

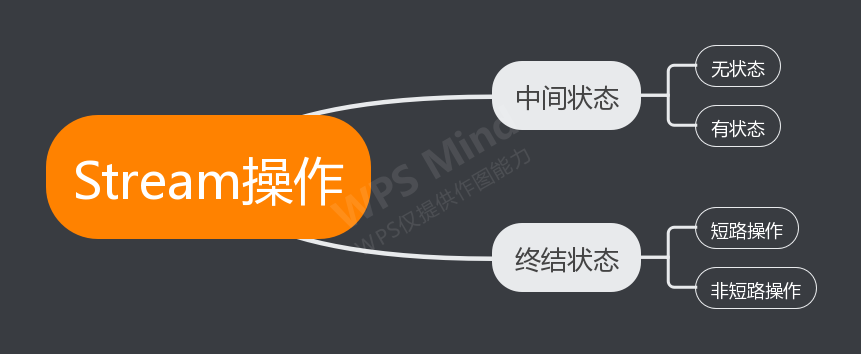
Stream操作分类
中间操作
中间操作只对操作进行了记录,即只会返回一个流,不会进行计算操作。中间操作可以分为有状态和无状态两种情况:
- 有状态:元素的处理必需要拿到前面所有的元素才能够进行下去。
- 无状态:元素的处理不会受到前面元素的影响。
终结操作
终结操作会进行计算操作。终结操作又可以分为短路操作和非短路操作。前者是指遇到某些符合条件的元素就可以得到最终值。后者是指必须取得所有元素元素后才能得到最终值。
Stream源码实现
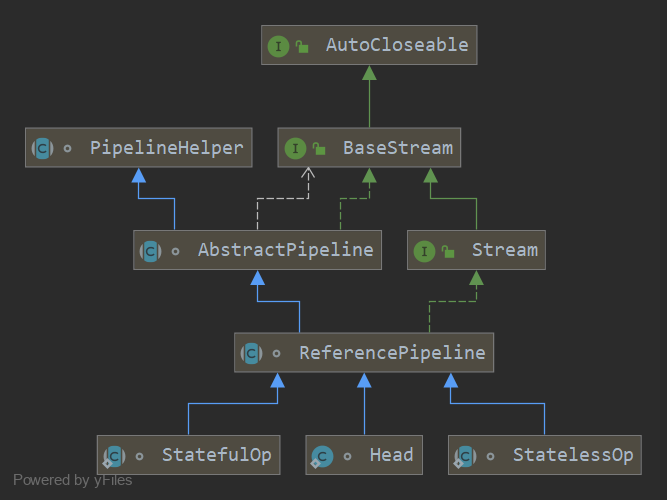
BaseStream和Stream是最顶层的类。BaseStream中定义了流的一些基本方法,Stream中定义了流的一些常用操作,如map,filter等。
ReferencePipeline 是一个结构类,他通过定义内部类组装了各种操作流。他定义了 Head、StatelessOp、StatefulOp 三个内部类,实现了 BaseStream 与 Stream 的接口方法。
Stream操作叠加
我们知道,一个 Stream 的各个操作是由处理管道组装,并统一完成数据处理的。在 JDK 中每次的中断操作会以使用阶段(Stage)命名。
管道结构通常是由 ReferencePipeline 类实现的,前面讲解 Stream 包结构时,我提到过 ReferencePipeline 包含了 Head、StatelessOp、StatefulOp 三种内部类。
Head 类主要用来定义数据源操作,在我们初次调用 names.stream() 方法时,会初次加载 Head 对象,此时为加载数据源操作;接着加载的是中间操作,分别为无状态中间操作 StatelessOp 对象和有状态操作 StatefulOp 对象,此时的 Stage 并没有执行,而是通过 AbstractPipeline 生成了一个中间操作 Stage 链表;当我们调用终结操作时,会生成一个最终的 Stage,通过这个 Stage 触发之前的中间操作,从最后一个 Stage 开始,递归产生一个 Sink 链。
List<String> names = Arrays.asList(" 张三 ", " 李四 ", " 王老五 ", " 李三 ", " 刘老四 ", " 王小二 ", " 张四 ", " 张五六七 ");
String maxLenStartWithZ = names.stream()
.filter(name -> name.startsWith(" 张 "))
.mapToInt(String::length)
.max()
.toString();
首先会调用集合的stream方法
/**
* Returns a sequential {@code Stream} with this collection as its source.
*
* <p>This method should be overridden when the {@link #spliterator()}
* method cannot return a spliterator that is {@code IMMUTABLE},
* {@code CONCURRENT}, or <em>late-binding</em>. (See {@link #spliterator()}
* for details.)
*
* @implSpec
* The default implementation creates a sequential {@code Stream} from the
* collection's {@code Spliterator}.
*
* @return a sequential {@code Stream} over the elements in this collection
* @since 1.8
*/
default Stream<E> stream() {
return StreamSupport.stream(spliterator(), false);
}
然后,Stream 方法就会调用 StreamSupport 类的 Stream 方法,方法中初始化了一个 ReferencePipeline 的 Head 内部类对象:
/**
* Creates a new sequential or parallel {@code Stream} from a
* {@code Spliterator}.
*
* <p>The spliterator is only traversed, split, or queried for estimated
* size after the terminal operation of the stream pipeline commences.
