

前言
本身在面试博客里只是想整理一下js的类型,越联想越感觉这块的知识体量大,而且都是相关联的只是,但网上的现有的很多博客繁杂还不太清晰,故此专门记录一下这几个点。 相关文章整理: Jcat_李小黑的博客
一、js中的数据类型
基本类型:number ,string,null,Boolen,undefined,symbol 引用类型:object (Array,Function,Date,Regxp在es6中规定都是object类型)
两者的区别:
基本类型:可以直接操作的实际存在的数据段。存在在内存的栈中,比较的是值的比较!
引用类型:复制操作是复制的是对象的引用,增加操作时是操作的对象本身。存在在堆内存和栈内存中,比较的是引用的比较!
这里只特别关注一下es6新增的类型:symbol;其他类型的具体细节也特别多,不一一列举了,可以直接参考: 【JS 进阶】你真的掌握变量和类型了吗
1.1 什么是symbol?
symbol是es6新增的一个基本数据类型,保存在栈内存中,通常使用symbol来指代独一无二的属性。
1.1.1 symbol的特征
特征1 :独一无二 直接使用Symbol()创建新的symbol变量,可选用一个字符串用于描述。当参数为对象时,将调用对象的toString()方法。
var sym1 = Symbol(); // Symbol()
var sym2 = Symbol('111'); // Symbol(ConardLi)
var sym3 = Symbol('111'); // Symbol(ConardLi)
var sym4 = Symbol({name:'222'}); // Symbol([object Object])
console.log(sym2 === sym3); // false
我们用两个相同的字符串创建两个Symbol变量,它们是不相等的,可见每个Symbol变量都是独一无二的。
特征2 :是基本数据类型,不能使用new Symbol()创造
let sym = new Symbol() //Symbol is not a constructor
let sym = Symbol('121')
console.log(typeof sym); //Symbol
特征3:不可枚举
当使用Symbol作为对象属性时,可以保证对象不会出现重名属性,调用for...in不能将其枚举出来,另外调用Object.getOwnPropertyNames、Object.keys()也不能获取Symbol属性。
可以调用Object.getOwnPropertySymbols()用于专门获取Symbol属性。
var obj = {
name:'ConardLi',
[Symbol('name2')]:'code秘密花园'
}
Object.getOwnPropertyNames(obj); // ["name"]
Object.keys(obj); // ["name"]
for (var i in obj) {
console.log(i); // name
}
Object.getOwnPropertySymbols(obj) // [Symbol(name)]
1.2 symbol的作用?
做为对象属性名
由于每一个Symbol对象的值都是不相等的,利用这一特性,符号做为标识符使用。将其用于对象属性名时,可以保证对象每一个属性名都是唯一的,不会发生对象属性被覆盖的情况。
用符号做为对象属性名时,不能用**.**的形式添加对象属性:
var sym = Symbol();
var a = {};
a.sym = 'itbilu.com';//以点的形式添加属性名其本质上还是一个字符串
a[sym] // undefined
a['sym'] // "itbilu.com"
可以使用以下三种方式添加符号的对象属性:
- 用方括号添加
var sym = Symbol();
var a = {};
a[sym] = 'itbilu.com';
- 在对象内部定义
var a = {
[sym]: 'itbilu.com'
};
- 用defineProperty添加
var a = {};
Object.defineProperty(a, sym, { value: 'itbilu.com' });
二、堆内存和栈内存
可以分辨数据类型之后,我们再看一下在javascript中存储数据的地方:堆内存和栈内存
2.1 举例理解
在v8引擎中对js变量的存储主要有两种位置:堆内存和栈内存,以下简称堆、栈。 下面通过两个例子来理解堆和栈使用
//例1
var num1 = 1
var num2 = "222"
num2 = num1
num2 = '666'
console.log(num1)// 1
console.log(num2)// '666'
这里可以看出上述的基本数据类型,是真实值在比较。那我们在看一下引用数据类型:
//例2
var obj1 = {name:'aa',age:18}
var obj2 = obj1
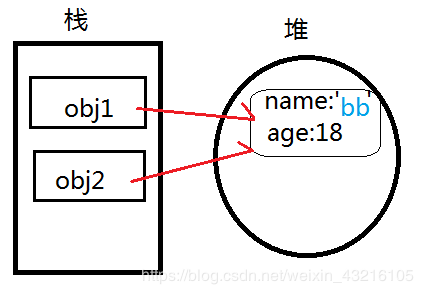
obj2.name = 'bb'
console.log(obj1) // { name: "bb", age: 18 }
console.log(obj2) // { name: "bb", age: 18 }
这里我们可以看出当obj2改变的时候,obj1也同时一起改变了!为什么会被影响而不像基本数据类型呢?我们来分析一下例2的过程:
当var obj2 = obj1时,数据存储的位置如下
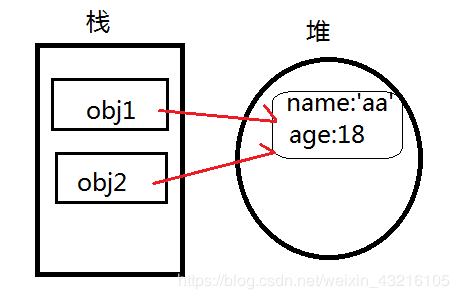
obj2.name = 'bb'时,改变的是堆中实际的数据!
