

本文转自UI绘制优化
前言
任何Android应用都需要UI跟用户交互.UI是否好坏更是直接影响到用户的体验.所以UI的优化视乎是应用开发中一个绕不过去的话题.
渲染流程
要做到优化需要先从View渲染的流程说起.
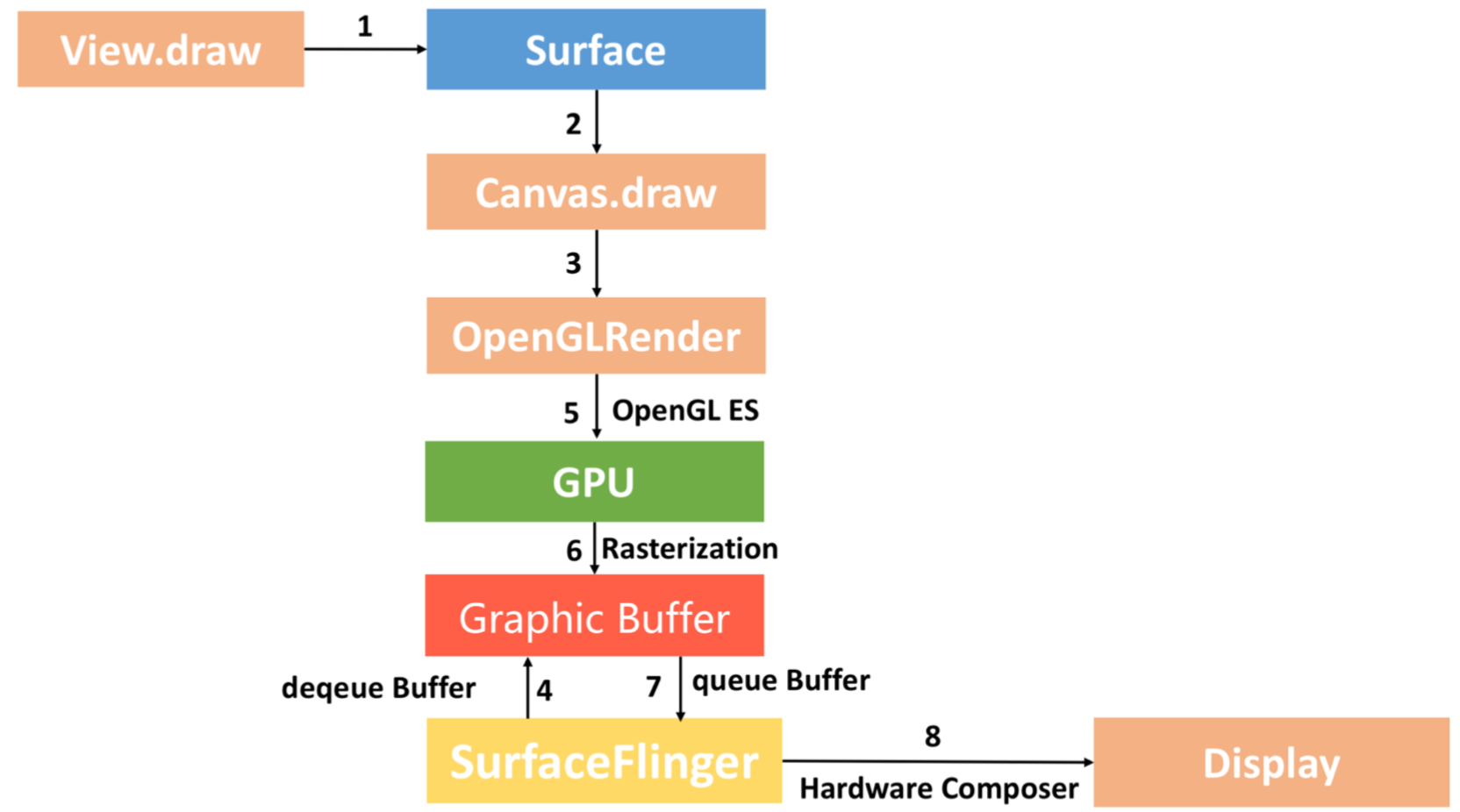
如果没有开启硬件加速,系统则会用软件加速的形式来渲染.
