

本文来自道招网《Javascript保留格式翻译选区内容及预览(一)》原创
目前市面上的不少翻译,一般场景比较简单,都是纯文本翻译(可能会包含换行\n之类的),但是最近遇到一个需求是要实现富文本里面的翻译,这里的翻译很大的概率会有格式,比如这种


Selection Range
常用的方法就是window.getSelection()以及window.getSelection().getRangeAt(),具体的用法大家可以参看MDN,这里主要说下里面的坑。
怎么保留样式
首先大家想到的是如果里面有复杂样式,比如选区的文字有加粗、颜色什么的,选区里面还有图片啊,更深一层讲的话可能就是有里面会还有class、style、img之类的,怎么过滤呢?其实我们这样看还只是看到的是视觉层面的东西,我们应该看里面都是一个个的element node:text,我们所谓的保留格式替换,其实也只是更换里面的文字内容信息即可,其它只有不是一股脑全换掉,就实现了我们的目标了。
怎么找到需要替换的文字
其实使用window.getSelection().toString()能获取到选择的文字,但是这种方式类似innerText获取的是当前节点及其字节的文字,所以会丢失层级关系。
根据我们的需求我们要使用的是遍历对应的dom节点的方法。常用的获取子节点的属性有两个:
children返回的是HTMLCollection,不包含textNodechildNodes返回的是NodeList,包含textNode
以下面的代码为例
<h2 class="lg_loginbox_title" id="logintitle">携程账号登录<a href="https://passport.ctrip.com/user/member/fastOrder" class="login_phone_number getOrder">手机号查单<i>></i></a></h2>
我们分别根据上述方式看看返回
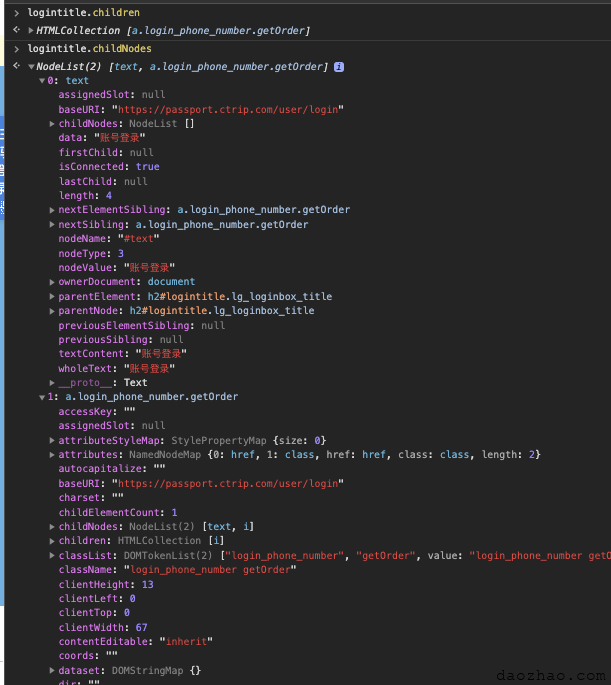
childNodes。
既然遍历,就需要知道入口,我们从哪里开始遍历呢?
这就要用到前面说的Range了。
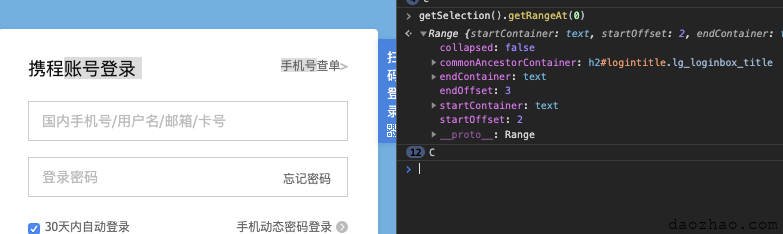
我们以这样的选区为例,我们模板就是获取到“账号登录”和“手机号”这几个文字并实现替换。

widow.getSelection().getRangeAt(0).cloneContents(),目前我们都是只有一个选区,所以用getRangeAt(0)获取第一个选区的Range。

class,style以及层级结构都保留了,这个API为我们做了很大贡献。
我们直接遍历它就能获取到选区的所有文字了,我们就按照深度遍历来将选区内的文字放到一个数组里面。我们就可以将数组['账号登录', '手机号']进行翻译得到['account login', 'phone number']。
怎么将翻译好的文字替换到原来位置
这就需要我们找到选区在当前dom的位置了,这时我们还是看看Range了
window.getSelection.getRangeAt(0).commonAncestorContainer返回的是选区的节点的最近一层的共同父节点。
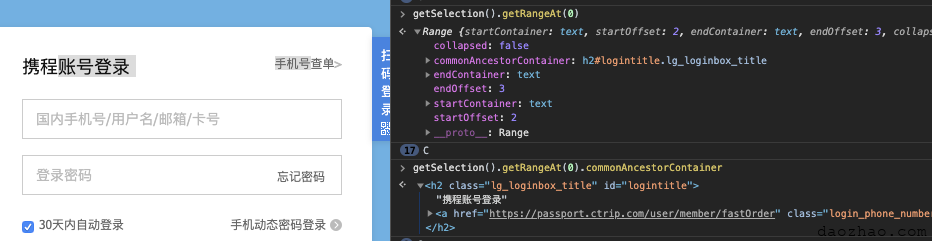
h2里面,的确如此。
现在唯一的难点就是怎么找到文字的起始位置了,如果像我们上面的选区那样,用户选取的只是文字的一部分怎么办,比如“携程账号登录”只选取“账号登录”,“手机号查单”只选取“手机号”。
我们有两个办法可以做到
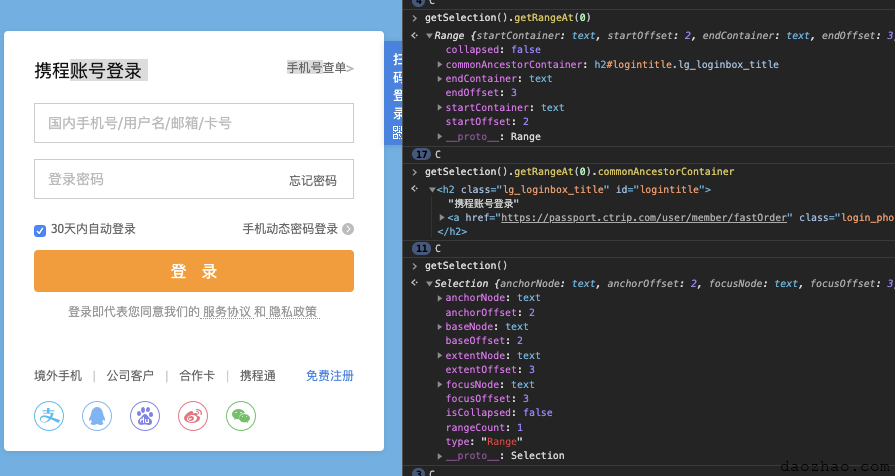
window.getSelection.getRangeAt(0).startContainer和window.getSelection.getRangeAt(0).startOffset可以获取到“账号登录”,因为“账号登录”就是从“携程账号登录”的第2位开始的(0为第一位,下同),就是说startContainer里面的第2位开始都是选区内容了。window.getSelection.getRangeAt(0).endContainer和window.getSelection.getRangeAt(0).endOffset可以获取到“手机号”,因为“手机号”就是从“手机号查单”的第3位开始结束的,类似slice的前闭后开原则,就是说endContainer里面的第3位开始都是选区外了。 到此,是不是觉得这个需求有眉目了,能搞定了?剩下的我们下篇再讲。