2.2 堆内存和栈内存的区别:
- 栈内存主要用于存储各种基本类型的变量,包括Boolean、Number、String、Undefined、Nul 和引用数据类型的地址指针,它们都是直接按值存储在栈中的。
- 堆内存主要用于存储引用类型如对象(Object)、数组(Array)、函数(Function) …,当我们想要访问引用类型的值的时候,需要先从栈中获得对象的地址指针,然后,在通过地址指针找到堆中的所需要的数据。
2.3 相关内容思考
2.3.1 为什么基本数据类型保存在栈中,而引用数据类型保存在堆中?
- 堆比栈大,栈比堆速度快;
- 基本数据类型比较稳定,而且相对来说占用的内存小;
- 引用数据类型大小是动态的,而且是无限的,引用值的大小会改变,不能把它放在栈中,否则会降低变量查找的速度,因此放在变量栈空间的值是该对象存储在堆中的地址,地址的大小是固定的,所以把它存储在栈中对变量性能无任何负面影响;
- 堆内存是无序存储,可以根据引用直接获取;
2.3.2 es6中的const定义的数据能改吗?
学习过es6知识后都知道新增了新建两个局部作用域变量的let 和 const,const通常用来命名不可更改的常量,但是const命名的值,也不是完全不能改!这里就涉及到命名基本数据类型还是命名引用数据类型。
const a = 1
a = 2
console.log(a) // error: Assignment to constant variable.
const obj = {b:1}
obj.b = 2
console.log(obj) // { b:2}
当我们定义一个const引用数据类型的时候,我们说的常量其实是指针,就是const对象对应的堆内存指向是不变的,但是堆内存中的数据本身的大小或者属性是可变的。而对于const定义的基础数据类型而言,这个值就相当于const对象的指针,是不可变。
三、js的垃圾回收机制
初步理解了堆和栈,那我们来思考一个问题,计算机的内存就那么大,假设我们一直往里面存东西而不取的话,内存会满吗?如果满了怎么办?
答案肯定是会满啊!为了不让它满,这里就要提一下js的垃圾回收机制了
javaScript的内存管理不同于其他语言,程序员本身不可以操作而是由系统全自动回收~当然我们平时码字的时候不用管它,但是如果代码有问题的话,还是会造成内存泄漏,长时间积攒下来最终导致内存溢出(就是满了 ~没地儿存了)
3.1 垃圾回收机制
JavaScript垃圾回收机制很简单:找出不再使用的变量(垃圾),然后释放掉其占用的内存(回收),但是这个过程不是实时的,因为其开销比较大,所以垃圾回收系统(GC)会按照固定的时间间隔,周期性的执行。
var a = 'test11'
var b = 'test222'
var a = b
这就是简单的回收,“test11”这个字符串失去了引用(之前是被a引用),系统检测到这个事实之后,就会释放该字符串的存储空间以便这些空间可以被再利用。针对这个解释,为方便理解,提出两个问题:
3.1.1 什么才算是不再使用的变量?