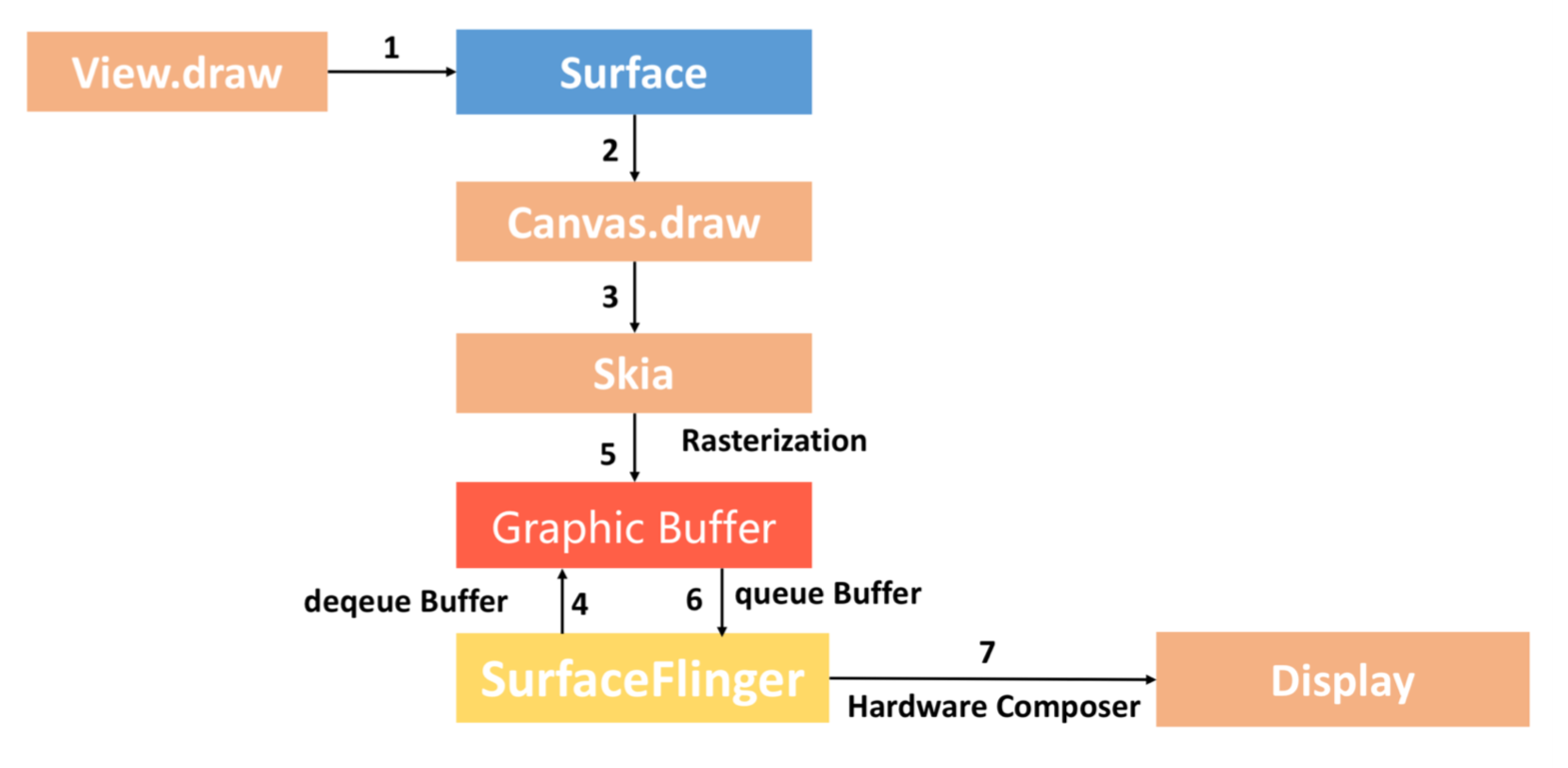
PS:Androd3.0开始支持硬件加速,到Android4.0默认开启硬件加速.
建议大家可以看下深入Android渲染机制、Hardware acceleration
系统渲染优化演进史
- Android 3.0
从上面部分可以看出有了Android.3.0后有了硬件加速与原来的软件绘制整个流程差异非常大,最核心就是我们通过GPU完成Graphic Buffer的内容绘制。此外硬件绘制还引 入了一个DisplayList的概念,每个View内部都有一个DisplayList,当某个View需要重绘时,将它标记为Dirty. 当需要重绘时,仅仅只需要重绘一个View的DisplayList,而不是像软件绘制那样需要向上递归。这样可以大大减少绘图的操作 数量,因而提高了渲染效率.
- Android 4.1
Android4.1版本后还加入了三级缓冲机制Triple Buffering.在之前系统使用的是双缓冲机制,双缓冲机制简单说就是不同的View或者Activity它们都会共用一个Window, 也就是共用同一个Surface对象. 而每个Surface都会有一个BufferQueue缓存队列,但是这个队列会由SurfaceFlinger管理,通过匿名共享内存机制与App应用 层交互.
