

前言
上一篇 【阅读整理】正则表达式 - 基础篇 介绍了构建正则的各个零部件们。在思考篇,我们继续深入,讲讲:
- JavaScript正则引擎的搜索机制
- 如何读一个正则
- 如何写一个正则
作为补充啦~ Just have fun!!!
JavaScript正则引擎的搜索机制
“脱颖而出”的传统型NFA
JavaScript的正则引擎是传统型NFA,NFA是“非确定型有限自动机”的简写,另外还有DFA(“确定型有穷自动机”)、POSIX NFA(符合POSIX标准的NFA引擎)。
(这块没深入了解,从同事那儿搬运个有意思的例子能来说明问题🙏👀)
举这个例子: /to(nite|knight|night)/.exec(‘aatonightbbb’)
-
如果是DFA:
- 文本主导,手里握着文本,眼睛看着表达式,逐个字符匹配。当匹配到
n的时候,发现nite|knight|night之中knight的k不匹配,舍弃knight,匹配nite和night;当匹配到g的时候发现nite的t不匹配,舍弃nite,匹配night……直到输出匹配结果tonight。
- 文本主导,手里握着文本,眼睛看着表达式,逐个字符匹配。当匹配到
-
如果是传统型DFA:
- 表达式主导,手里握着正则表达式,眼睛看着文本,逐个字符匹配。当匹配到
t后,匹配紧随其后的文本是否是o,接着存在 3 种可能(nite|knight|night),先取第一个子表达式nite,匹配到t的时候,发现文本是g,不匹配,放弃nite,进行knight…以此类推,直到匹配到第三个night子表达式完成匹配,输出结果tonight。
- 表达式主导,手里握着正则表达式,眼睛看着文本,逐个字符匹配。当匹配到
-
如果是POSIX NFA:
- 表达式主导,特点是尽可能地在回溯过程中匹配最长的结果,换一个可区别的例子:
/(acc|accdee)/.exec("accdeefff”); // NFA 匹配结果 acc // POSIX NFA 匹配结果 accdee
图示差异:

?的惰性匹配,尽可能少的匹配)
大部分语言中的正则都是NFA,为啥它这么流行呢?
答:你别看我匹配慢,但是我编译快啊。
回溯
上一小节其实偷偷涉及到了回溯,如果没看明白呢,这一小节对此做一个解释!
拿正则/ab{1,3}c/去匹配abbc:
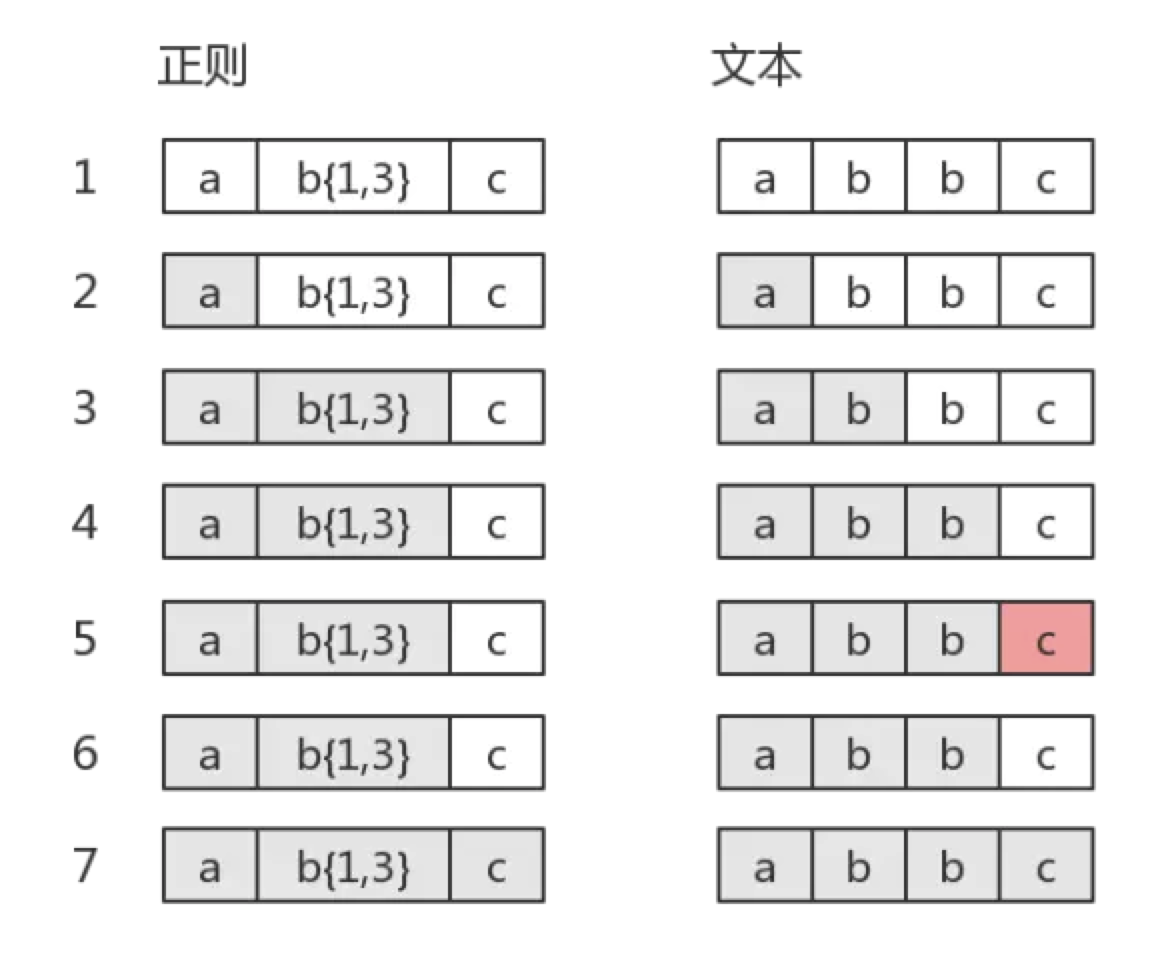
在第五步,因为默认的贪婪匹配,表达式贪婪量词这里多吃了一个b,但是匹配文本失败,就得吐出这个b,再接着去匹配表达式后面的内容。