-
不再需要使用的变量也就是生命周期结束的变量,是局部变量,局部变量只在函数的执行过程中存在, 当函数运行结束,没有其他引用(闭包),那么该变量会被标记回收。
-
全局变量的生命周期直至浏览器卸载页面才会结束,也就是说全局变量不会被当成垃圾回收。
如果对什么是引用还不太清除可以参考这篇:js垃圾回收中的引用概念
3.1.2 怎么回收这些垃圾?
js对这类变量有两种定义方式:标记清除法和引用计数法;
引用计数是指跟踪记录每个值被引用的次数,语言引擎有一张"引用表",保存了内存里面所有的资源(通常是各种值)的引用次数。如果一个值的引用次数是0,就表示这个值不再用到了,因此可以将这块内存释放。
var obj = { a : {test : 1} }
//两个对象被创建,一个a{}作为另一个的属性被引用,另一个{}被分配给变量o,没有可以被回收的
var obj2 = obj
//obj 引用次数为1
obj = 1
// 现在,“这个对象”的原始引用obj被obj2替换了,
var obj3 = obj2.a;
// 引用 obj2 的a属性,现在,a{} 引用次数为2了,一个是obj2,一个是obj3
obj2 = 'test' //原始obj 引用次数为0 ,可以被回收了
obj3 = null //a{}的引用次数也为0 ,可以被回收了
- 当声明了一个变量并将一个引用类型值(function object array)赋给该变量时,则这个值的引用次数就是1。
- 如果同一个值又被赋给另一个变量,则该值的引用次数加1。
- 相反,如果包含对这个值引用的变量又取得了另外一个值,则这个值的引用次数减1。
- 当这个值的引用次数变成0时,则说明没有办法再访问这个值了,因而就可以将其占用的内存空间回收回来。
- 当垃圾回收器下次再运行时,它就会释放那些引用次数为0的值所占用的内存。
我们再看一个例子:
function f(){
var o = {};
var o2 = {};
o.a = o2; // o 引用 o2
o2.a = o; // o2 引用 o 这里
return "azerty";
}
f();
这就是一个简单的循环引用例子,但是如果一个值不再需要了,引用数却不为0,垃圾回收机制无法释放这块内存,从而导致内存泄漏。为了解决循环引用造成的问题,我们通过使用标记清除算法来实现垃圾回收。
标记清除(常用),它的过程可以分为几步:
- 垃圾收集器会在运行的时候会给存储在内存中的所有变量都加上标记。
- 从根部出发将能触及到的对象(环境中使用的变量,被环境中的变量引用的变量)的标记清除。
- 那些还存在标记的变量被视为准备删除的变量。
- 最后垃圾收集器会执行最后一步内存清除的工作,销毁那些带标记的值并回收它们所占用的内存空间。
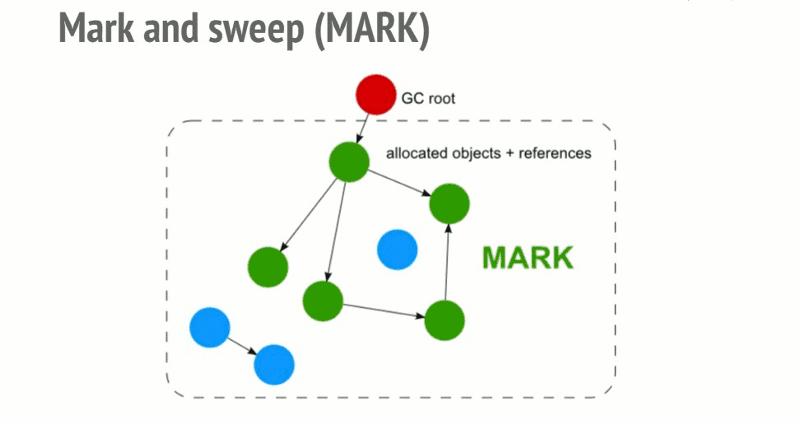
function f(){
var o = {};
var o2 = {};
o.a = o2; // o 引用 o2
o2.a = o; // o2 引用 o 这里
return "azerty";
}
f();
console.log(test()) //{ d: "我将要被使用" }
再看之前循环引用的例子,函数调用返回之后,两个循环引用的对象在垃圾收集时从全局对象出发无法再获取他们的引用。 因此,他们将会被垃圾回收器回收。
3.1.3 这个回收的周期性怎么定义?
