

kubectl是kubernetes的自带客户端,可以直接操作kubernetes
1.获取资源 不加参数-n 获取默认空间资源
kubectl get nodes 查看集群所有节点
kubectl get pods 查看所有pod
kubectl get service 查看所有服务
kubectl get deployment 查看部署的所有应用
kubectl get replicasets 查看所有副本
2.查看pod控制台日志,不返回一直看
kubectl logs -f podid
3.进入pod
kubectl exec podid --ls 查看pod根目录下内容
kubectl exec podid --less ./log/uhome.log 查看pod日志文件
4.kubectl explain pod.spec | more 观察pod下面的spec里面可以看设置的内容 还可以很细 kubectl explain pod.spec.containers.env.value | more
9.关于master节点
| 组件 | 说明 |
|---|---|
| apiserver | 部署的yaml文件传给apiserver,负责实现 api server 唯一可以和etcd 数据库交互的组件 |
| controller manager | 管理资源对象 |
| schedualer | 调度Node,发布Pod |
| etcd | 用于存储集群中所有对象产生的数据 |
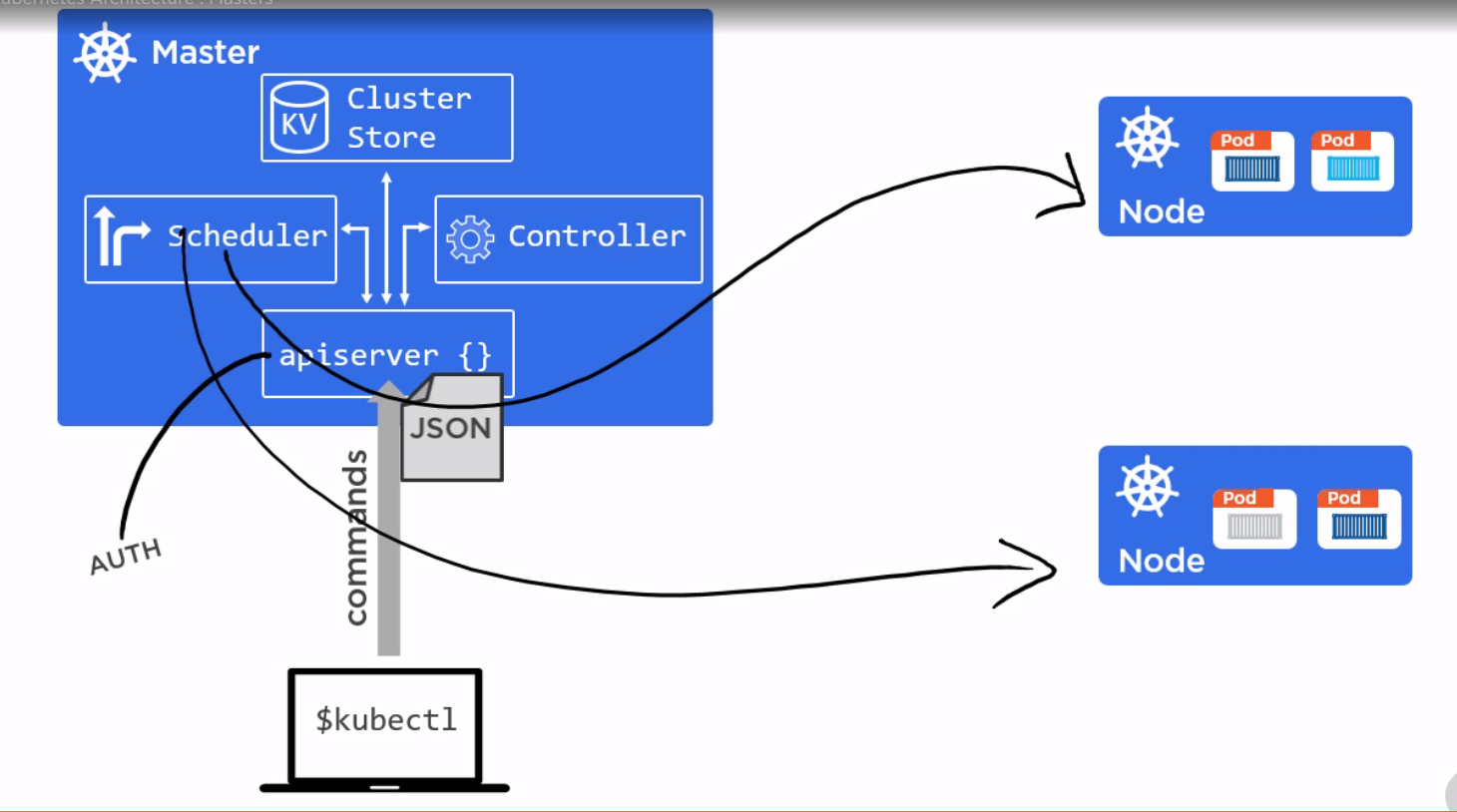
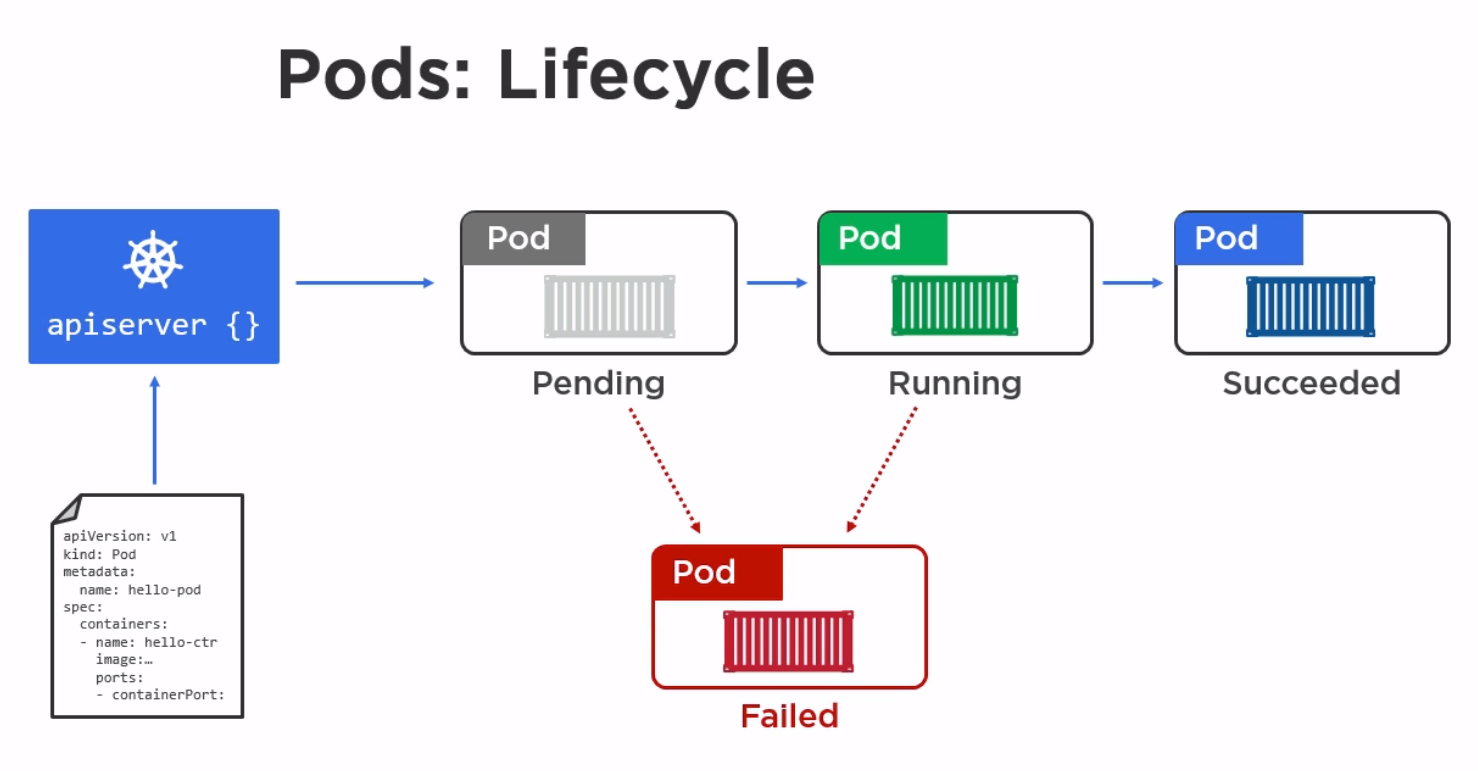
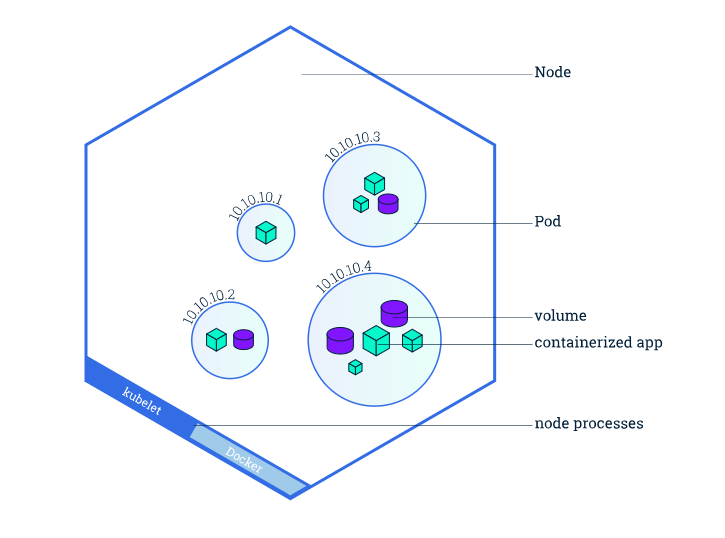

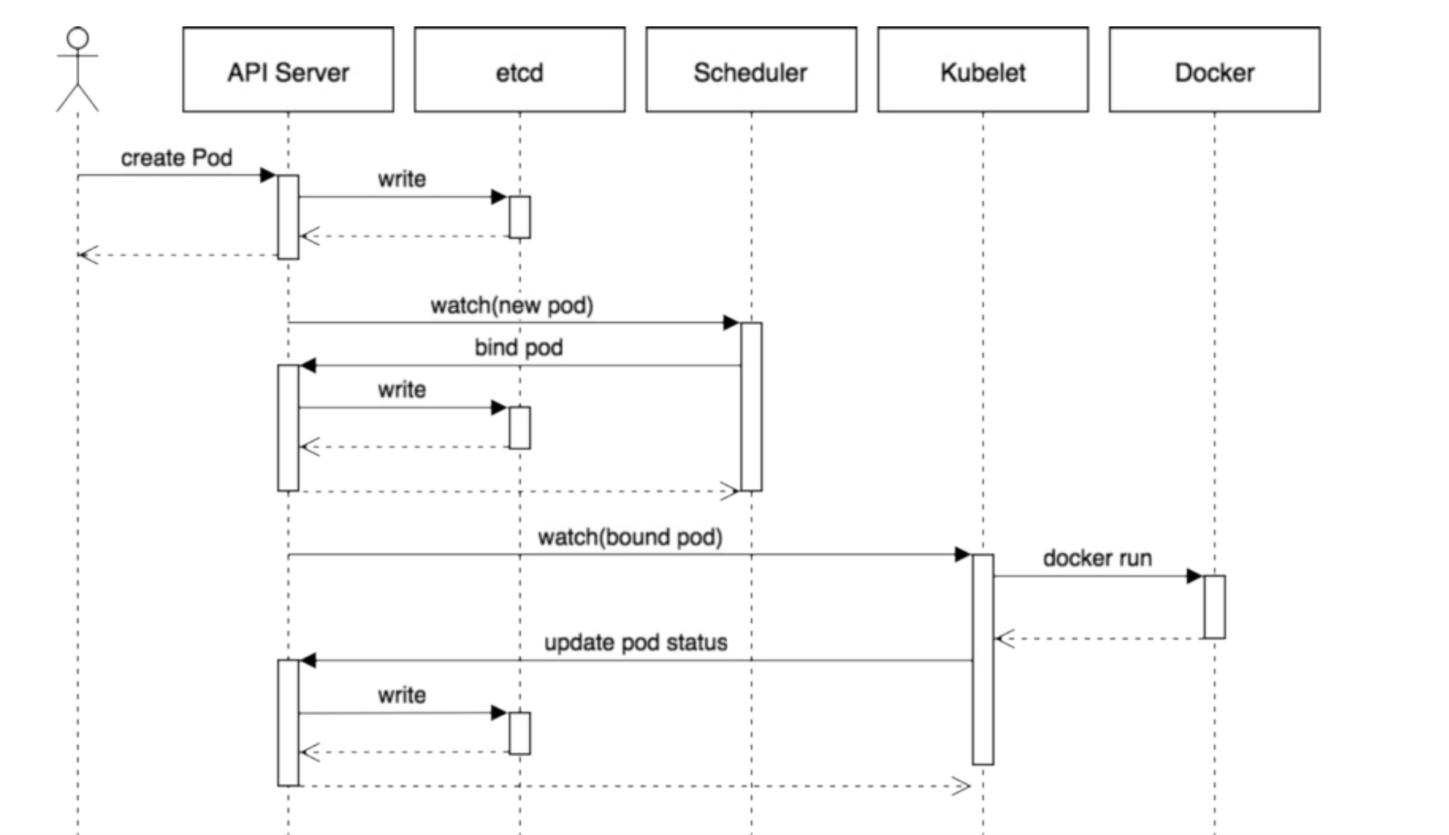


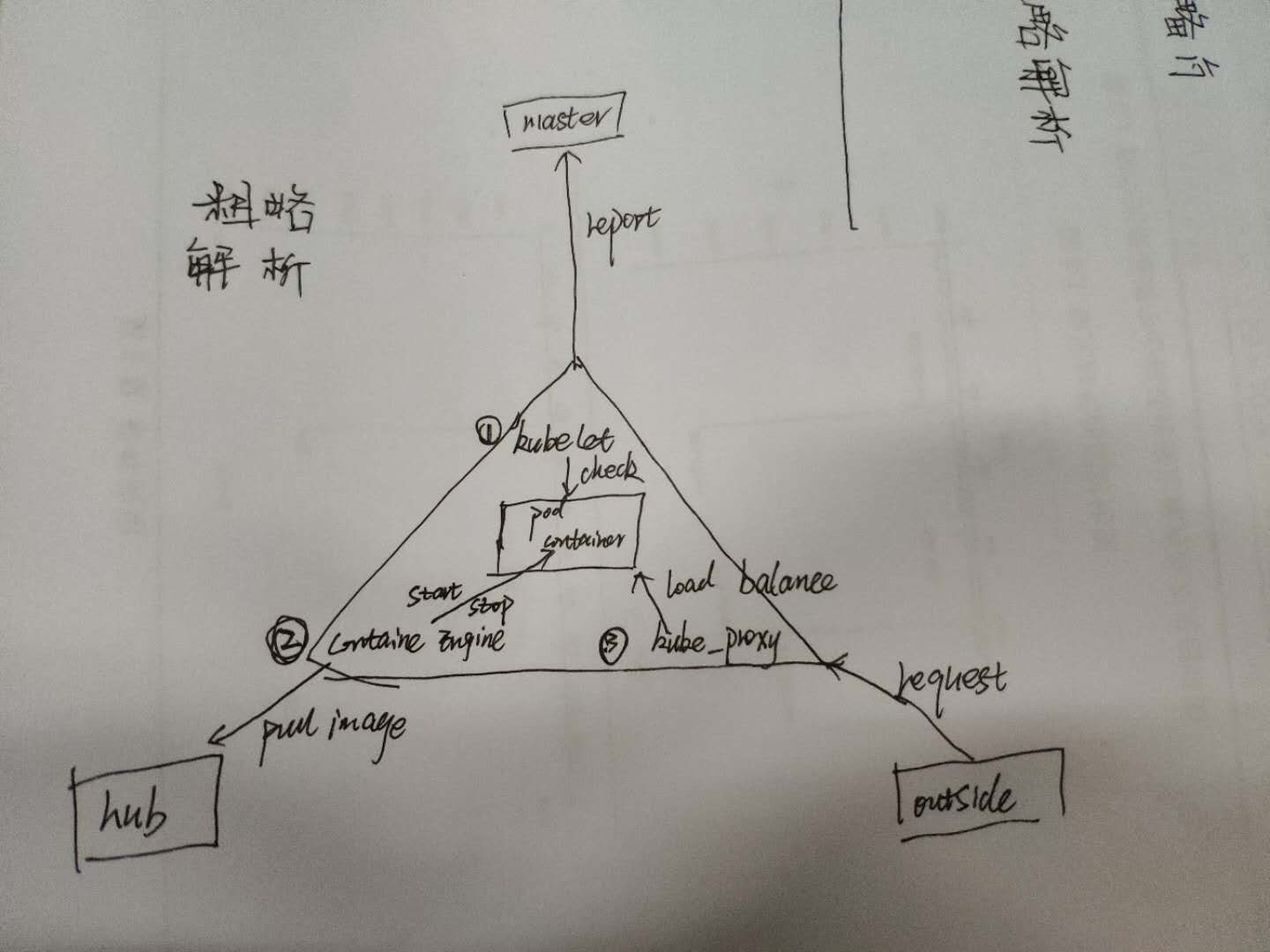