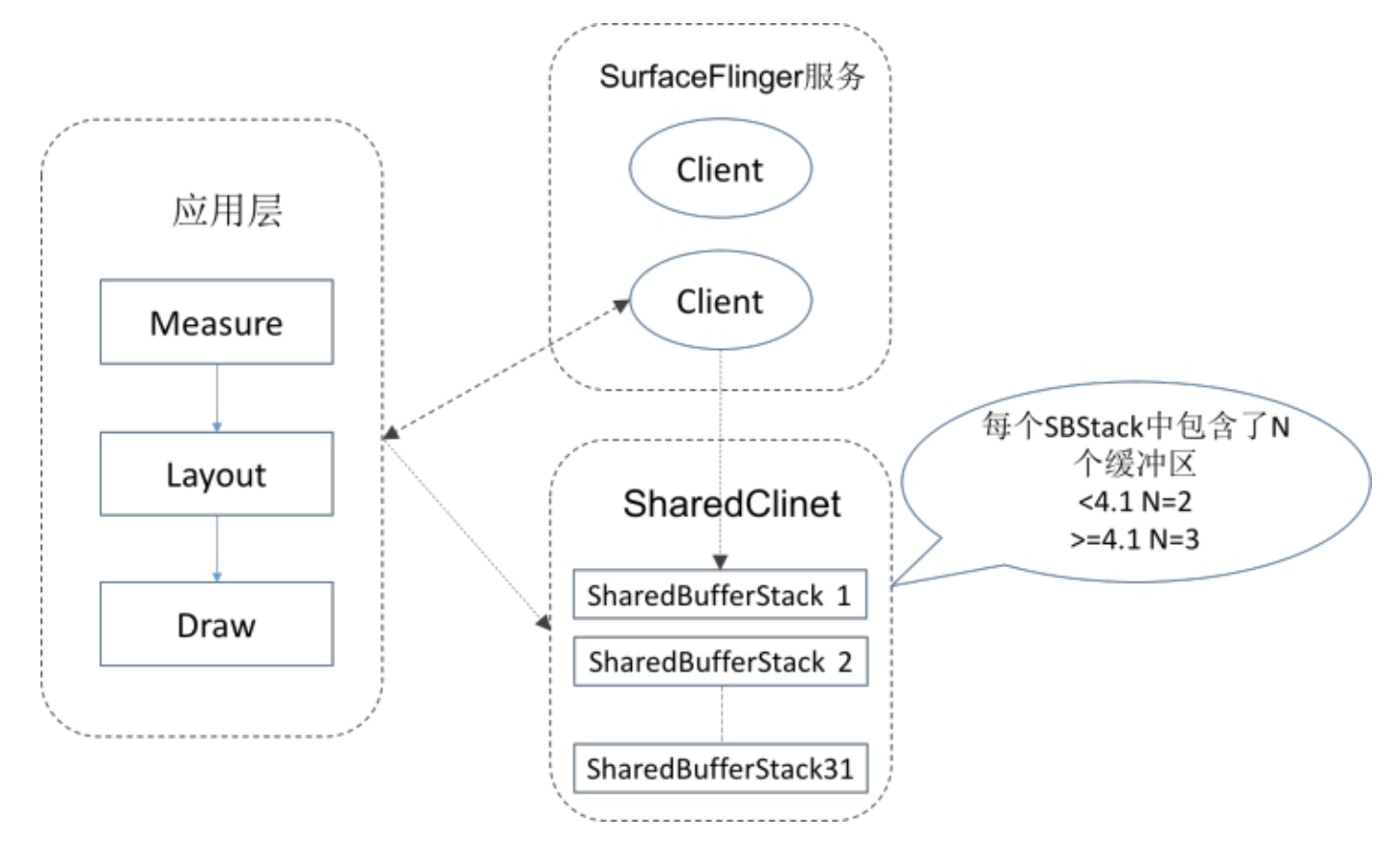
流程梳理后如下:
- 每个Surface对应的BufferQueue内部都有两个Graphic Buffer ,一个用于绘制一个用于显示.我们会把内容先绘制到离屏缓 冲区(OffScreen Buffer),在需要显示时,才把离屏缓冲区的内容通过Swap Buffer复制到Front Graphic Buffer中.
- 这样SurfaceFlinge就拿到了某个Surface最终要显示的内容,但是同一时间我们可能会有多个Surface.这里面可能是不同 应用的Surface,也可能是同一个应用里面类似SurefaceView和TextureView,它们都会有自己单独的Surface.
- 这时SurfaceFlinger把所有Surface要显示的内容统一交给Hareware Composer,它会根据位置、Z-Order顺序等信息合 成为最终屏幕需要显示的内容,而这个内容会交给系统的帧缓冲区Frame Buffer来显示(Frame Buffer是非常底层的,可以 理解为屏幕显示的抽象).
那三级缓冲机制又是什么呢? 简单来说,三缓冲机制就是在双缓 冲机制基础上增加了一个Graphic Buffer缓冲区,这样可以最大限度的利用空闲时间.
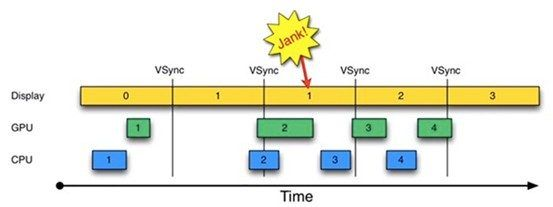
为解决这个问题,Android 4.1中引入了VSYNC,核心目的是解决刷新不同步的问题.