- IE7之前的垃圾收集器是根据内存分配量运行的,即 256 个变量、4096 个对象(数组)字面量或 64 KB 的字符串。达到这些临界值的任何一个,垃圾收集器就会运行。
- IE7 重写了垃圾收集例程。新的工作方式为:触发垃圾收集的变量分配、字面量和数组元素的临界值被调整为 动态修正。初始值与之前版本相同,但如果垃圾收集例程回收的内存低于 15%,则临界值加倍。若回收内存分配量超过 85%,则临界值重置回默认值。
- V8 中的垃圾回收主要使用的是 分代回收 (Generational collection)机制,将保存对象的 堆 (heap) 进行了分代:
对象最初会被分在 新生区(New Space) (1~8M),新生区的内存分配只需要保有一个指向内存区的指针,不断根据内存大小进行递增,当指针达到新生区的末尾,会有一次垃圾回收清理(小周期),清理掉新生区中不再活跃的死对象。
-
对于超过 2 个小周期的对象,则需要将其移动至 老生区(Old Space)。老生区在 标记-清除 或 标记-紧缩 的过程(大周期) 中进行回收。一次大周期通常是在移动足够多的对象至老生区后才会发生。
-
GC执行时,中断代码,停止其他操作。执行阶段遍历所有对象,对于不可访问的对象进行回收。该机制执行操作耗时100ms左右。
-
关于详细的回收算法,可以参考:segmentfault.com/a/119000001…
-
了解了什么是垃圾回收,我们再了解一下没有被回收的变量造成的后果是什么?
3.2 什么是内存溢出和内存泄漏?
内存泄漏指你向系统申请分配内存进行使用,可是使用完了以后却不归还(删除),结果你申请到的那块内存你自己也不能再访问(也许你把它的地址给弄丢了),而系统也不能再次将它分配给需要的程序。
内存溢出就是你要求分配的内存超出了系统能给你的,系统不能满足需求,于是产生溢出。
3.2.1 什么情况会导致内存泄漏?
1. 意外的全局变量
function (){
test = "我没有被声明,是一个指向window的全局变量 "
this.data = "我是挂载在this上的变量,this指向window,所以我也是全局变量"
}
原因:全局变量在页面关闭之前都不会被回收,从而导致内存泄漏。
优化:在 JavaScript 文件头部加上 'use strict',可以避免此类错误发生。启用严格模式解析 JavaScript ,避免意外的全局变量。
2.没有被清除的定时器和回调函数
var someResource = getData();
setInterval(function() {
var node = document.getElementById('Node');
if(node) {
// 处理 node 和 someResource
node.innerHTML = JSON.stringify(someResource));
}
}, 1000);
原因:上述代码,每1秒调一次,如果id为Node的元素从DOM中移除,该定时器仍会存在,同时,因为回调函数中包含对someResource的引用,定时器外面的someResource也不会被释放。
优化:使用完成后就clearInterval()清除定时器
3.闭包
function name() {
var name = '小明'
function printName() {
var age = 13
console.log(name + '今年' +age+'岁')
}
printName()
}
name()
概念:定义在函数内部的函数,printName就是一个闭包,其作用:1.可以访问到父集函数的局部变量;2.让这些变量的值始终保持在内存中,不会在name()调用后被自动清除。
原因:上述代码中name是printName的父函数,而printName被赋给了一个全局变量,这导致printName始终在内存中,而printName的存在依赖于name,因此name也始终在内存中,不会在调用结束后,被垃圾回收机制回收。
function name() {
var name = '小明'
printName(name)
}
function printName(name) {
var age = 13
console.log(name + '今年' + age + '岁')
}
name()
优化:将闭包函数定义在外层
4. 没有清理的DOM元素的引用 很多时候, 我们对 Dom 的操作, 会把 Dom 的引用保存在一个数组或者 Map 中。 虽然我们removeChild移除了button,但是还在elements对象里保存着#button的引用,换言之,DOM元素还在内存里面。
var elements = {
button: document.getElementById('button'),
image: document.getElementById('image'),
text: document.getElementById('text')
};
function doStuff() {
image.src = 'http://some.url/image';
button.click();
console.log(text.innerHTML);
}
function removeButton() {
document.body.removeChild(document.getElementById('button'));
// 此时,仍旧存在一个全局的 #button 的引用
// elements 字典。button 元素仍旧在内存中,不能被 GC 回收。
}
3.2.2 内存泄漏如何优化?
