

前两天小帅b跟你说了说分布式爬虫
在里面我就说到
弄个例子来体现一下分布式爬虫

在此之前
我们可以先写一个单机版的爬虫
往后再对其修改一些配置
就可以搞成分布式的了
所以这次我们先爬取 stackoverflow 上的所有 Python 问答

那么接下来就是
学习 Python 的正确姿势

别问我为什么不爬取国内的网站

打开
https://stackoverflow.com/questions/tagged/python
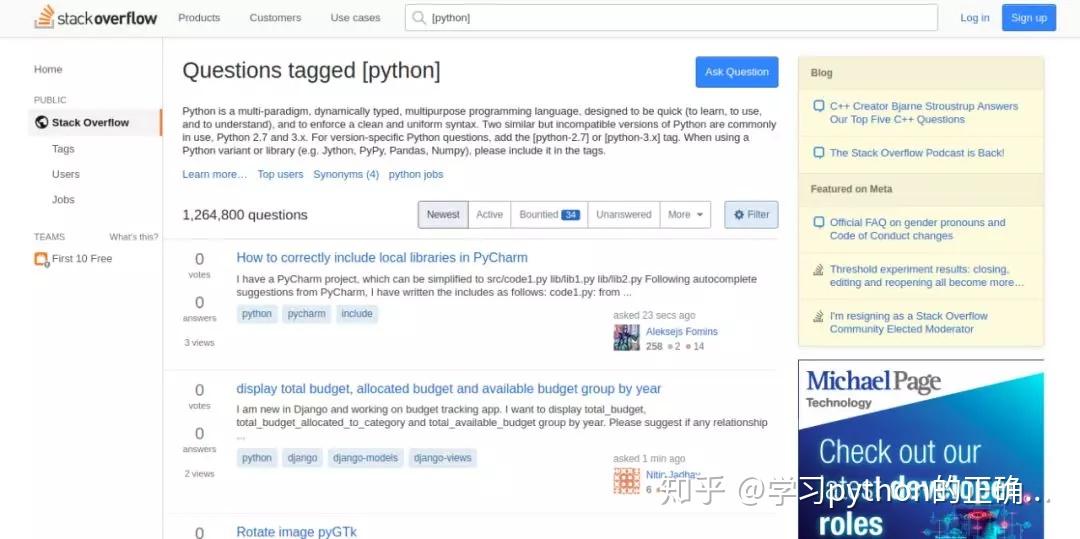
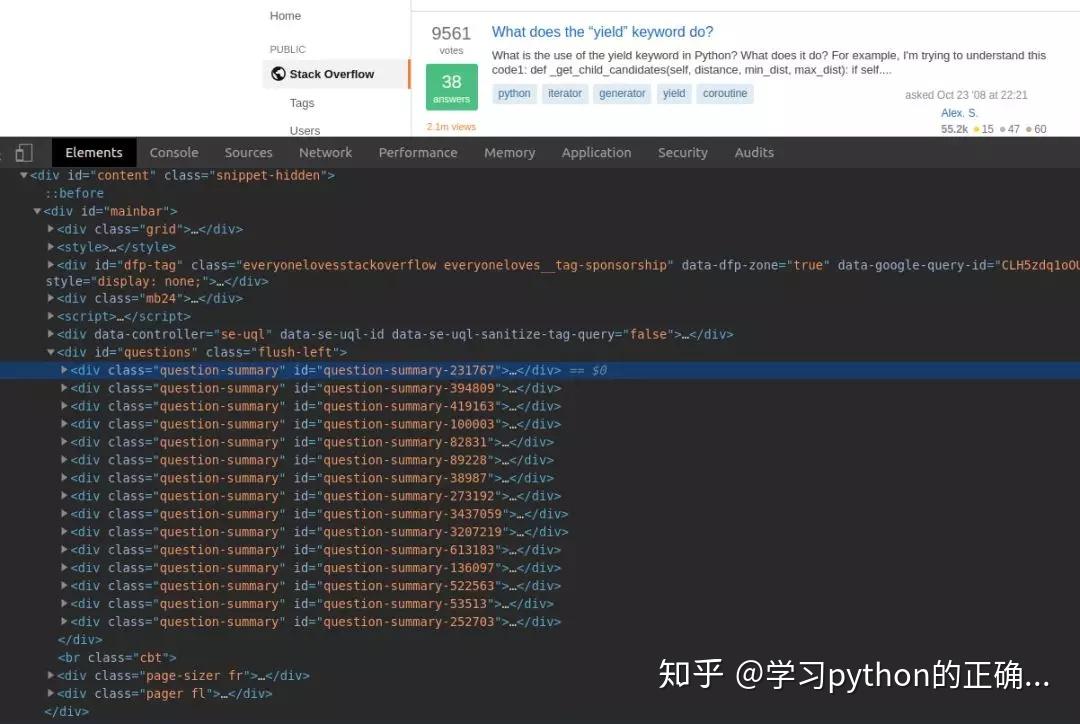
简单分析一下这个页面
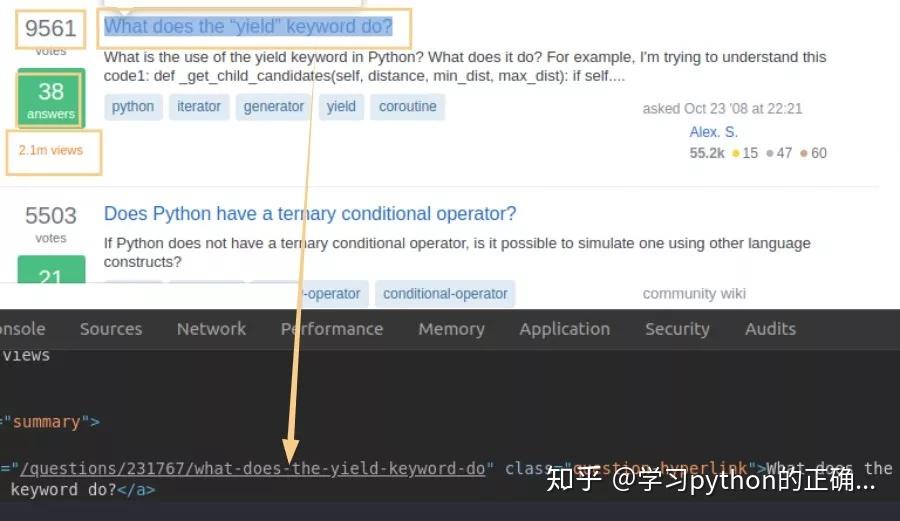
我们就去抓取每一个 item 里面的
问题votes
answersviews
链接
待会根据 xpath 获取就可以了
那我们先创建一个工程吧


