

我和同事一直在维护一个面向高校学生和行业研究者的文本分析软件包。自然语言处理和文本挖掘分析领域发展很快,不断有新的理论和方法引入进来,比如近几年很热的神经网络和深度学习等,所以,要让自己的软件能有好的体验,也要跟上最新的发展,要不断地学习。
近期软件做了一次重大升级,在这个过程中,我们用了很多时间收集和整理了自然语言处理方面的知识和技术,通过几个研讨会,给自己充充电。
这篇文章就把我们内部研讨的知识骨架共享出来,这次梳理是从工程师的角度做的,肯定是很不严谨,但是可能不失实用价值。这个领域很大,虽然整理和研讨过程花了一些时间,但是依然像是走马观花,希望整理出来的内容可以做为深入探究的线索。
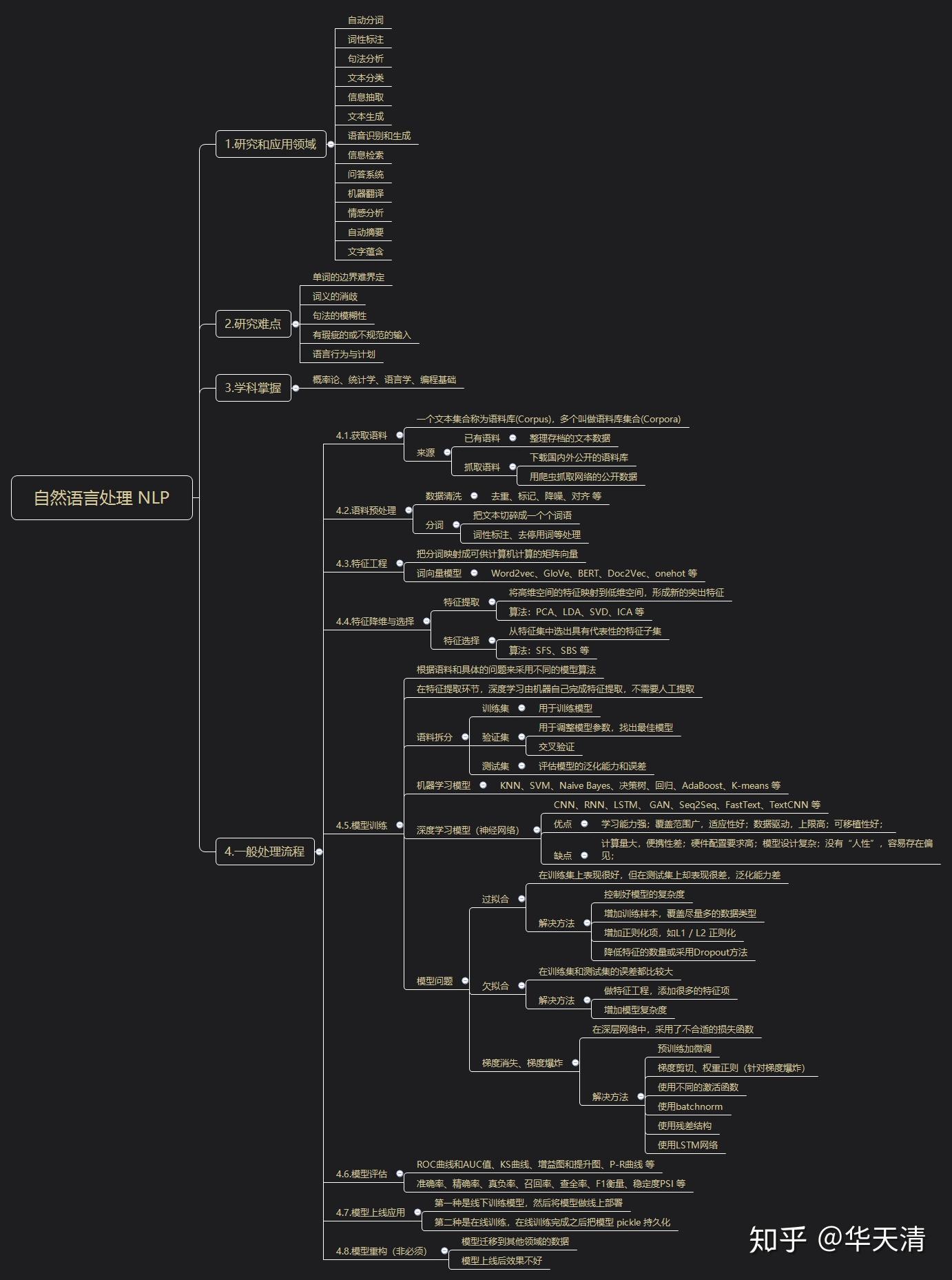
1,研究和应用领域
- 自动分词
- 词性标注
- 句法分析
- 文本分类
- 信息抽取
- 文本生成
- 语音识别和生成
- 信息检索
- 问答系统
- 机器翻译
- 情感分析
- 自动摘要
- 文字蕴含
2,研究难点
- 单词的边界难界定
- 词义的消歧
- 句法的模糊性
- 有瑕疵的或不规范的输入
- 语言行为与计划
3,学科掌握
概率论、统计学、语言学、编程基础
4,一般处理过程
4.1,获取预料
一个文本集合称为语料库(Corpus),多个叫做语料库集合(Corpora)。
来源:
(1)已有语料
整理存档的文本数据;
(2)抓取语料
下载国内外公开的语料库;
用爬虫抓取网络的公开数据;
4.2,预料预处理
(1)数据清洗
去重、标记、降噪、对齐 等;
(2)分词
把文本切碎成一个个词语;
词性标注、去停用词等处理;
4.3,特征工程
把分词映射成可供计算机计算的矩阵向量。
词向量模型:
Word2vec、GloVe、BERT、Doc2Vec、onehot 等;
4.4.特征降维与选择
(1)特征提取
将高维空间的特征映射到低维空间,形成新的突出特征;
算法:PCA、LDA、SVD、ICA 等;