关于内存分配通常有4中方法,分类进行优化:
1. new 关键词,new 关键词就意味着一次内存分配,例如 new Foo()。最好的处理方法是:在初始化的时候新建对象,然后在后续过程中尽量多的重用这些创建好的对象。
2. 数组
将[ ]赋值给一个数组对象,是清空数组的捷径(例如: arr = [];),但是需要注意的是,这种方式又创建了一个新的空对象,并且将原来的数组对象变成了一小片内存垃圾!实际上,将数组长度赋值为0(arr.length = 0)也能达到清空数组的目的,并且同时能实现数组重用,减少内存垃圾的产生。
const arr = [1, 2, 3, 4];
arr.length = 0 // 可以直接让数字清空,而且数组类型不变。
// arr = []; 虽然让a变量成一个空数组,但是在堆上重新申请了一个空数组对象。
3. 对象
对象尽量复用,尤其是在循环等地方出现创建新对象,能复用就复用。不用的对象,尽可能设置为null,尽快被垃圾回收掉。
var t = {} // 每次循环都会创建一个新对象。
for (var i = 0; i < 10; i++) {
// var t = {};// 每次循环都会创建一个新对象。
t.age = 19
t.name = '123'
t.index = i
console.log(t)
}
t = null //对象如果已经不用了,那就立即设置为null;等待垃圾回收。
4.函数
和上面的闭包一样,尽量把函数放置到外层作为返回值,然后使用调用的方式的方式
for (var k = 0; k < 10; k++) {
var t = function(a) {
// 创建了10次 函数对象。
console.log(a)
}
t(k)
}
// 推荐用法
function t(a) {
console.log(a)
}
for (var k = 0; k < 10; k++) {
t(k)
}
t = null
相比于每次都新建一个方法对象,这种方式在每一帧当中重用了相同的方法对象。这种方式的优势是显而易见的,而这种思想也可以应用在任何以方法为返回值或者在运行时创建方法的情况当中。
3.2.3 递归太深会导致栈溢出怎么解决?
未完。。。
再次理解了堆和栈,以及垃圾回收机制,为了加深深入理解,下面我们再看一下 深拷贝和浅拷贝中的应用
四、深拷贝和浅拷贝
4.1 解释拷贝
我浏览了很多文档,对于赋值、深浅拷贝说法不一,很多都是赋值和深浅拷贝分不清楚,在此,特意说明一下赋值和拷贝的区别!专门查了书,发现浅拷贝这里的东西没有具体定义,但是我更认可:引用类型的 赋值不等于浅拷贝和 浅拷贝是一层数据的拷贝,深拷贝是多层的拷贝这个观点。
上述例2的过程是一个赋值操作,赋值的只是对象的引用,如上述obj2=obj1,实际上传递的只是obj1的内存地址,所以obj2和obj1指向的是同一个内存数据,所以这个内存数据中值的改变对obj1和obj2都有影响。这个过程是不同于深浅拷贝的!
4.1.1 到底什么是浅拷贝?
MDN中数组的slice方法中有这句话 ,slice不会修改原数组,只会返回一个浅复制了原数组中的元素的一个新数组。原数组的元素会按照下述规则浅拷贝...那就用slice来验证一下什么是浅拷贝:
var a = [ 1, 3, 5, { x: 1 } ];
var b = Array.prototype.slice.call(a);
b[0] = 2;
b[3].x = 2
console.log(a); // [ 1, 3, 5, { x: 2 } ];
console.log(b); // [ 2, 3, 5, { x: 2 } ];
这里b[0] = 2;时候a[0]没有随着改变,b[3].x = 2时候a[3].x发生了变化。
MDN中splice的规则:
如果该元素是个对象引用 (不是实际的对象),slice会拷贝这个对象引用到新的数组里。两个对象引用都引用了同一个对象。如果被引用的对象发生改变,则新的和原来的数组中的这个元素也会发生改变。
对于字符串、数字及布尔值来说(不是 String、Number 或者 Boolean 对象),slice会拷贝这些值到新的数组里。在别的数组里修改这些字符串或数字或是布尔值,将不会影响另一个数组。
- 综上:浅拷贝:新的数据复制了原数据中 非对象属性的值 和 对象属性的引用,也就是说对象属性并不复制到内存,但非对象属性的值却复制到内存中。
- 而深拷贝会另外拷贝一份一个一模一样的对象,从堆内存中开辟一个新的区域存放新对象,新对象跟原对象不共享内存,修改新对象不会改到原对象。
4.2 如何实现浅拷贝?