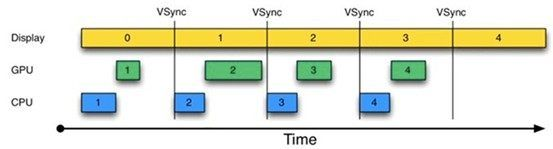
但如果CPU/GPU的FPS小于Display的FPS,情况又不同了,将会发生如下图的情况:
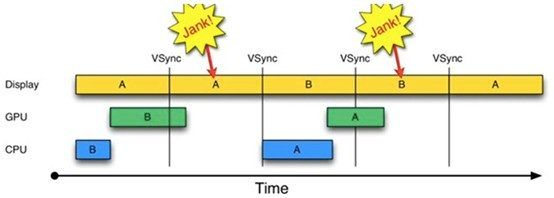
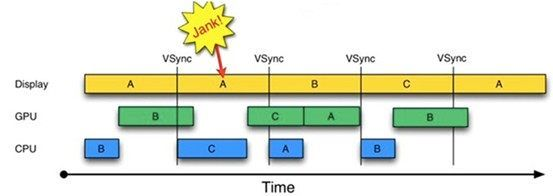
- Android 4.2
在Android 4.2,系统增加了检测绘制过度工具,具体的使用方法可以参考《检查GPU渲染速度和绘制过度》

- Android 5.0
经过Project Butter⻩油计划之后,Android的渲染性能有了很大的改善。但是不知道你有没有注意到一个问题,虽然我们利用 了GPU的图形高性能运算,但是从计算DisplayList,到通过GPU绘制到Frame Buffer,整个计算和绘制都在UI主线程中完成.
UI主线程“既当爹又当妈”,任务过于繁重.如果整个渲染过程比较耗时,可能造成无法响应用户的操作,进而出现卡顿.GPU 对图形的绘制渲染能力更胜一筹,如果使用GPU并在不同线程绘制渲染图形,那么整个流程会更加顺畅. 正因如此,在Android 5.0引入了两个比较大的改变.一个是引入了RenderNode的概念,它对DisplayList及一些View显示属性 做了进一步封装.另一个是引入了RenderThread,所有的GL命令执行都放到这个线程上,渲染线程在RenderNode中存有渲 染帧的所有信息,可以做一些属性动画,这样即便主线程有耗时操作的时候也可以保证动画流畅. 在官方文档 《检查GPU渲染速度和绘制过度》中,我们还可以开启Profile GPU Rendering检查.在Android 6.0之后,会输 出下面的计算和绘制每个阶段的耗时:

- Android 6.0 - Android P
在Android 6.0的时候,Android在gxinfo添加了更详细的信息;在Android 7.0又对HWUI进行了一些重构,而且支持了 Vulkan;在Android P支持了Vulkun 1.1.
由于Android每个版本对 渲染模块都做了一些重构,在某些场景经常会出现一些莫名其妙的问题. 所以我们可以通过了解系统渲染的优化史,逐步加深了对渲染机制的了解.这对我们UI渲染优化工作会有很大的帮助.下面我们继续探讨下改如何优化UI的渲染.
UI 渲染优化
说到渲染优化很多人都会想到卡顿优化.的确两者好像是密不可分的.但两者是同一回事吗?我的答案是否定的.
一般意义的卡顿是指在系统的VSYNC信号到达时,如果主线程被某个耗时任务堵塞,⻓时间无法对UI进行渲染,这时就会出现卡顿.我认为渲染优化要解决的核心是由于渲染性能本身造成用户感知的卡顿,它可以认为是卡顿优化 其中一个子集.
那该如何着手呢?
- UI渲染测量
首先得有工具定位到问题,除了常用的Show GPU Overdraw、Tracer for OpenGL ES和Android Studio 3.1后用Graphics API Debugger(GAPID)外.还有以下两个方法:
- gfxinfo
gfxinfo可以输出包含各阶段发生的动画以及帧相关的性能信息,具体命令如下:
adb shell dumpsys gfxinfo 包名
除了渲染的性能之外,gfxinfo还可以拿到渲染相关的内存和View hierarchy信息.在Android 6.0之后,gxfinfo命令新增了 framestats参数,可以拿到最近120帧每个绘制阶段的耗时信息.
adb shell dumpsys gfxinfo 包名 framestats
通过这个命令我们可以实现自动化统计应用的帧率,更进一步还可以实现自定义的“Profile GPU Rendering”工具,在出现掉帧 的时候,自动统计分析是哪个阶段的耗时增⻓最快,同时给出相应的建议.

