

总结
本质是,把对象转换为字符串(json格式)。
我认为,把转换,叫做序列化,很肯,其实,根本不是序列化,也和序列化没有什么关系,因为不是二进制,也不是字节数组。
只是字符串。而且是字符串拼接。
记住这句话,就是拼接字符串而已,基于这个思路,研究源码,一下子就看懂了。
代码例子
最终的输出结果如下,
输出:
{"id":0,"name":"json"} //对象转字符串
User [id=0, name=json] //字符串转对象
源码流程
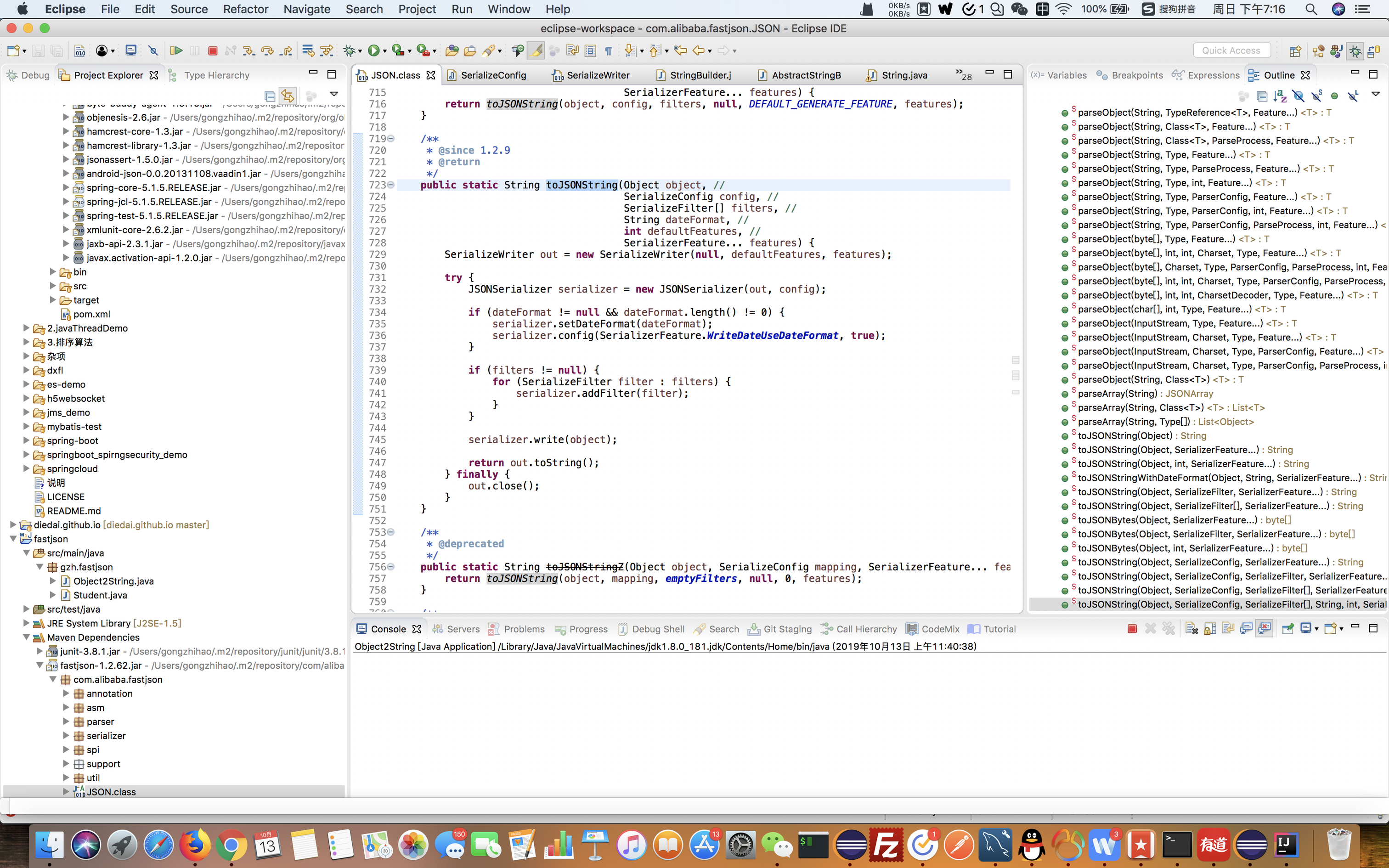
其实,最核心的业务方法,就在这里。其他的地方,基本上不用看了。还有一点,最重要的是,数据存储在哪里?哪个类?