那怎么才能不引用同一个堆中的数值呢?这就涉及到了其他拷贝方式,我们来实现一下:
4.2.1.使用循环实现只复制一层的浅拷贝
//例3
var obj1 = {name:'aa',age:18}
var obj2 = {}
for(const key in obj1){
obj2[key] = obj1[key]
}
obj2.name = 'bb'
console.log(obj1) // { name: "aa", age: 18 }
console.log(obj2) // { name: "bb", age: 18 }
4.2.2.使用手动复制实现只复制一层的浅拷贝
//例4
var obj1 = {name:'aa',age:18}
var obj2 = {
name:obj1.name,
age:obj1.age
}
obj2.name = 'bb'
console.log(obj1) // { name: "aa", age: 18 }
console.log(obj2) // { name: "bb", age: 18 }
在例4中,我们再栈内存var obj2 = {}新建了一个地址指针,通过赋值,在堆中复制了name:‘aa’,age:18,obj2指向新的堆内存地址;
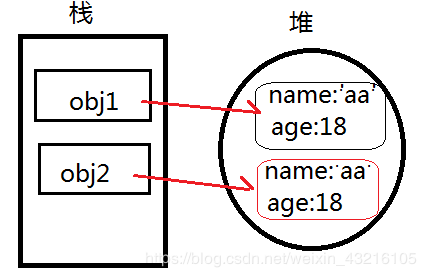
obj2.name = 'bb'时obj2指向的内存中的name改变,并不影响obj1中的值,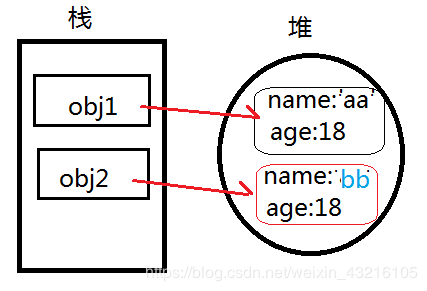
4.2.3.通过Object.assign()实现一层的浅拷贝
//例5
let obj1 = { a: { b:'bb1'}, c: 'bb1'}
let obj2 = Object.assign({},obj1)
obj2.a.b = 'bb2';
obj2.c = 'cc2'
console.log(obj1); // { a:{ b: "bb2" }, c: "bb1" }
console.log(obj2); // { a:{ b: "bb2" }, c: "cc2" }
例5中的ES6中的Object.assign方法,如果对象只有一层的话可以使用,其原理和例4相同是:先新建一个空对象,在堆中复制相同的属性,obj2指向另一个内存地址,但是这个方法不能使用在多层深拷贝!
4.2.4.Array.prototype.slice实现浅拷贝
//例6
var a = [ 1, 3, 5, { x: 1 } ];
var b = Array.prototype.slice.call(a);
b[0] = 2;
b[3].x = 2
console.log(a); // [ 1, 3, 5, { x: 2 } ];
console.log(b); // [ 2, 3, 5, { x: 2 } ];
上面已经解析过了,不再解析。
4.2.5.Array.prototype.concat实现浅拷贝
//例7
let array = [{a: 1}, {b: 2},666];
let array1 = [{c: 3},{d: 4}];
let array2= array.concat(array1);
array1[0].c= 123;
array[0].a = 456
array[2] = 999
console.log(array);// { a: 456 },{ b: 2 },999]
console.log(array1);// [ { c: 123 }, { d: 4 } ]
console.log(array2);// [ { a: 456 }, { b: 2 },666 { c: 123 }, { d: 4 } ]
这里array2就只实现了一层的拷贝,数值类型被复制,所以array[2] = 999时候array2[2] = 666没有改变,但是array2和array内层的对象引用地址相同,所有array[0].a = 456的时候array2也跟着变化了。
4.2.6.使用es6的扩展运算符 ... 实现浅拷贝
//例8
let obj1 = [{ b:1}, 2]
let obj2 = [...obj1]
obj2[0].b = 'bb2';
obj1[1] = 3
console.log(obj1); // [{ b: "bb2" }, 3]
console.log(obj2); // [{ b: "bb2" }, 2]
扩展运算符只能用在可迭代的对象上,不会改变原数组,只会返回一个浅拷贝了原数组中的元素的一个新数组。
4.2.7.通过第三方库Lodash来实现浅拷贝
var objects = [{ 'a': 1 }, { 'b': 2 }];
var shallow = _.clone(objects);
console.log(shallow[0] === objects[0]);
4.3 如何实现深拷贝?
