

一、目标需求
- 实现一个报表展示
- 简单的报表操作,丰富的样式展示
- 存储大数据量
- 大数量情况下的秒级查询速度
- 多数据来源抓取
二、实现方案
- logstash抓取数据库数据
- ES做大数据量存储
- kibana做简单的大屏展示
- 还需要其他的工作:ES数据更新,处理ES数据提供复杂聚合数据
三、Elasticsearch-7.X
1、特点和优势
- 分布式的文档存储引擎
- 分布式的搜索引擎和分析引擎
- 分布式,支持PB级数据
2、如何做到全文检索
试想一下。如果我们想找一下含有“月”的古诗,我们会先去想哪些诗句包含月,例如“床前明月光”,包含月。这么在我们脑海里就有“床前明月光”为KEY,“月”为Value的索引。
什么是倒索引。如果我们事先在脑海里建立了,“月”为KEY,“静夜思”为Value的索引,这个问题也就不假思索的回答。这就是倒索引。
Lucene是如何做到的。建立索引分为一下几步:
- 1、取出关键词。步骤包含分词,词形还原,去除停顿词,同一小写等。
- 2、建立倒排索引。由关键词对应文章号(并非文章内容)、字符位置、关键词位置、出现频率、出现位置。分为词典文件、频率文件、位置文件。搜索索引时,关键字以字符顺序排序,查询时采用二分法查找,关系型数据库以B+树建立索引,因此搜索关键词上快很多。
- 3、压缩索引。关键词压缩为<前缀长度,后缀>。数字压缩为与上一值的差值。
3、名词
Near Realtime(NRT)
近实时,es从数据写入到数据被搜索到有一个延时(大概1秒),基于es执行的搜索和分析可以达到妙级
Cluster
集群,包含多个节点,每个节点属于哪个集群是通过一个配置(集群名称)来决定,节点可以分散到各个机器上。
Node
节点,集群中的一个节点,如果默认启动1个或者多个节点,那么他们自动组成一个集群。一个elasticsearch实例即就是一个节点。每个节点可以有多个shard,但是primary shard和对应replica shard 不能在同一个节点上。
index
索引,包含一堆具有相似结构的文档数据
type
类型,type是index中的一个逻辑数据分类,7.X版本只有一个
document
文档,es中最小的数据单元,有json串组成,里面包含多个field,每个field即是一个数据字段。
mapping
映射,一旦建立,无法修改,只能删除索引,重新建立,或者冗余数据。text:当一个字段是要被全文搜索的。keyword:类型适用于索引结构化的字段。字段只能通过精确值搜索到。
聚合-桶 聚合-指标
分类成为桶,统计成为指标
4、配置
ES的安装简单,chrome插件elasticsearch-head从git上找https://github.com/mobz/elasticsearch-head/tree/master/crx。crx文件,解压成文件夹,导入插件。
5、查询
版本变动很大,所有的API查官网的一手资料才是最准确的, 官方Search APIs:www.elastic.co/guide/en/el…