除了贪婪匹配过程中会发生回溯以外,常见的回溯形式还会发生在:
- 惰性匹配:表达式惰性量词这里最初只吃一个
\d,$结束位置符,导致表达式后面的内容无法匹配文本了,匹配失败,回溯到惰性量词这里再多吃一个\d,匹配成功
var string = "12345";
var regex = /^(\d{1,3}?)(\d{1,3})$/;
console.log( string.match(regex) );
// => ["12345", "12", "345"]
- 分支结构:表达式分支结构顺序在前的优先去匹配(这里的
can),但是因为^和$导致匹配失败,回溯到分支结构的第二个选项candy,发生回溯
var string = ‘candy’;
var regex = /^(?:can|candy)$/
console.log( string.match(regex) );
// => [“candy”]
贪婪匹配与惰性匹配
贪婪匹配与惰性匹配应该已经很熟悉了🤦♂️,这里给个典型例子。
需求:找到字符串中双引号内的内容,比如'a "witch” and her “broom” is one’,找出witch和broom。
很自然而然地想到了下面正则,然而贪婪匹配是原罪,/".+"/g尽可能地吃阿吃,吃成了结果”witch” and her “broom”
let regexp = /“.+"/g;
let str = ‘a “witch” and her “broom” is one’;
alert( str.match(regexp) ); // “witch” and her “broom”
那怎么办呢?开启惰性匹配,少吃点,我的表达式!
let regexp = /“.+?"/g;
let str = ‘a “witch” and her “broom” is one’;
alert( str.match(regexp) ); // witch, broom
其实还有替换方案,不需要开启惰性匹配:显示排除双引号内不能在带有双引号
let regexp = /“[^"]+"/g;
let str = ‘a “witch” and her “broom” is one’;
alert( str.match(regexp) ); // witch, broom
读一个正则
哎,当遇到一个复杂的正则,怎样快速读懂它呢?
当然是二话不说扔可视化工具 ,一目了然哎!