4.3.1.通过JSON.parse(JSON.stringify(obj1))实现深拷贝
//例9
var obj1 = { body: { a: 10 } };
var obj2 = JSON.parse(JSON.stringify(obj1));
obj2.body.a = 20;
console.log(obj1);// { body: { a: 10 } }
console.log(obj2);// { body: { a: 20 } }
console.log(obj1 === obj2);// false
console.log(obj1.body === obj2.body);// false
这个方法是开发中最常用也是最简单的,哈哈,but 你以为真的这么简单吗?这个深拷贝也是有缺陷的!
JSON.parse(JSON.stringify(obj1))的原理是:通过JSON.stringify(obj1)把obj1转化为字符串,再用JSON.parse把字符串转化为一个新对象来进行拷贝;
- 这就只能拷贝数据类型,而拷贝不了对象的原型链,构造函数上面的方法或属性;
- 而且使用这个方法去拷贝的前提是 数据必须是JSON格式,如果你要拷贝的引用类型为:RegExp,function是没有办法实现的!
4.3.2.通过例1循环递归赋值实现对象的深拷贝
//例10
let obj1 = {
name: 'aa',
age: 18,
data: {
mom: '小红',
else: {
money: 9999
}
}
}
function clone(params) {
if (typeof params === 'object') {
let obj2 = {}
for (const key in params) {
obj2[key] = clone(params[key])
}
return obj2
} else {
return params
}
}
let obj3 = clone(obj1)
obj3.data.mom = '小明'
obj3.age = 60
obj3.data.else.money = 666
console.log(obj1);
//{"name":"aa","age":18,"data":{"mom":"小红","else":{"money":9999}}}
console.log(obj3);
//{"name":"aa","age":60,"data":{"mom":"小明","else":{"money":666}}}
当然,通过递归就能实现深拷贝,但是还是会有很多性能问题,在此就不一一例举了,可以看这篇文章去加深自己的理解:面试特供深拷贝,我日常开发真的不会这样写的深拷贝!!
4.3.3.通过第三方库Lodash来实现深拷贝
var objects = [{ 'a': 1 }, { 'b': 2 }];
var deep = _.cloneDeep(objects);
console.log(deep[0] === objects[0]);//false
这个库还是很好用的,简单操作。
4.4 总结浅拷贝和深拷贝
浅拷贝:创建一个新对象,这个对象有着原始对象属性值的一份精确拷贝。如果属性是基本类型,拷贝的就是基本类型的值,如果属性是引用类型,拷贝的就是内存地址 ,所以如果其中一个对象改变了这个地址,就会影响到另一个对象。
深拷贝:将一个对象从内存中完整的拷贝一份出来,从堆内存中开辟一个新的区域存放新对象,且修改新对象不会影响原对象。
区别:浅拷贝是一层数据的拷贝,深拷贝是多层的拷贝
| 类型 | 和原数据是否指向同一地址 | 原数据只有一层数据 | 原数据有多层子数据 |
|---|---|---|---|
| 赋值 | 是 | 新对象改变 会 使原数据一同改变 | 改变 会 使原数据一同改变 |
| 浅拷贝 | 否 | 新对象改变 不会 使原数据改变 | 改变 会 使原数据一同改变 |
| 深拷贝 | 否 | 新对象改变 不会 使原数据一同改变 | 改变 不会 使原数据一同改变 |
参考链接:
