟机的内部实现了多种锁机制,除了偏向锁,其他锁的方式都使用了循环CAS,也就是当一个线程想进入同步块的时候,使用循环CAS方式来获取锁,退出时使用CAS来释放锁。
ConcurrentHashMap将会在本文之后进行源码解读(比对JDK1.7 和JDK1.8)
BlockingQueue(阻塞队列)
阻塞队列本质上是一个队列,具备队列的特性,同时提供了可阻塞的put和take方法,以及支持定时的offer和poll方法。如果队列已经满了,那么put方法将阻塞直到有空间可用;如果队列为空,那么take方法将会阻塞直到有元素可用。在构建高可靠的应用程序时,有界队列ArrayBlockingQueue是一种强大的资源管理工具:能抑制并防止产生过多的工作项,使应用程序在负荷过载的情况下变得更加健壮。在后面的线程池专题中还会对阻塞队列进行进一步阐述,发掘它的魅力(如果还有后文的话)。
信号量(Semaphore)
信号量用来控制同时访问某个特定资源的操作数量,或者同时执行某个指定操作的数量。Semaphore中管理着一组虚拟的许可permit,许可的初始数量可通过构造函数来指定。在执行操作时可以首先获得许可(只要还有剩余的许可),并在使用以后释放许可。如果没有许可,那么acquire将阻塞直到有许可(或者直到被中断或者操作超时),release方法将返回一个许可给信号量。计算信号量的一种简化形式是二值信号量,即初始值为 1 的Semaphore。二值信号量可以用作互斥体,并具备不可重入的加锁语义:谁拥有这个唯一的许可,谁就拥有了互斥锁。可以用于实现资源池,当池为空时,请求资源将会阻塞,直至存在资源,将资源返回给池之后会调用release释放许可。——————可以简单理解为生、消模式中的缓冲区,这样可能不会那么绕。
CyclicBarrier(循环屏障)
CyclicBarrier可以使一定数量的参与方反复地在栅栏位置汇集,它在并行迭代算法中非常有用;这种算法通常将一个问题拆分成一系列相互独立的子问题。当线程到达栅栏位置时将调用await方法,这个方法将阻塞直到所有线程都达到栅栏位置。如果所有线程都到达了栅栏位置,那么栅栏将打开,此时所有线程都被释放,而栅栏将被重置以便下次使用。如果对await方法的调用超时,或者await阻塞的线程被中断,那么栅栏就被认为是打破了,所有阻塞的await调用都被终止并抛出 BrokenBarrierException。如果成功通过栅栏,那么await将为每个线程返回一个唯一的到达索引号,我们可以利用这些索引来选举产生一个领导线程,并在下一次迭代中由该领导线程执行一些特殊的工作。CyclicBarrier还可以使你将一个栅栏操作传递给构造函数,这是一个Runnable,当成功通过栅栏时会在一个子任务线程中执行它。可以用于多线程计算数据,最后合并计算结果的场景。想象你在大草原,你有三五万头羊(这里就不要做梦,你没有三五万头羊)。假设有一个羊圈关了三千头羊,这三千头羊都积聚在围栏,准备去吃草。你去把栏门打开,在你没有打开栏门时,这些羊都在等待着。所有羊出去了,等羊回来,你把栏门关了。如果你一直不去打开栏门,羊饿疯了,要么羊跑了,要么羊死了。(看到这里请你从大草原醒过来)
CountDownLatch(闭锁)
