

【JavaScript文本截取】该死的Emoji表情
emmm...公司微信小程序项目要求限制输入框的可输入文本长度!但是要求按字节数限制,而不是按字符数限制(可难为死我了😫)
一、什么是Emoji表情😆
绘文字(日语:絵文字/えもじ emoji)是日本在无线通信中所使用的视觉情感符号,绘指图画,文字指的则是字符,可用来代表多种表情,如笑脸表示笑、蛋糕表示食物等。在中国大陆,emoji通常叫做“小黄脸”,或者直称emoji
二、文字截取函数substr()、substring()
1.substr(start,length)
substr() 方法可在字符串中抽取从 start 下标开始的指定数目的字符。
2.substring(start,stop)
substring() 方法用于提取字符串中介于两个指定下标之间的字符。
三、使用文字截取函数截取文本(常规方式)
function test1(str, len) {
return str.substr(0, len);
}
function test2(str, len) {
return str.substring(0, len);
}
let str = "123你好";
console.log(test1(str, 4)); // 123你
console.log(test2(str, 4)); // 123你
从上面的代码上来看是完全没有问题的,一但加上emoji表情就炸了
str = "123👩🦱你好";
console.log(test1(str, 4)); // 123�
console.log(test2(str, 4)); // 123�
console.log(test1(str, 6)); // 123👩
console.log(test1(str, 8)); // 123👩🦱
再加个特殊中文试试“𠮷”
str = "123𠮷你好";
console.log(test1(str, 4)); // 123�
console.log(test2(str, 4)); // 123�
console.log(str.length); // 7
是的,就是这么奇葩。
由于javascript使用但是usc-2的编码,对于2个字节字符的Unicode,js是解析起来66的。但是会有以下问题
- 不常用字符,比如"𠮷"或者某些emoji表情(或者组合表情👩+🦱=👩🦱)占用3个或更多字节。
- javascript会将一个多字节字符识别成多个字符😱(看上面代码的最后一句str.length等于7)。
- 在某些场景下如果字符截取不完整会直接抛出异常😳😮😯😦😧😨😰😱😇
四、解决思路
秉持面向
百度编程的宗旨。啊呸...
- 将文本转换成Unicode十六进制
- 手动分割字符
- 完成
遇到的问题1
String.charCodeAt()和String.fromCharCode()也只支持处理两个字节的字符😏
str = "𠮷";
console.log(str.charCodeAt(0)); // 55362
console.log(String.fromCharCode(str.charCodeAt(0))); // �
解决办法
使用ES6的新特性String.fromCodePoint()和String.codePointAt()代替String.charCodeAt()和String.fromCharCode()
str = "𠮷";
console.log(str.codePointAt(0)); // 134071
console.log(String.fromCodePoint(str.codePointAt(0))); // 𠮷
遇到的问题2
对于组合字符如何区分
str = "𠮷👩🦱";
function strToUnicode(str) {
var result = "";
for (var i = 0; i < str.length; i++) {
var code = str.codePointAt(i).toString(16);
result += `\\u\{${code}\}`;
if (code.length > 4) {
i++;
}
}
return result;
}
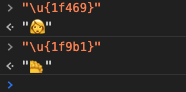
console.log(strToUnicode(str)); // \u{20bb7}\u{1f469}\u{200d}\u{1f9b1}
从上面的代码中可以看到输入两个字符但是输出4个字符的Unicode编码,因为组合表情本质上就是多个表情
秉持面向百度编程的宗旨。啊呸...
解决办法
由于👩+🦱=👩🦱,通过对比下面这个图可以发现 \u{1f469}+\u{1f9b1}=\u{1f469}\u{200d}\u{1f9b1}
然后 秉持面向百度编程的宗旨。啊呸...得出结论,组合表情会通过\u{200d}进行连接,
也就是说如果遇到\u{200d}表示\u{200d}的前一个字符和\u{200d}和\u{200d}的后一个字符是一个符号组合(特别注意连接符的前一个和后一个字符一定是大于两个字节的字符)
解决思路:
- 将文本转换成Unicode十六进制(可以存为数组,也可以存储为“\u{十六进制}”,后面这种方法js的表示转义表示方法)
- 循环数组,如果十六进制长度是1-2表示是一个字节,是3-4则表示是2个字节大于4表示3个字节(一般不会有5个字节,组合字符除外)
- 如果在第2步循环中遇到200d则表示下一次循环字符和上一次循环字符是组合字符(将他们存储到一起)
- 在第2步循环时统计长度,将长度和得到的十六进制存储到数组
- 循环得到的数组,如果长度相加小于给定的长度则将16进制转成文本追加到结果变量,否则跳出循环
五、完整代码
公用代码(因为我为了简化代码,最终写了几个版本)
/* 通过文字二进制得到文字字节数 */
function getByteByBinary(binaryCode) {
/**
* 二进制 Binary system,es6表示时以0b开头
* 八进制 Octal number system,es5表示时以0开头,es6表示时以0o开头
* 十进制 Decimal system
* 十六进制 Hexadecimal,es5、es6表示时以0x开头
*/
var byteLengthDatas = [0, 1, 2, 3, 4];
var len = byteLengthDatas[Math.ceil(binaryCode.length / 8)];
return len;
}
/* 通过文字十六进制得到文字字节数 */
function getByteByHex(hexCode) {
return getByteByBinary(parseInt(hexCode, 16).toString(2));
}
第一版写法 (不推荐,这里是我最开始的思路,也就是上面说的思路)
function strToUnicodeArray(str) {
var result = [];
var flag = false;
var temp = "";
var len = 0;
for (var i = 0; i < str.length; i++) {
var code = str.codePointAt(i).toString(16); // 转为十六进制
if (code.length > 4) { // 判断是否是两个字节以上
i++;
if ((i + 1) < str.length) { // 判断下一个字符是否是连接符200d
flag = str.codePointAt(i + 1).toString(16) == "200d";
}
}
if (flag) { // 如果下一个字符是连接符200d,将当前字符保存到临时变量
temp = temp + `\\u{` + code + `}`;
len += getByteByHex(code);