- SurfaceFlinger
除了耗时,我们还比较关心渲染使用的内存。上一期我讲过,在Android 4.1以后每个Surface都会有三个Graphic Buffer,那如 何查看Graphic Buffer占用的内存,系统是怎么样管理这部分的内存的呢? 你可以通过下面的命令拿到系统SurfaceFlinger相关的信息:
adb shell dumpsys SurfaceFlinger
下面应用使用了三个Graphic Buffer缓冲区,当前用在显示的第二个Graphic Buffer,大小是1080 x 1920.
Layer 0x793c9d0c00 (com.ss.***。news/com.**.MainActivity)
//序号 //状态 //对象 //大小
[02:0x794080f600] state=ACQUIRED, 0x794081bba0 [1080x1920:1088, 1]
[00:0x793e76ca00] state=FREE , 0x793c8a2640 [1080x1920:1088, 1]
[01:0x793e76c800] state=FREE , 0x793c9ebf60 [1080x1920:1088, 1]
现在我们也可以更好地理解三缓冲机制,你可以看到这三个Graphic Buffer的确是在交替使用.
继续往下看,你可以看到这三个Buffer分别占用的内存:
Allocated buffers:
0x793c8a2640: 8160.00 KiB | 1080 (1088) x 1920 | 1 | 0x20000900
0x793c9ebf60: 8160.00 KiB | 1080 (1088) x 1920 | 1 | 0x20000900
0x794081bba0: 8160.00 KiB | 1080 (1088) x 1920 | 1 | 0x20000900
那系统是怎么样管理这部分内存的呢?当应用退到后台的时候,系统会将这些内存回收,也就不会再把它们计算到应用的内存占用中
Layer 0x793c9d0c00 (com.ss.***。news/com.**.MainActivity)
[00:0x0] state=FREE
[01:0x0] state=FREE
[02:0x0] state=FREE
- 渲染优化常用手段
从上面渲染流程可以看出,渲染优化的目的是要保证界面实现60fps,也就说16 ms内完成渲染.
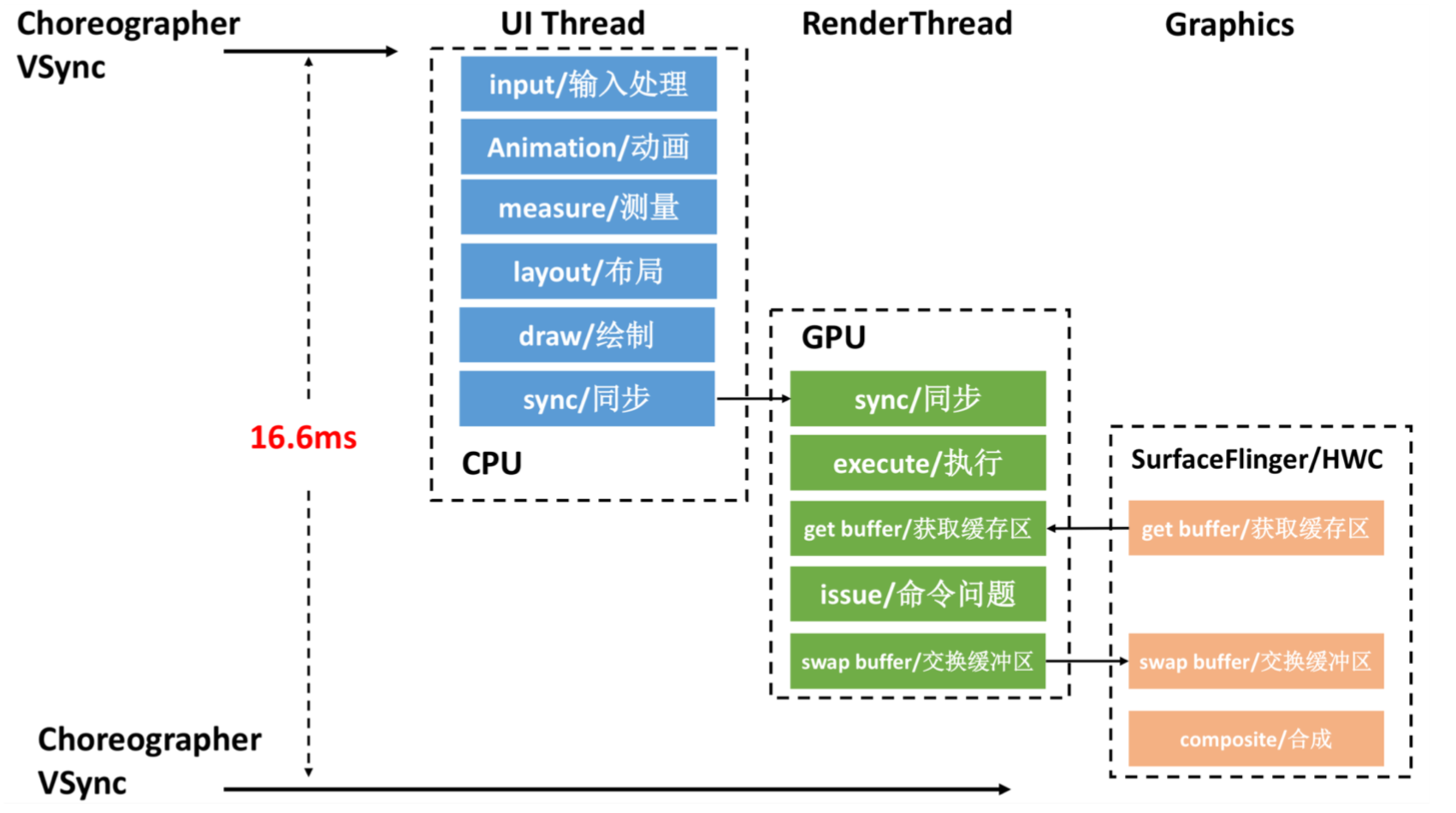
拆解渲染的各个阶段的耗时,找到瓶颈的地方,再加以优化.接下来我们一起来看看UI优化的一些常用的手段
- 尽量使用硬件加速
通过上面分析相信大家也看出硬件加速绘制的性能是远远高于软件绘制的,所以渲染优化第一个手段就是保证 渲染尽量使用硬件加速.