拼接数据
/**
* @since 1.2.9
* @return
*/
public static String toJSONString(Object object, // 输入数据
SerializeConfig config, //
SerializeFilter[] filters, //
String dateFormat, //
int defaultFeatures, //
SerializerFeature... features) {
SerializeWriter out = new SerializeWriter(null, defaultFeatures, features);
try {
JSONSerializer serializer = new JSONSerializer(out, config);
if (dateFormat != null && dateFormat.length() != 0) {
serializer.setDateFormat(dateFormat);
serializer.config(SerializerFeature.WriteDateUseDateFormat, true);
}
if (filters != null) {
for (SerializeFilter filter : filters) {
serializer.addFilter(filter);
}
}
serializer.write(object); //把对象的字段(name/value)拼接到字符串去
return out.toString(); //输出数据
} finally {
out.close();
}
}
数据存储在哪里?
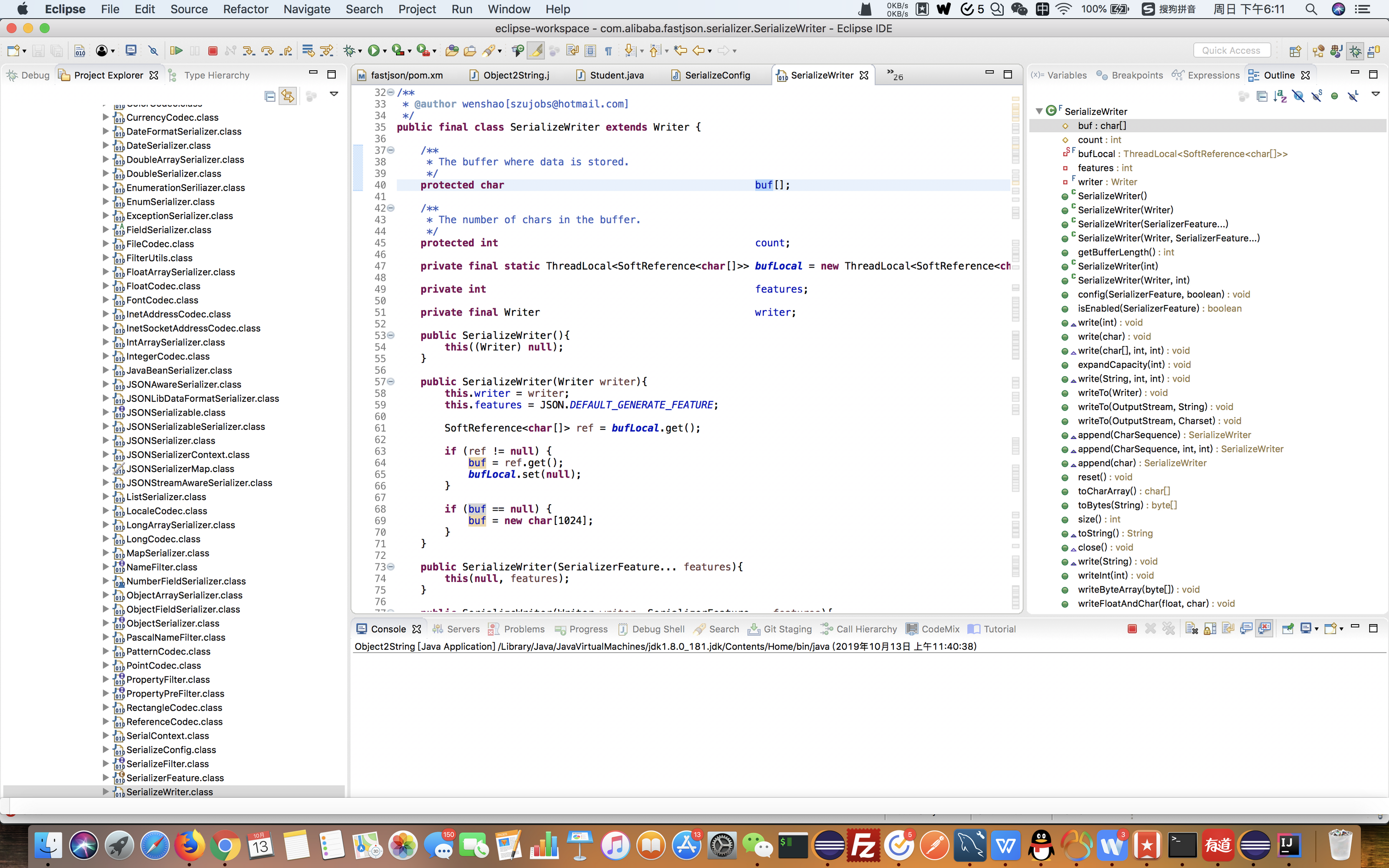
本质上是字符数组,即存储到字符数组。其实就是字符串,字符数组和字符串等价。
该类的作用? 1.存储数据 2.写数据
存储数据,是因为字符数组。
写数据,是因为写类。就是,实现了Writer的方法,没有使用jdk里的写类。
代码
public final class SerializeWriter extends Writer {
/**
* The buffer where data is stored.
*/
protected char buf[]; //字符数组