(2)特征选择
从特征集中选出具有代表性的特征子集;
算法:SFS、SBS 等;
4.5.模型训练
根据语料和具体的问题来采用不同的模型算法。
在特征提取环节,深度学习由机器自己完成特征提取,不需要人工提取。
(1)语料拆分
训练集:用于训练模型;
验证集:用于调整模型参数,找出最佳模型、交叉验证;
测试集:评估模型的泛化能力和误差;
(2)机器学习模型
KNN、SVM、Naive Bayes、决策树、回归、AdaBoost、K-means 等;
(3)深度学习模型(神经网络)
CNN、RNN、LSTM、 GAN、Seq2Seq、FastText、TextCNN 等;
优点:学习能力强;覆盖范围广,适应性好;数据驱动,上限高;可移植性好;
缺点:计算量大,便携性差;硬件配置要求高;模型设计复杂;没有“人性”,容易存在偏见;
(4)模型问题
a. 过拟合
在训练集上表现很好,但在测试集上却表现很差,泛化能力差。
解决方法:
控制好模型的复杂度;
增加训练样本,覆盖尽量多的数据类型;
增加正则化项,如L1 / L2 正则化;
降低特征的数量或采用Dropout方法;
b. 欠拟合
在训练集和测试集的误差都比较大。
解决方法:
做特征工程,添加很多的特征项;
增加模型复杂度;
c. 梯度消失、梯度爆炸
在深层网络中,采用了不合适的损失函数。
解决方法:
预训练加微调;
梯度剪切、权重正则(针对梯度爆炸);
使用不同的激活函数;
使用batchnorm;
使用残差结构;
使用LSTM网络;
4.6,模型评估
ROC曲线和AUC值、KS曲线、增益图和提升图、P-R曲线 等;
准确率、精确率、真负率、召回率、查全率、F1衡量、稳定度PSI 等;
4.7,模型上线应用
第一种是线下训练模型,然后将模型做线上部署;
第二种是在线训练,在线训练完成之后把模型 pickle 持久化;
4.8,模型重构(非必须)
模型迁移到其他领域的数据;
模型上线后效果不好;