*
* <p>It is strongly recommended the spliterator report a characteristic of
* {@code IMMUTABLE} or {@code CONCURRENT}, or be
* <a href="../Spliterator.html#binding">late-binding</a>. Otherwise,
* {@link #stream(java.util.function.Supplier, int, boolean)} should be used
* to reduce the scope of potential interference with the source. See
* <a href="package-summary.html#NonInterference">Non-Interference</a> for
* more details.
*
* @param <T> the type of stream elements
* @param spliterator a {@code Spliterator} describing the stream elements
* @param parallel if {@code true} then the returned stream is a parallel
* stream; if {@code false} the returned stream is a sequential
* stream.
* @return a new sequential or parallel {@code Stream}
*/
public static <T> Stream<T> stream(Spliterator<T> spliterator, boolean parallel) {
Objects.requireNonNull(spliterator);
return new ReferencePipeline.Head<>(spliterator,
StreamOpFlag.fromCharacteristics(spliterator),
parallel);
}
再调用 filter 和 map 方法,这两个方法都是无状态的中间操作,所以执行 filter 和 map 操作时,并没有进行任何的操作,而是分别创建了一个 Stage 来标识用户的每一次操作。
@Override
public final Stream<P_OUT> filter(Predicate<? super P_OUT> predicate) {
Objects.requireNonNull(predicate);
return new StatelessOp<P_OUT, P_OUT>(this, StreamShape.REFERENCE,
StreamOpFlag.NOT_SIZED) {
@Override
Sink<P_OUT> opWrapSink(int flags, Sink<P_OUT> sink) {
return new Sink.ChainedReference<P_OUT, P_OUT>(sink) {
@Override
public void begin(long size) {
downstream.begin(-1);
}
@Override
public void accept(P_OUT u) {
if (predicate.test(u))
downstream.accept(u);
}
};
}
};
}
@Override
public final IntStream mapToInt(ToIntFunction<? super P_OUT> mapper) {
Objects.requireNonNull(mapper);
return new IntPipeline.StatelessOp<P_OUT>(this, StreamShape.REFERENCE,
StreamOpFlag.NOT_SORTED | StreamOpFlag.NOT_DISTINCT) {
@Override
Sink<P_OUT> opWrapSink(int flags, Sink<Integer> sink) {
return new Sink.ChainedReference<P_OUT, Integer>(sink) {
@Override
public void accept(P_OUT u) {
downstream.accept(mapper.applyAsInt(u));
}
};
}
};
}
当执行 max 方法时,会调用 ReferencePipeline 的 max 方法,此时由于 max 方法是终结操作,所以会创建一个 TerminalOp 操作,同时创建一个 ReducingSink,并且将操作封装在 Sink 类中。
@Override
public final OptionalInt max() {
return reduce(Math::max);
}
最后,调用 AbstractPipeline 的 wrapSink 方法,该方法会调用 opWrapSink 生成一个 Sink 链表,Sink 链表中的每一个 Sink 都封装了一个操作的具体实现。
@Override
final <P_IN> void copyInto(Sink<P_IN> wrappedSink, Spliterator<P_IN> spliterator) {
Objects.requireNonNull(wrappedSink);
// 非短路操作
if (!StreamOpFlag.SHORT_CIRCUIT.isKnown(getStreamAndOpFlags())) {
wrappedSink.begin(spliterator.getExactSizeIfKnown());
spliterator.forEachRemaining(wrappedSink);
wrappedSink.end();
}
// 短路操作
else {
copyIntoWithCancel(wrappedSink, spliterator);
}
}
Stream并行处理
在创建stram时指定.parallel()方法
List<String> names = Arrays.asList(" 张三 ", " 李四 ", " 王老五 ", " 李三 ", " 刘老四 ", " 王小二 ", " 张四 ", " 张五六七 ");
String maxLenStartWithZ = names.stream()
.parallel()
.filter(name -> name.startsWith(" 张 "))
.mapToInt(String::length)
.max()
.toString();
Stream 的并行处理在执行终结操作之前,跟串行处理的实现是一样的。而在调用终结方法之后,实现的方式就有点不太一样,会调用 TerminalOp 的 evaluateParallel 方法进行并行处理。
/**
* Evaluate the pipeline with a terminal operation to produce a result.
*
* @param <R> the type of result
* @param terminalOp the terminal operation to be applied to the pipeline.
* @return the result
*/
final <R> R evaluate(TerminalOp<E_OUT, R> terminalOp) {
assert getOutputShape() == terminalOp.inputShape();
if (linkedOrConsumed)
throw new IllegalStateException(MSG_STREAM_LINKED);
linkedOrConsumed = true;
return isParallel()
? terminalOp.evaluateParallel(this, sourceSpliterator(terminalOp.getOpFlags()))
: terminalOp.evaluateSequential(this, sourceSpliterator(terminalOp.getOpFlags()));
}
总结
在串行处理中,Stream 在执行每一步中间操作时,并不会做实际的数据操作处理,而是将这些中间操作串联起来,最终由终结操作触发,生成一个数据处理链表,通过 Java8 中的 Spliterator 迭代器进行数据处理;此时,每执行一次迭代,就对所有的无状态的中间操作进行数据处理,而对有状态的中间操作,就需要迭代处理完所有的数据,再进行处理操作;最后就是进行终结操作的数据处理。
在并行处理中,Stream 对中间操作基本跟串行处理方式是一样的,但在终结操作中,Stream 将结合 ForkJoin 框架对集合进行切片处理,ForkJoin 框架将每个切片的处理结果 Join 合并起来。最后就是要注意 Stream 的使用场景。