/**
* The number of chars in the buffer.
*/
protected int count;
private final static ThreadLocal<SoftReference<char[]>> bufLocal = new ThreadLocal<SoftReference<char[]>>();
private int features;
private final Writer writer; //写类,其实就是当前类,实现了Writer的写方法。所谓写方法,其实就是拼接字符串,和StringBuilder.append()方法作用一样。
对象转字符串的本质
对象转字符串的本质,是把对象的数据,即name/value拼接起来,拼接为字符串。
代码
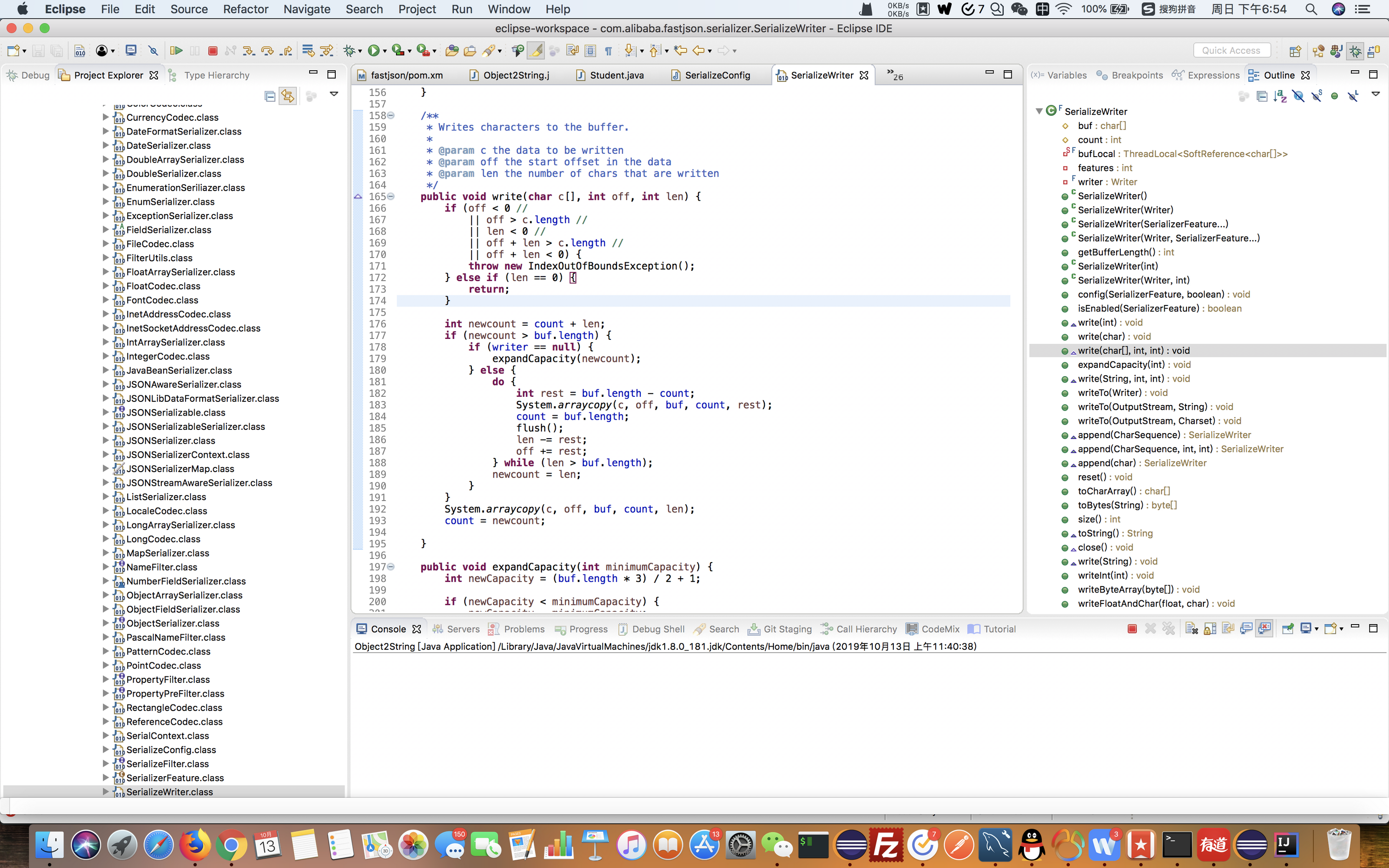
/**
* Writes characters to the buffer.
*
* @param c the data to be written
* @param off the start offset in the data
* @param len the number of chars that are written
*/
public void write(char c[], int off, int len) {
if (off < 0 //
|| off > c.length //
|| len < 0 //
|| off + len > c.length //
|| off + len < 0) {
throw new IndexOutOfBoundsException();
} else if (len == 0) {
return;
}
int newcount = count + len;
if (newcount > buf.length) {
if (writer == null) {
expandCapacity(newcount);
} else {
do {
int rest = buf.length - count;
System.arraycopy(c, off, buf, count, rest);
count = buf.length;
flush();
len -= rest;