创建索引
/test
{
"settings": {
"number_of_shards": 3,
"number_of_replicas": 2
},
"mappings": {
"properties": {
"field1": {
"type": "text"
}
}
}
}
简单查询
分页
:9200/movie/adventure/_search?from=1&size=5
查询某列
:9200/movie/adventure/1?_source=name
字符串查询
:9200/movie/adventure/_search?q=name:life
DSL搜索
{
"query": {
"match": {
"tag": "中国"
}
}
}
DSL查询
- _score 相关性得分
正浮点型,分数越高,文档越相关
- term 完全匹配,需要映射字段不分词
- match 分词匹配
- match子句查询相关内容
- filter参数指示过滤器上下文
GET /_search
{
"query": {
"bool": {
"must": [
{ "match": { "title": "Search" }},
{ "match": { "content": "Elasticsearch" }}
],
"filter": [
{ "term": { "status": "published" }},
{ "range": { "publish_date": { "gte": "2015-01-01" }}}
]
}
}
}
组合查询
##### 实现以下sql
SELECT product
FROM products
WHERE (price = 20 OR productID = "XHDK-A-1293-#fJ3")
AND (price != 30)
##### 布尔过滤器, 过滤查询已被弃用,并在ES 5.0中删除。
必须(must) 匹配
不能(must not) 匹配
至少有一个语句要匹配
{
"bool" : {
"must" : [],
"should" : [],
"must_not" : [],
}
}
##### 查询
GET /my_store/products/_search
{
"query" : {
"bool" : {
"should" : [
{ "term" : {"price" : 20}},
{ "term" : {"productID" : "XHDK-A-1293-#fJ3"}}
],
"must_not" : {
"term" : {"price" : 30}
}
}
}
}
6、版本问题
- 有问题还是去ES官网社区查找
- ElasticSearch 7.x 默认不在支持指定索引类型
- 过滤查询已被弃用,并在ES 5.0中删除。
官方文档 www.elastic.co/guide/en/el… 2.X版本和5版本,中文官方 www.elastic.co/guide/cn/el…
7、关联查询