下面描述一个完整的用replicaset创建的pod Kubectl apply 会向apiserver发消息,apiserver将消息存在cluster store ,controller manager 会观察cluster store ,问有没有工作要做,因为现在有一个replicaset,会为这个replicaset启动一个controller,controller启动正确个数的pod,通过向scheduler发消息,scheduler告诉apiserver要在哪个节点部署pod,并且将这些信息存储在cluster store ,节点上的kubelet会一直问apiserver有没有工作要做,当知道有个pod要部署,kubelet会告诉节点上的docker runtime去启动pod中描述的容器,然后 启动pod
- 一个结点中包含的组件
| 组件 | 作用 |
|---|---|
| kubelet | 每个节点上都运行一个 kubelet 服务进程,默认监听 10250 端口,接收并执行 master 发来的指令,管理 Pod 及 Pod 中的容器。每个 kubelet 进程会在 API Server 上注册节点自身信息,定期向 master 节点汇报节点的资源使用情况,并通过 cAdvisor 监控节点和容器的资源 |
| container engine | 通常是docker,负责拉取镜像,运行/停止容器 |
| kube-roxy | kubernetes网络管理 通过service负载均衡所有pod |
kubelet
每一个结点上都会有一个kubelet,kubelet的作用的是健康检查,如果发现pod里容器没
有启动成功,会重启容器,然后再次检查,如果一个pod在node上启动失败,kubelet仅会
报告给master,让master做决定
大致描述,中间三角形是一个node

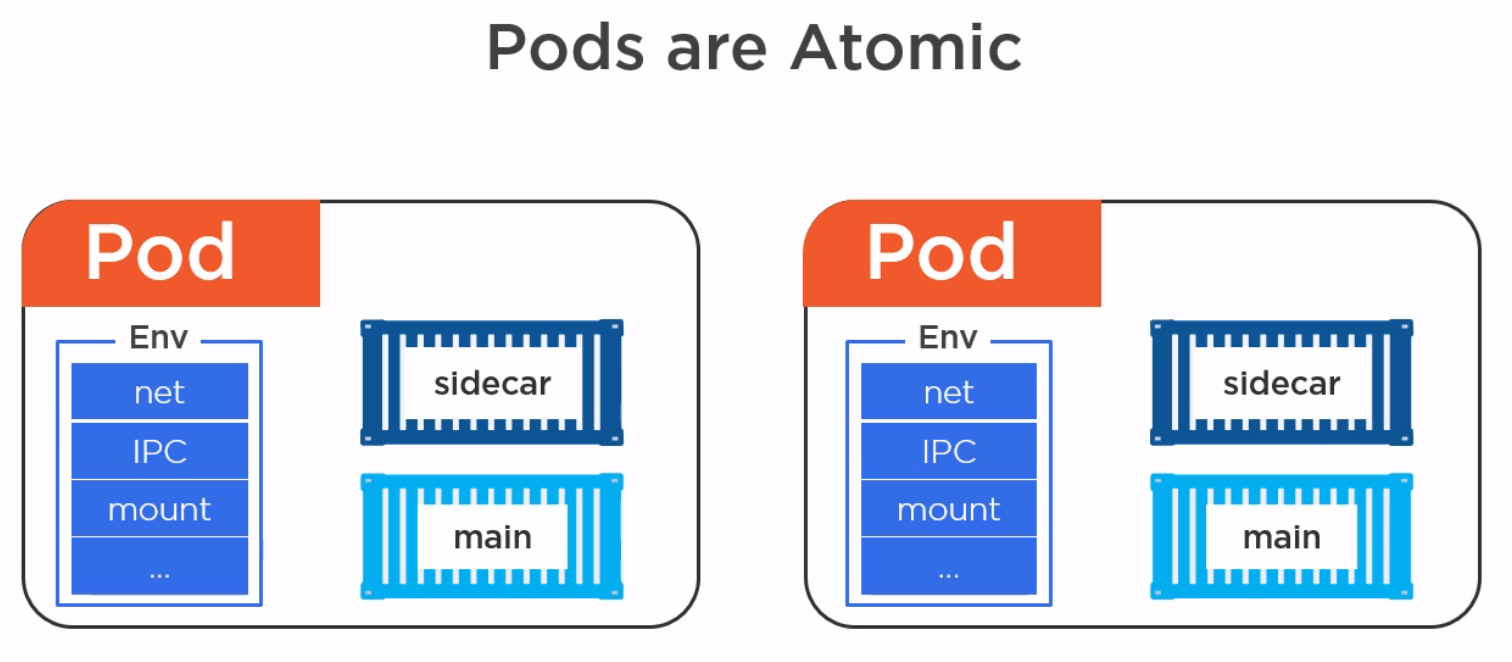
| 关于pod |
|---|
| pod是原子性的,不会出现同一时间多种状态 |
| pod有三种状态,等待,运行,死亡 |
| pod里面所有容器共享pod环境 |
| pod只有一个ip,强依赖的容器可以放在一个pod |
| 死后不会复生,master会重新启动一个pod,虽然可能内容一样,但是是重新生成的一个,策略是冷酷无情,死了搞个新的,并不会把旧的重启回来 |
| pod的ip经常变动,所以用service实现联系,service的ip是固定不动的,任何pod变动的消息都会通知service然后service去连接新的pod去除旧的,还能实现负载均衡,哪些pod属于service通过label实现 |
pod里面所有容器共享pod环境
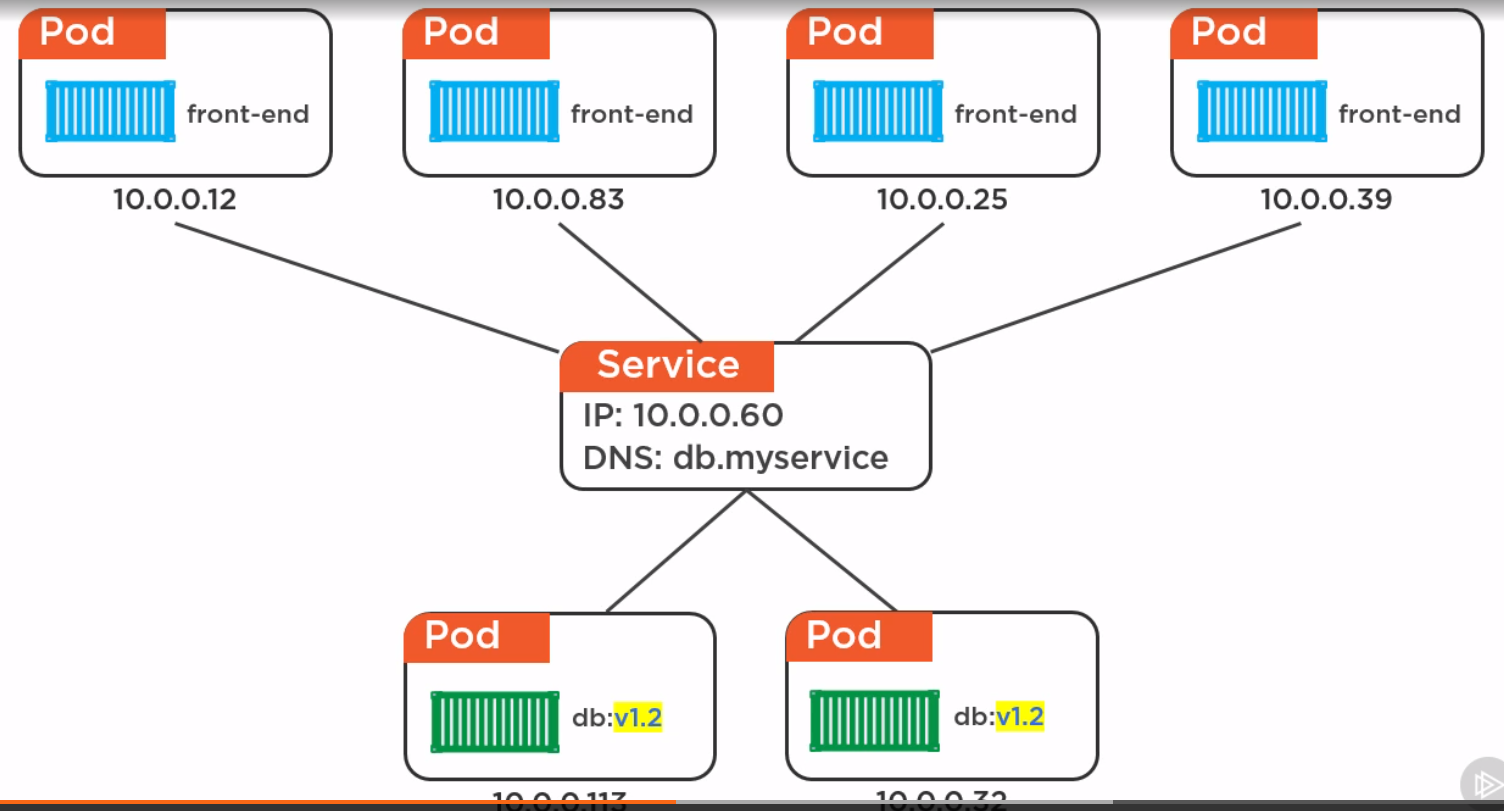
pod的ip经常变动,所以用service实现联系,service的ip是固定不动的,任何pod变动的消息都会通知service然后service去连接新的pod去除旧的,还能实现负载均衡,
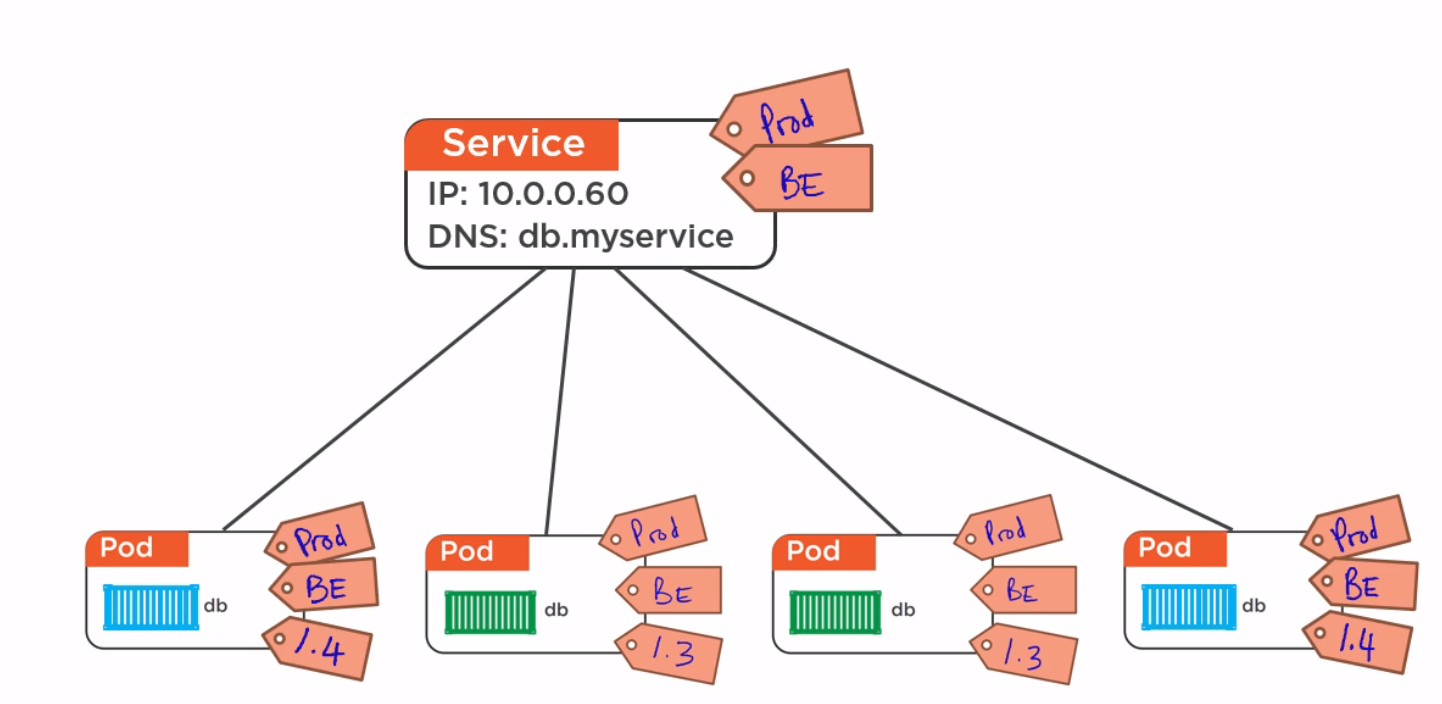
8.查看kubectl客户端目前与哪一个集群交互(可能有很多k8s集群)
kubectl config current-context