其实在Android4.1后默认是开启硬件加速的,我们要先确定哪些情况不能使用硬件加速,之所以不能使用硬件加速是因为硬件加速不能支持所有的Canvas API,具体API兼容 列表可以⻅drawing-support文档。如果使用了不支持的API,系统就需要通过CPU软件模拟绘制,这也是渐变、磨砂、圆⻆等 效果渲染性能比较低的原因.
SVG也是一个非常典型的例子,SVG有很多指令硬件加速都不支持.但我们可以用一个取巧的方法,提前将这些SVG转换成 Bitmap缓存起来,这样系统就可以更好地使用硬件加速绘制.
同理,对于其他圆⻆、渐变等场景,我们也可以改为Bitmap实现. 这种取巧方法实现的关键在于如何提前生成Bitmap,以及Bitmap的内存需要如何管理.你可以参考一下市面常用的图片库实现.或参考androidsvg-FAQ(能开打的话)
- Create View优化
观察渲染的流水线时,大家可能发现缺少一个非常重要的环节,那就是View创建的耗时.请不要忘记,View的创建也是在 主线程里,对于一些非常复杂的界面,这部分的耗时不容忽视.
在优化之前我们先来分解一下View创建的耗时,可能会包括各种XML的随机读的I/O时间、解析XML的时间、生成对象的时间 (Framework会大量使用到反射). 相应的,我们来看看这个阶段有哪些优化方式: 3. 将XML布局转成代码
使用XML进行UI编写可以说是十分方便,可以在Android Studio中实时预览到界面。如果我们要对一个界面进行极致优化,就 可以使用代码进行编写界面。 但是这种方式对开发效率来说简直是灾难,因此我们可以使用一些开源的XML转换为Java代码的工具,例如掌阅的X2C.但坦白说,还是有不少情况是不支持直接转换的.
- 支线程创建View
那能否在支线程先实例化好view.再切回主线程加载到布局中呢?试过的朋友都会发现抛出下面的异常
java.lang.RuntimeException:
Can't create handler inside thread that has not called Looper.prepare()
at android.os.Handler.<init>(Handler.java:121)
而其实是有个取巧的办法可以做到.
在支线程实例化View时
可以先把Looper的MessageQueue替换成UI线程Looper的Queue
.(类似下面代码)
public static boolean prepareLooperWithMainThreadQueue(boolean reset) {
if (isMainThread()) {
return true;
} else {
ThreadLocal<Looper> threadLocal =(ThreadLocal) ReflectionHelper.getStaticFieldValue(Looper.class, "'sThreadLocal");
if (null == threadLocal) {
return false;
} else {
Looper looper = null;
if (!reset) {
Looper.prepare();
looper = Looper.myLooper();
Object queue = ReflectionHelper.invokeMethod(Looper.getMainLooper(), "getQueue", new Class[0], new Object[0]);
if (!(queue instanceof MessageQueue)) {
return false;
}
ReflectionHelper.setFieldValue(looper, "mQueue", queue);
}
ReflectionHelper.invokeMethod("set", new Class[]{Object.class}, new Object[]{looper});
return true;
}
}
}
但创建后要把线程的Looper恢复成原来的.
- View重用
参考ListView、RecycleView通过View的缓存与重用提升渲染性能思路.实现一套可以在不同Activity或者Fragment使用的View缓存机制.但是需要保证所有进入缓存池的View不会保留之前的状态.否则会造成显示错乱.
- measure和layout优化
相关文章有很多,如减少布局层级,少用RelativeLayout或weight LinearLayout,减少无用背景等等,这里不过多叙述.对于measure和layout能否也实现支线程的预加载呢?上一年的I/O大会上, 谷歌就发布了PrecomputedText,它给我们提供了接口,可以让Textview异步进行measure和layout,不必在主线程中执行.