闭锁可以延迟线程的进度直到其达到终止状态,闭锁的作用相当于一扇门:在闭锁到达结束状态之前,这扇门一直是关闭的,并且没有任何线程能通过,当到达结束状态时,这扇门会打开并允许所有的线程通过。当闭锁达到结束状态后,将不会再改变状态,因此这扇门将永远保持打开状态。闭锁可以用来确保某些活动指导其他活动都完成后才继续执行,闭锁状态包括一个计数器,该计数器被初始化为一个正数,表示需要等待的事件数量。countDown方法递减计数器,表示有一个事件发生了,而await方法等待计数器达到0,这表示所有需要等待的事件都已经发生。如果计数器的值非零,那么await会一直阻塞直到计数器为0,或者等待中的线程中断,或者等待超时。
CyclicBarrier和CountDownLatch二者比较
计数器使用方式不同:前者使用加计数方式,后者使用减数计数方式;释放所有等待线程时期不同:前者到达指定值释放 ,后者计算为0时释放;重置:前者计数到达指定时,计数从0开始,后者无法重置;调用方法影响:前者调用await()方法计数加1,若加1后的值不等于构 造方法的值,则线程阻塞,后者调用countDown()方法计数减一,调用 await()方法只进行阻塞,对计数没任何影 响,还有一点:前者可以重复利用,后者不可重复利用。
Condition
在前几篇文章中曾经指出ReentrantLock锁对象可以绑定多个condition对象,有关condition的更深入的解读,请参考这一篇文章:Java并发编程 -- Condition
Fork/Join 框架
在必要的情况下,将一个大任务,进行拆分(fork)成
若干个小任务(拆到不可再拆时),再将一个个的小任务运算的结果进
行 join 汇总。如下图
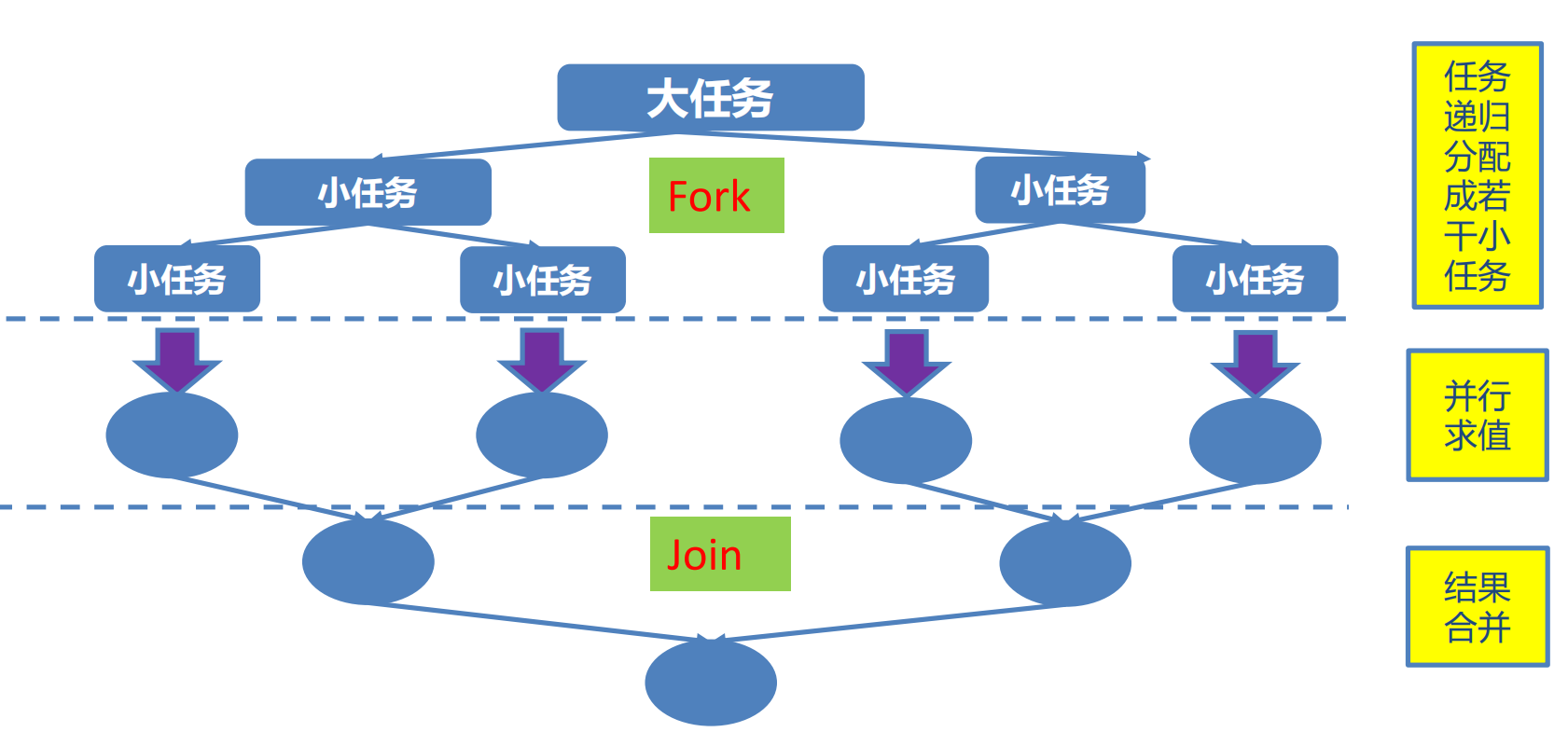
Fork/Join 框架与线程池的区别
1、 采用 “工作窃取”模式(work-stealing): 当执行新的任务时它可以将其拆分分成更小的任务执行,并将小任务加到线程队列中,然后再从一个随机线程的队列中偷一个并把它放在自己的队列中。 举个例子,戚继光的军队在和倭寇浪人大战时,进入到了巷战,此时将分成几个人的一个小组,那么小组的战斗也是整个战争的一部分,数百个小组在一条线上:断敌人后路或者包围,随时抽取一条线上的兵来补充主线战斗的兵。
2、相对于一般的线程池实现,fork/join框架的优势体现在对其中包含的任务的处理方式上.在一般的线程池中,如果一个线程正在执行的任务由于某些原因无法继续运行,那么该线程会处于等待状态。而在fork/join框架实现中, 如果某个子问题由于等待另外一个子问题的完成而无法继续运行。那么处理该子问题的线程会主动寻找其他尚未运行的子问题来执行,这种方式减少了 线程的等待时间,提高了性能。(对该知识点还有待深入,具体的任务执行有待进一步了解)
线程池(ThreadLocal Pool)
线程池是开发中很好的一个资源管理工具,本文将进行简单介绍,在下一篇文章中,将用比较生动的例子来说明线程池的相关知识。
线程池引入原因
1、任务处理过程从主线程中分离出来,使得主循环能够更快地重新等待下一个到来的连接;使得任务在完成前面的请求之前可以接受新的请求,从而提高响应性。
2、任务可以并行处理,从而能同时服务多个请求。如果有多个处理器,或者任务由于某种原因被阻塞,程序的吞吐量将得到提高。
无限制创建线程的不足:
1、线程生命周期的开销非常高,不断的创建,销毁带来线程的切换,影响效率;
2、资源消耗,创建线程是非常消耗资源;
3、稳定性
解决方式:线程池 Executor框架 (也有缺陷,后文给出)
使用线程池的好处:降低资源消耗、提高响应速度、提高线程的可管理性。
本文要是有遗漏的地方,我将在评论区给出,同时若读者发现本文不当之处也请在评论区指出,共同研究。