if (i == str.length - 1) { // 这里是为了防止最后一个字符是组合字符时出现结果未存储的问题
result.push({
value: temp,
length: len
});
}
} else { // 如果下一个字符不是连接符200d
if (temp != "") { // 当temp不等于空时,代表当前字符是组合字符的一部分,所以需要将当前字符加入临时变量,又因为下一个字符不是连接符200d,所以表示组合字符完毕,将结果存储,清空临时变量
temp = temp + `\\u{` + code + `}`;
len += getByteByHex(code);
result.push({
value: temp,
length: len
});
temp = "";
len = 0;
} else { // 将结果存储,当前字符又不是组合字符的一部分所以直接存储
result.push({
value: `\\u{` + code + `}`,
length: getByteByHex(code)
});
}
}
}
return result;
}
function substringByByte(str, maxLength) {
var datas = strToUnicodeArray(str);
console.log(datas)
var len = 0;
var result = "";
for (var i in datas) {
len += datas[i].length;
if (len <= maxLength) {
if (datas[i].length >= 5) {
var value = datas[i].value.replace(/{/g, "").replace(/}/g, "").split("\\u").slice(1);
for (var j in value) {
value[j] = parseInt(value[j], 16)
}
result += String.fromCodePoint(...value);
} else {
var value = datas[i].value.replace(/\\u/g, "").replace(/{/g, "").replace(/}/g, "");
result += String.fromCodePoint(parseInt(value, 16));
}
} else {
break;
}
}
return result;
}
第二版写法 (推荐,这里是我第一版的优化)
这一版我使用js的转义表示方法存储数据,然后直接通过正则表达式分割每个字符,这样就不用在循环里写很多处理组合字符的逻辑了
/* 字符串转Unicode十六进制 */
function strToUnicode(str) {
var result = "";
for (var i = 0; i < str.length; i++) {
var code = str.codePointAt(i).toString(16);
result += `\\u\{${code}\}`;
if (code.length > 4) {
i++; // 由于str.length也只能处理两个字节的文字,所以这里需要判断如果codePointAt得到多字符就得跳过一次循环
}
}
return result;
}
/* 截取指定字符数长度的文本 如果后一个字符截取后超出指定的长度,将不会截取该字符 */
function substringByByte2(str, maxLength) {
var data = strToUnicode(str);
var reg = new RegExp(/\\u\{[A-z0-9]+\}(\\u\{200d\}{1}\\u\{[A-z0-9]+\})*/, 'g');// 使用正则表达式分割每个完整字符
var datas = reg[Symbol.match](data);
var result = "";
var length = 0;
for (var i in datas) {
var value = datas[i].split("\\u").slice(1);
// var len = 0;
value = value.map(str => {
var value = str.replace(/\\u/g, "").replace(/{/g, "").replace(/}/g, "");
length += getByteByHex(value);
return parseInt(value, 16);
});
if (length <= maxLength) {
result += String.fromCodePoint(...value);
} else break;
}
return result;
}
第三版写法 (推荐)
由于前两种写法需要现将文本转为十六进制,然后再循环截取
在遇到原始文本较大而截取长度较小时,性能上就会特别差(如: 10000长度的字符串截取5个长度)
所以第三版我直接一边转十六进制一边判断长度并截取,这样超出需要截取长度的文本就不会被处理
function substringByByte3(str, maxLength) {
var result = "";
var flag = false;
var len = 0;
var length = 0;
var length2 = 0;
for (var i = 0; i < str.length; i++) {
var code = str.codePointAt(i).toString(16);
if (code.length > 4) {
i++;
if ((i + 1) < str.length) {
flag = str.codePointAt(i + 1).toString(16) == "200d";
}
}
if (flag) {
len += getByteByHex(code);
if (i == str.length - 1) {
length += len;
if (length <= maxLength) {
result += str.substr(length2, i - length2 + 1);
} else {
break
}
}
} else {
if (len != 0) {
length += len;
length += getByteByHex(code);
if (length <= maxLength) {
result += str.substr(length2, i - length2 + 1);
length2 = i + 1;
} else {
break
}
len = 0;
continue;
}
length += getByteByHex(code);
if (length <= maxLength) {
if (code.length <= 4) {
result += str[i]
} else {
result += str[i - 1] + str[i]
}
length2 = i + 1;
} else {
break
}
}
}
return result;
}
六、运行测试
let str = "123👩🦱你好";
console.log(substringByByte(str, 4)); // 123
console.log(substringByByte2(str, 6)); // 123
console.log(substringByByte2(str, 10)); // 123👩🦱
console.log(substringByByte2(str, 11)); // 123👩🦱
console.log(substringByByte3(str, 13)); // 123👩🦱你
程序员最讨厌的四件事:写注释、写文档、别人不写注释、别人不写文档(所以我的代码也没有注释😜).
当然还有很多失败的版本我就不放出来了😭