- 进阶优化方案
这里重点介绍两种:
- Litho
Litho框架是Facebook开源的声明式Android UI渲染框架,它是基于另外一个Facebook开源的布局引擎Yoga开发的. 内部做了不少优化.下面简单介绍下
- 异步布局
一般情况View的渲染都是经过measure、layout、draw三个方法.这方法都是要再主线程执行的.
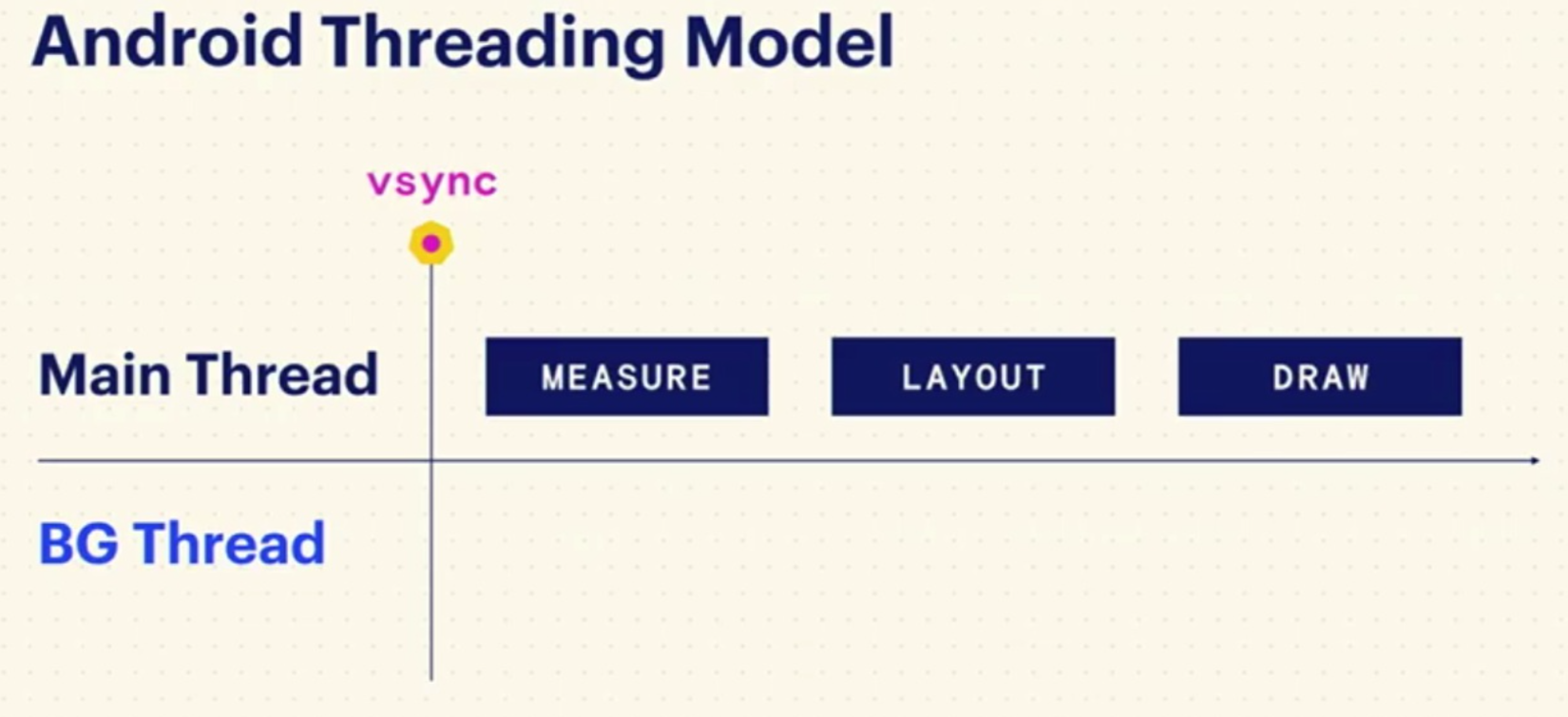
Litho跟上面提到的PrecomputedText一样,把measure和layout都放到了支线程,只留下了必须要在主线程完成的draw, 这大大降低了UI线程的负载.它的渲染流水线如下:

- 界面扁平化
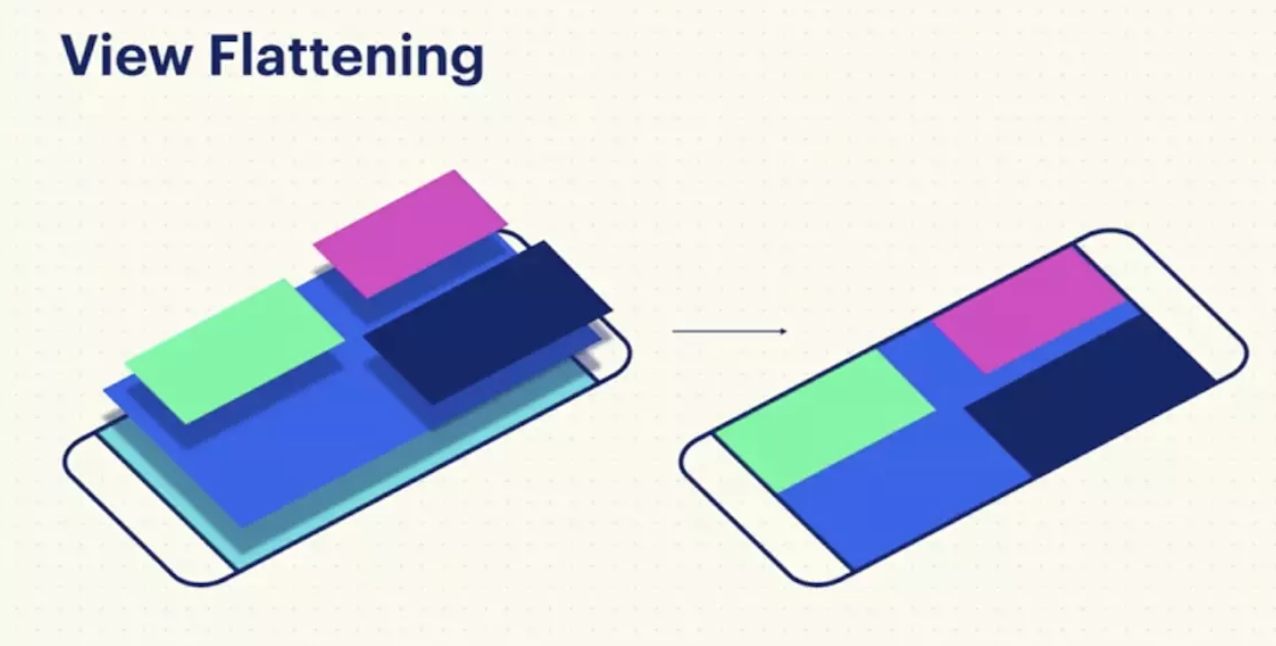
前面也提过降低布局层级是一个非常通用的优化方法.有没一种方法不通过代 码的改变可以直接降低UI的层级呢?Litho就给了我们一种方案,由于Litho使用了自有的布局引擎(Yoga),在布局阶段就可以检测不必要的层级、减 少ViewGroups,来实现UI扁平化.比如下面这样图,上半部分是我们一般编写这个界面的方法,下半部分是Litho编写的界 面,可以看到只有一层层级.
- 优化RecyclerView
Android ReyclerView 的复用是基于 ViewType 的,假设有上百个ViewType,各种文章文本视频图片组合在一起,每个 Type 分配一个Pool,那将会有上百个 pool ,会对内存造成负担.如下视频:
RecylerView 多类型复用 、 Litho中的细粒度复用
相对原生的RecyclerView按照viewType来进行缓存和回 收,Litho则是按照text、image和video独立回收的,这可以提高缓存命中率、降低内存使用率、提高滚动帧率.