off += rest;
} while (len > buf.length);
newcount = len;
}
}
System.arraycopy(c, off, buf, count, len);//本质,就是把一个字符数组复制到另外一个字符数组。
如果是第二个数据,那么拼接到第一个数据的后面即可。
count = newcount;
}
字符串转对象的本质
字符串转对象的本质是,解析字符串里的数据,再加上类,基于反射,创建了一个对象。
解析,就是解析字符串(json格式),和解析其他的格式,没有任何不同。比如,解析xml,xml也是字符串,不过格式不同而已。其他格式的字符串,也是同理。
为什么要自己实现写类,没有使用jdk的写类?
因为速度快。
具体原因
fastjson作者的解释。
为什么Fastjson能够做到这么快? 一、Fastjson中Serialzie的优化实现 1、自行编写类似StringBuilder的工具类SerializeWriter。 把java对象序列化成json文本,是不可能使用字符串直接拼接的,因为这样性能很差。比字符串拼接更好的办法是使用java.lang.StringBuilder。StringBuilder虽然速度很好了,但还能够进一步提升性能的,fastjson中提供了一个类似StringBuilder的类com.alibaba.fastjson.serializer.SerializeWriter。
SerializeWriter提供一些针对性的方法减少数组越界检查。例如public void writeIntAndChar(int i, char c) {},这样的方法一次性把两个值写到buf中去,能够减少一次越界检查。目前SerializeWriter还有一些关键的方法能够减少越界检查的,我还没实现。也就是说,如果实现了,能够进一步提升serialize的性能。 www.iteye.com/blog/wensha…
总结
fastjson的本质是,拼接字符串,和StringBuilder的作用一样。 两个类,不管是fastjson实现的,还是jdk的StringBuilder,本质都是:
System.arraycopy(value, srcBegin, dst, dstBegin, srcEnd - srcBegin); //最终都是调用系统方法