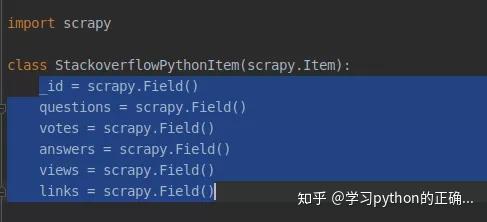
打开 items.py 定义一下我们要获取的字段
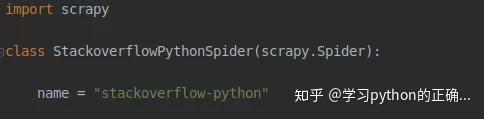
接着在 spider 创建一个文件我们就叫做stackoverflow-python-spider.py
创建一个继承 scrapy 的 spider 类
接着定义一下请求链接的方法在这里我们可以看到每个页面的请求链接是这样的

那么我们可以这样构建
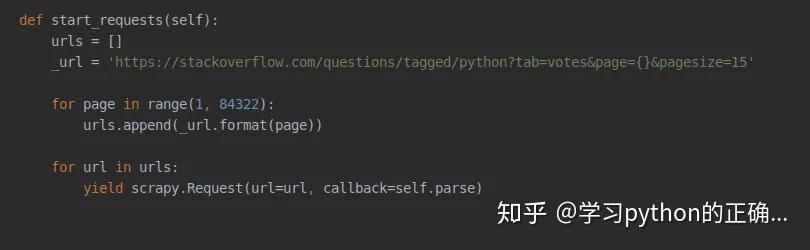
接着我们定义一下回调的解析方法
根据每个元素的 xpath和我们刚刚定义的字段结合起来
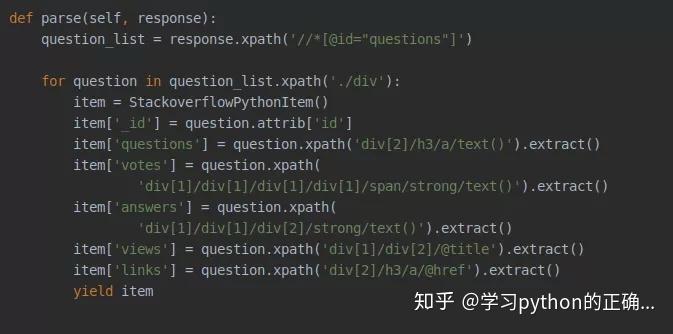
接着就可以在 pipelines 中
配置链接数据库了这里我们使用 MongoDB

主要是初始化的时候链接数据库在解析过程把数据和保存到数据库
在 settings 中需要配置下

顺便配置一下“狗头”

当然如果你的破网访问不了
stackoverflow 的话
自行设置下代理
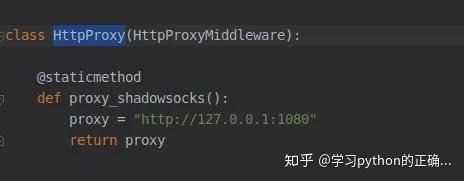
最后开启你的 MongoDB
执行以下命令开始爬取
scrapy crawl stackoverflow-python
这样就把数据爬取到你的数据库了

ok
以上就是本次分享的内容希望对你有帮助
如果你需要源码的话可以在公众号【学习python的正确姿势】后台发送 “111” 获取
下次我们继续盘它那么我们下回见了peace

扫一扫
学习 Python 没烦恼