Litho虽强大,但它也有缺点.它为了实现measure/layout异步化,使用了类似react单向数据流设计,这一定程度上加 大了UI开发成本.并且Litho的UI代码是使用Java/Kotlin来进行编写,无法做到在AS中预览. 所以建议还是先局部使用.
- RenderThread与RenderScript
在Android 5.0,系统增加了RenderThread,对于ViewPropertyAnimator和CircularReveal动画,我们可以使用RenderThead 实现动画的异步渲染。当主线程阻塞的时候,普通动画会出现明显的丢帧卡顿,而使用RenderThread渲染的动画即使阻塞了 主线程仍不受影响.
现在越来越多的应用会使用一些高级图片或者视频编辑功能,例如图片的高斯模糊、放大、锐化等.拿 "扫一扫"这个场景来看,这里涉及大量的图片变换操作,例如缩放、裁剪、二值化以及降噪等. 图片的变换涉及大量的计算任务,根据我们说到的,这个时候使用GPU是更好的选择. 我们可以通过RenderScript,它是Android操作系统上的一套API.它基于异构计算思想,专⻔用于密集型计算.
RenderScript 提供了三个基本工具:一个硬件无关的通用计算API;一个类似于CUDA、OpenCL和GLSL的计算API;一个类C99的脚本语 言.允许开发者以较少的代码实现功能复杂且性能优越的应用程序. 具体可以参考 RenderScript渲染利器、 RenderScript :简单而快速的图像处理
总结
用户的体验直接跟屏幕上展现的内容相关.如果应用内容渲染很慢或者滑动不够流畅,用户的感知就是负面的. 我们可以通过今天的说的技巧在项目中进行一一实践,优化我们的项目.希望对你有帮助.