Elasticsearch多表关联问题是讨论最多的问题之一。ES可以实现关联查询,但是不推荐使用,性能也会有影响。
三种解决方案:
- nested
- join,只等关联同一个类型中的数据
- 宽表,可能聚合时候出现问题
参考连接:blog.csdn.net/laoyang360/…
8、参考链接
- term和match查询。 www.cnblogs.com/zhaijunming…
- 字段类型。 blog.csdn.net/chengyuqian…
- mapping映射设置。blog.csdn.net/zx711166/ar…
9、简单示例:
建立索引
/lhhb-order
{
"settings": {
"number_of_shards": 3,
"number_of_replicas": 2
},
"mappings": {
"properties": {
"cashname": {
"type": "keyword"
},
"memo_no": {
"type": "keyword"
},
"payment": {
"type": "double"
},
"create":{
"type": "date",
"format": "yyyy-MM-dd HH:mm:ss||yyyy-MM-dd||epoch_millis"
},
"remark":{
"type": "text"
}
}
}
}
添加数据
/lhhb-order/_doc/1
{
"cashname": "人民币",
"memo_no": "1233455754534",
"payment": 10000.12345,
"create":"2015-01-01 23:33:12",
"remark":"备注啊书法大赛打发士大夫"
}
基本查询
term是精确查询
match是模糊查询
gt : 大于
lt : 小于
gte : 大于等于
lte :小于等于
{
"query": {
"bool":{
"must": [
{ "range": { "create": {"gte": "2015-02-01"} }}
]
}
}
}
{
"query": {
"bool": {
"must": [
{ "match": { "title": "Search" }},
{ "match": { "content": "Elasticsearch" }}
],
"filter": [
{ "term": { "status": "published" }},
{ "range": { "publish_date": { "gte": "2015-01-01" }}}
]
}
}
}
聚合: 分类统计
{
"size" : 0,
"aggs" : {
"popular_colors" : {
"terms" : {
"field" : "color.keyword"
}
}
}
}
四、logstash
1、从数据库读取数据到ES
安装插件
logstash-7.3.2\bin 安装
logstash-plugin install logstash-input-jdbc