但…如果没发用可视化工具,又或者在可视化一个正则后,又想更多了解一下细节,怎么自力更生呢?
这涉及到正则表达式的拆分,也就是优先级,优先级从高到低:
- 转义符
\ - 括号和方括号:
(…)(非捕获分组、环视)、[…] - 量词限定符:
{m,n}、?、+、* - 位置和一般字符
- 管道符:
|
比如/ab?(c|de*)+|fg/:
- 由于括号的存在,所以,
(c|de*)是一个整体结构; - 在
(c|de*)中,注意其中的量词*,因此e*是一个整体结构; - 又因为分支结构
|优先级最低,因此c是一个整体、而de*是另一个整体; - 同理,整个正则分成了
a、b?、(...)+、f、g。而由于分支的原因,又可以分成ab?(c|de*)+和fg这两部分
写一个正则
那怎么去构建一个正则呢?
构建正则前提
等等…等等!先从前往后想一想这几个问题:
- 是否能构建正则解决问题:比如
1010010001….虽然很有规律,但它的量词是动态的,正则无法解决这个问题; - 是否有必要使用正则:JavaScript丰富的String API是不是已经可以解决问题?
- 好了,那去构建一个正则吧,但是否有必要构建一个复杂的正则 比如密码匹配问题,要求密码长度6-12位,由数字、小写字符和大写字母组成,但必须至少包括2种字符。
//一个正则
var regexHuge = /(?!^[0-9]{6,12}$)(?!^[a-z]{6,12}$)(?!^[A-Z]{6,12}$)^[0-9A-Za-z]{6,12}$/
//切分多个正则
var regex1 = /^[0-9A-Za-z]{6,12}$/;
var regex2 = /^[0-9]{6,12}$/;
var regex3 = /^[A-Z]{6,12}$/;
var regex4 = /^[a-z]{6,12}$/;
function checkPassword(string) {
if (!regex1.test(string)) return false;
if (regex2.test(string)) return false;
if (regex3.test(string)) return false;
if (regex4.test(string)) return false;
return true;
}
准确性
我们开始去构建一个正则表达式,最最基本的是它的准确性,准确性体现在两方面:
- 匹配预期的字符串
- 不匹配非预期的字符串
确保准确性有一个方法论:
- 枚举可能出现类型
- 提取公共部分
举个例子,要求匹配如下格式的浮点数:
1.23、+1.23、-1.23
10、+10、-10
.2、+.2、-.2
正则会由3部分组成:
- 符号部分:
[+-] - 整数部分:
\d+ - 小数部分:
\.\d+
所以对应的3种情况:
- 要匹配1.23、+1.23、-1.23,可以用
/^[+-]?\d+\.\d+$/ - 要匹配10、+10、-10,可以用
/^[+-]?\d+$/ - 要匹配.2、+.2、-.2,可以用
/^[+-]?\.\d+$/
提取公共部分后是:/^[+-]?(\d+\.\d+|\d+|\.\d+)$/
(虽然好像挺傻的,但保证了准确性)
简洁一下: /^[+-]?(\d+)?(\.)?\d+$/
效率
在保证准确性的前提,才会去考虑效率、做优化。大多数情况是不需要优化的,除非运行的非常慢。
参考链接我甩这里:正则表达式的构建-效率
摘两个实践性较高的:
- 当不需要使用分组引用和反向引用时,使用非捕获分组:捕获分组和分支里的数据是需要内存的;
- 使用具体型字符组来代替通配符,来消除回溯;(参照找到字符串中双引号内的内容的正则,使用具体型字符组的
/“[^"]+"/g)
总结
开始接触正则,是因为正则不仅属于前端,它是CS专业的一个基本素养,有提高这方面素养的考虑。现在走了一遍理论和很多demo,接下来关键还是在遇到相关问题时候,敢于用正则去解决问题,多实践!
正则这块,老姚的教程看了还几遍,还有其他一些零散的文章,形成了这两篇 读书笔记。朋友们时间充裕的话,还是建议去看下老姚的教程(链接在末尾),再来看这两篇拙略的读书笔记。嘿嘿,欢迎交流。