10.scale down
kubectl scale deployments/example --replicas=2
11.回滚
Deployment升级的历史记录
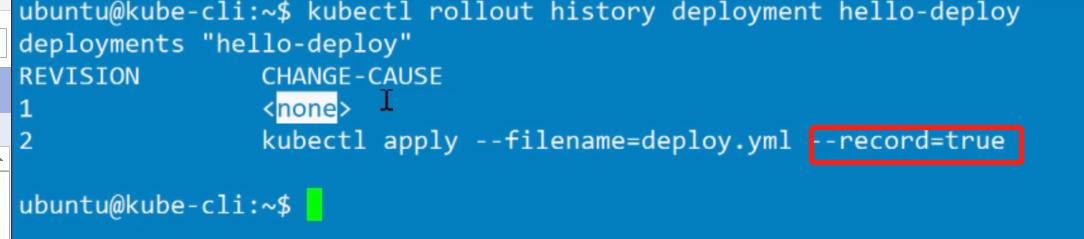
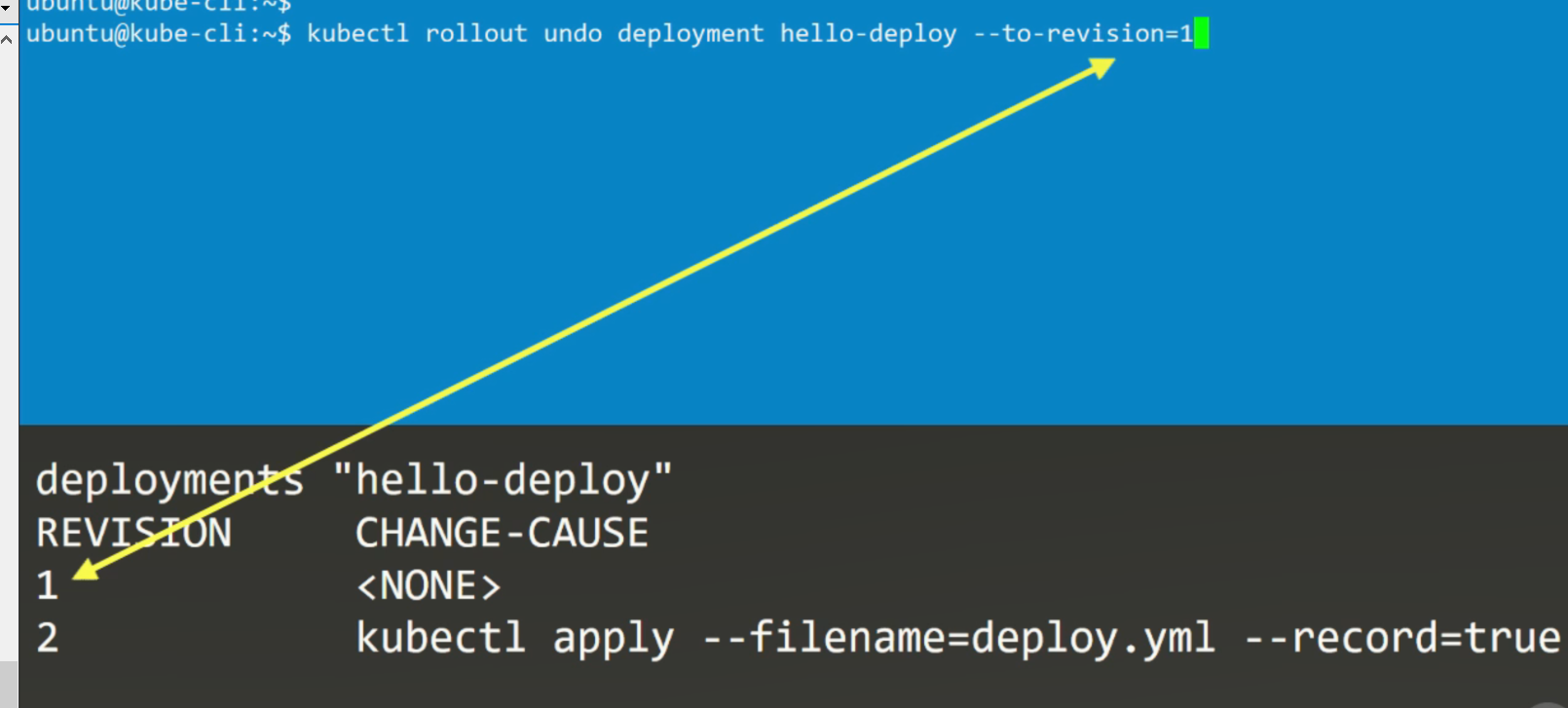
kubectl rollout undo deployments/example
12.持久化

13.关于service

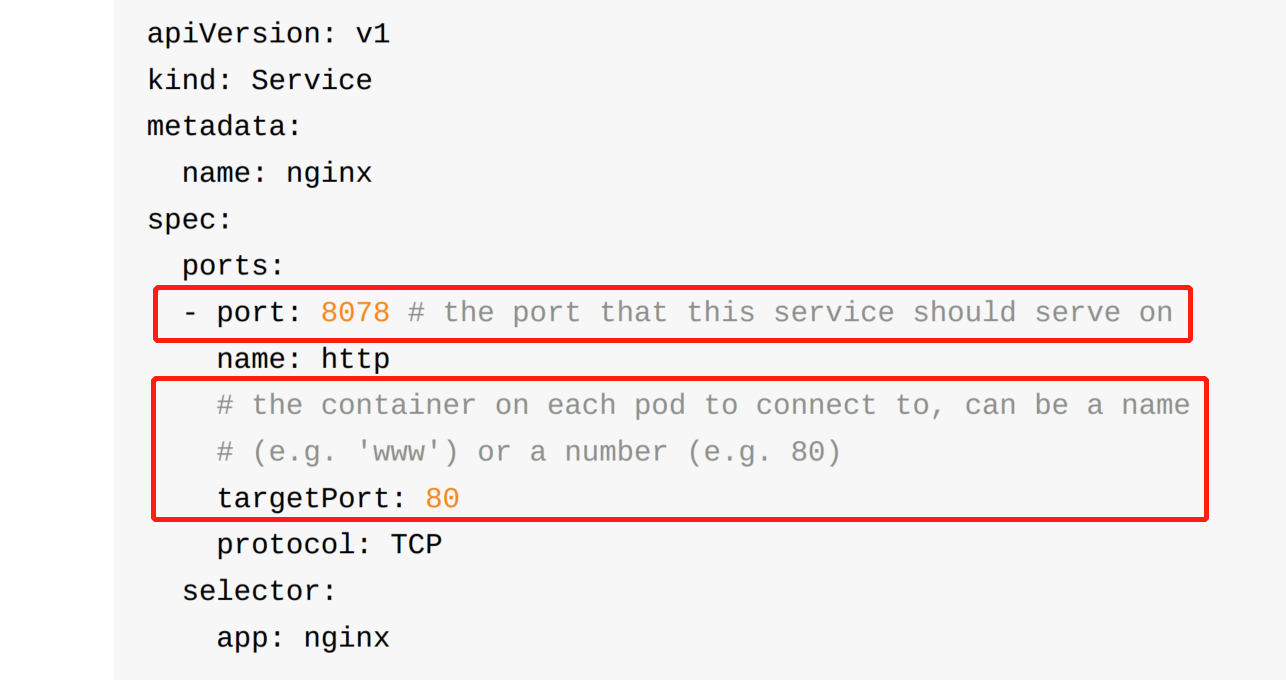
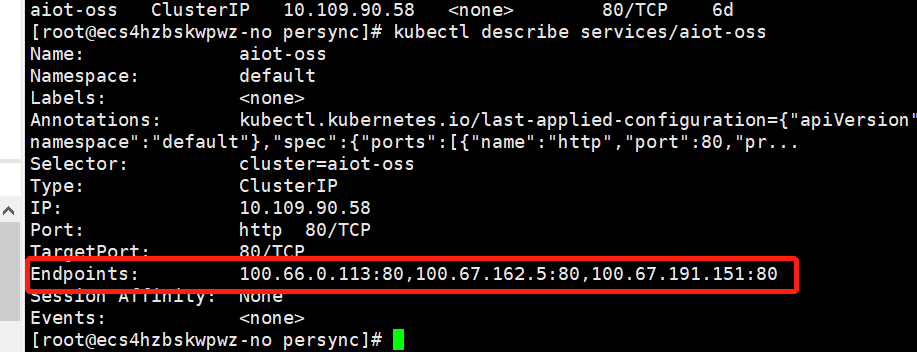
14.查看一个资源的详细信息
kubectl describe service exampleservice 查看服务的详细信息
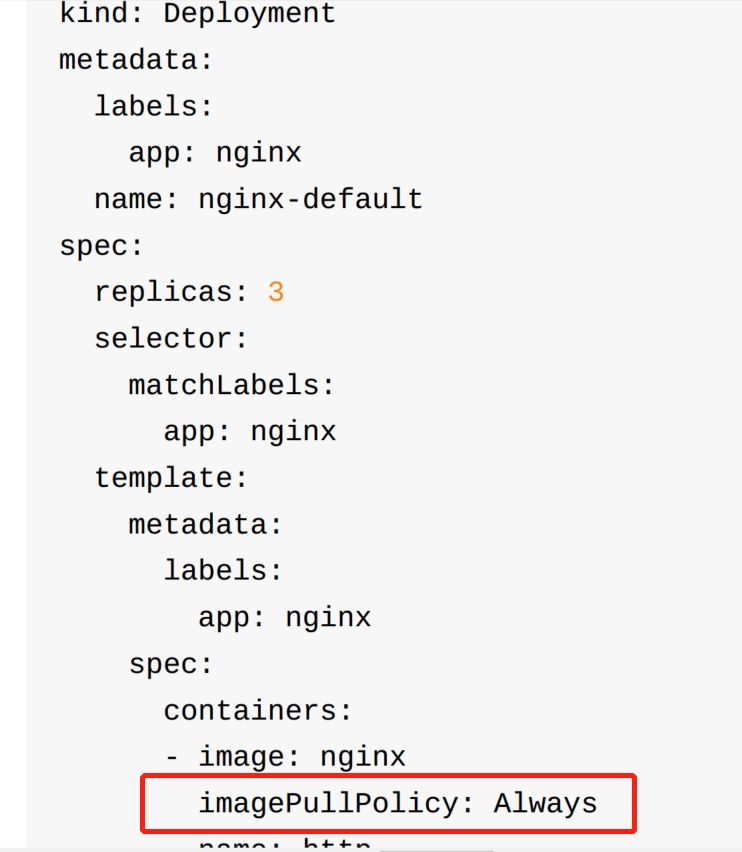
image表示镜像名词,imagePullPolicy每次重启容器,如果已经存在该版本镜像要不要取远程仓库拉取,always表示不管本地有没有都重新拉取