目录下放驱动文件
.conf文件
文件格式UTF-8
input {
jdbc {
jdbc_driver_library => "mysql-connector-java-5.1.33-bin.jar"
jdbc_driver_class => "com.mysql.jdbc.Driver"
jdbc_connection_string => "jdbc:mysql://IP:3306/test"
jdbc_user => "root"
jdbc_password => "****"
schedule => "*/1 * * * *"
jdbc_default_timezone => "Etc/UTC"
statement => "SELECT * FROM biz_transfer_info where id > :sql_last_value"
jdbc_paging_enabled => "true"
jdbc_page_size => "50000"
last_run_metadata_path => "E:\cyd\WorkPro\ELK\logstash-7.3.2\logstash-7.3.2\log\mysql_test.txt"
use_column_value => true
record_last_run => true
tracking_column => "id"
}
}
output {
stdout {
codec => json_lines
}
elasticsearch {
hosts => "127.0.0.1:9200"
index => "mysql_test"
}
}
启动
.\logstash.bat -f .\mysqldata.conf
问题:
最好参考官方文档
- 两次执行重复。调整定时时间间隔,最好使用ID控制执行到哪一行了。
- sql如何处理引号。编写成文件statement_filepath
- 可执行存储过程。
- SQL字段都需要是大写不然报错
五、kibana
1、安装
官网上的安装和运行都很简单。
- 目前最新的版本支持中文。
- 安装后可以选择导入测试数据
2、实际应用
- 起初想使用ES做报表和实时数据的仪表盘,后来发现,报表需要更加复杂的聚合统计和自由灵活的字段拖拽。
- kibana可以快速实现简单的可视化数据展示,可以快速实现简单的聚合。
- 报表的数据提供最终还是使用Logstash+Elastic方案,存储ES,如保证实时,还需要数据一致性,更新ES中的数据。从而实现PB级数据,复杂聚合秒查的特性。
- 实际调用API做复杂查询的时候,可是查看聚合可视化请求的body作为例子。
3、目录
4、仪表盘
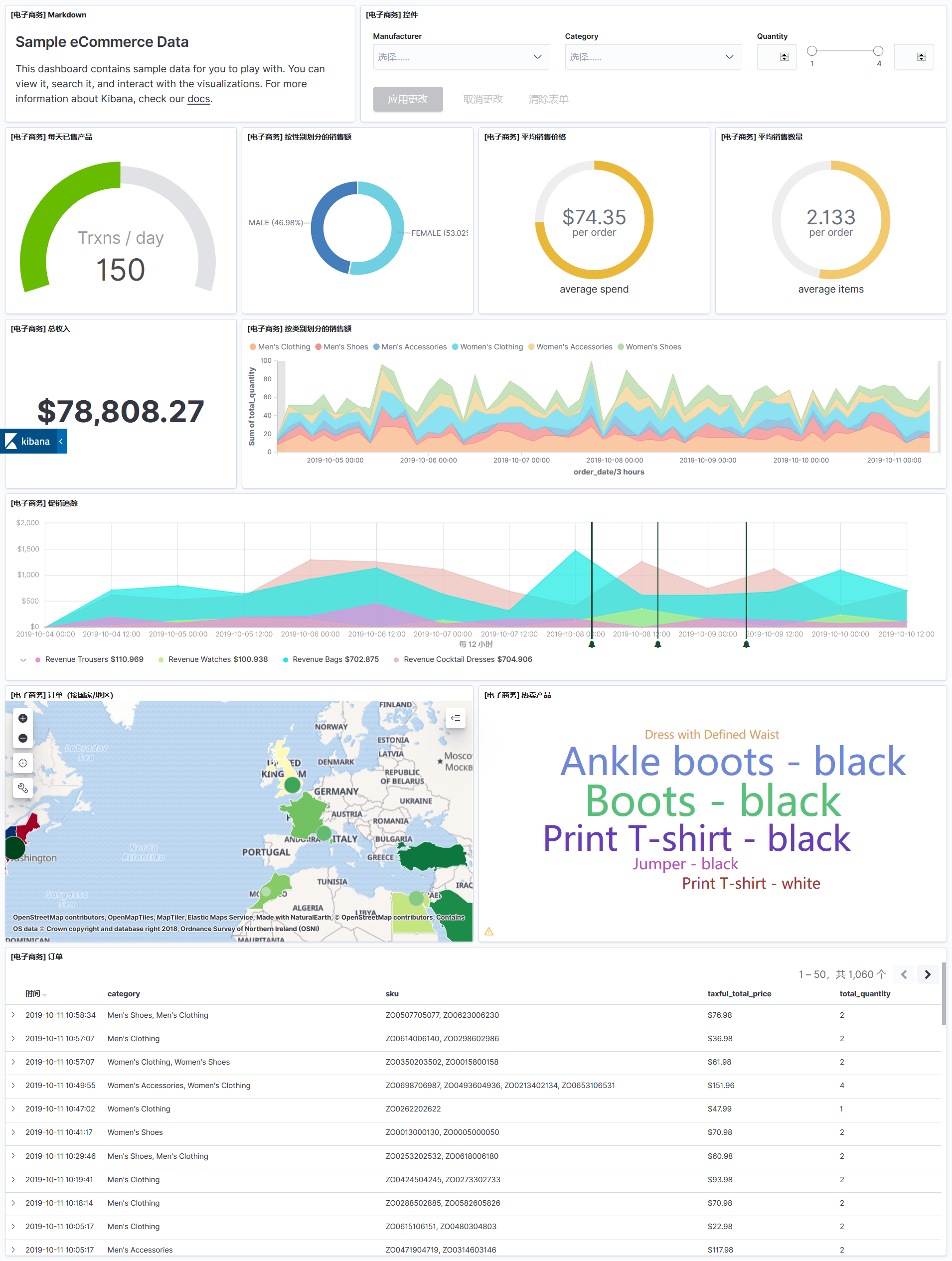
5、聚合可视化
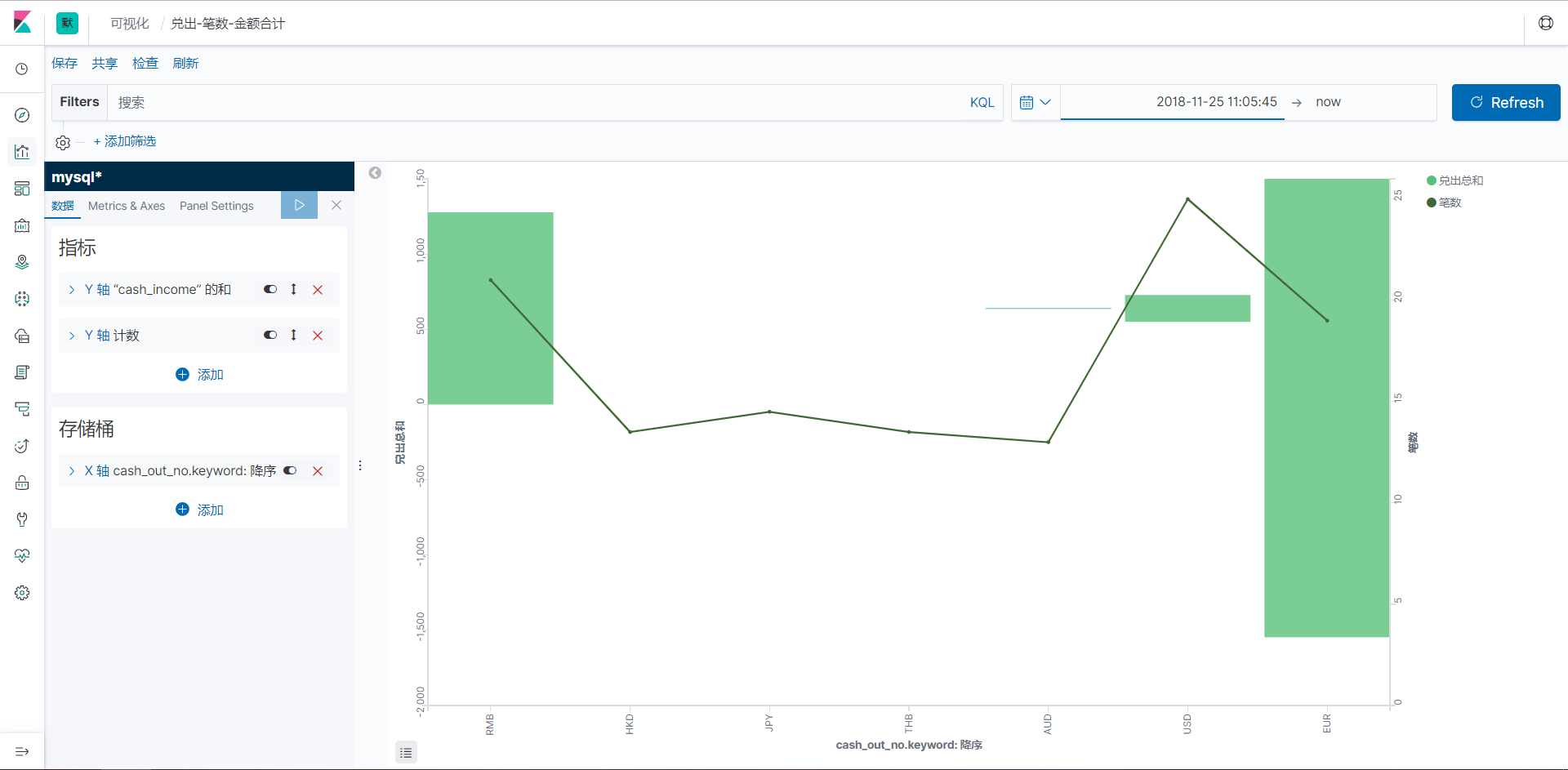
6、可视化类型
7、参考链接
kibana报表截图:elkguide.elasticsearch.cn/kibana/phan…