deployment比replication controller 好,更高层 deployment部署实际是起了一个replicationcontroller(也可以说是replica set),如果想更新,只需要更新yaml文件,然后内部实际会在起一个replica set,然后创建一个新的pod的同时,关上一个旧的pod,但是旧的set不会删掉,用来日后rollback,回复一个旧的pod的同时,关一个新的pod





19
NodePort在kubenretes里是一个广泛应用的服务暴露方式。Kubernetes中的service默认情况下都是使用的ClusterIP这种类型,这样的service会产生一个ClusterIP,这个IP只能在集群内部访问,要想让外部能够直接访问service,需要将service type修改为 nodePort
apiVersion: v1
kind: Pod
metadata:
name: influxdb
labels:
name: influxdb
spec:
containers:
- name: influxdb
image: influxdb
ports:
- containerPort: 8086
同时还可以给service指定一个nodePort值,范围是30000-32767,这个值在API server的配置文件中,用--service-node-port-range定义
kind: Service
apiVersion: v1
metadata:
name: influxdb
spec:
type: NodePort
ports:
- port: 8086
nodePort: 30000
selector:
name: influxdb
集群外就可以使用kubernetes任意一个节点的IP加上30000端口访问该服务了。kube-proxy会自动将流量以round-robin的方式转发给该service的每一个pod
20 service 和 deployment 流量是怎么传下去的文章
