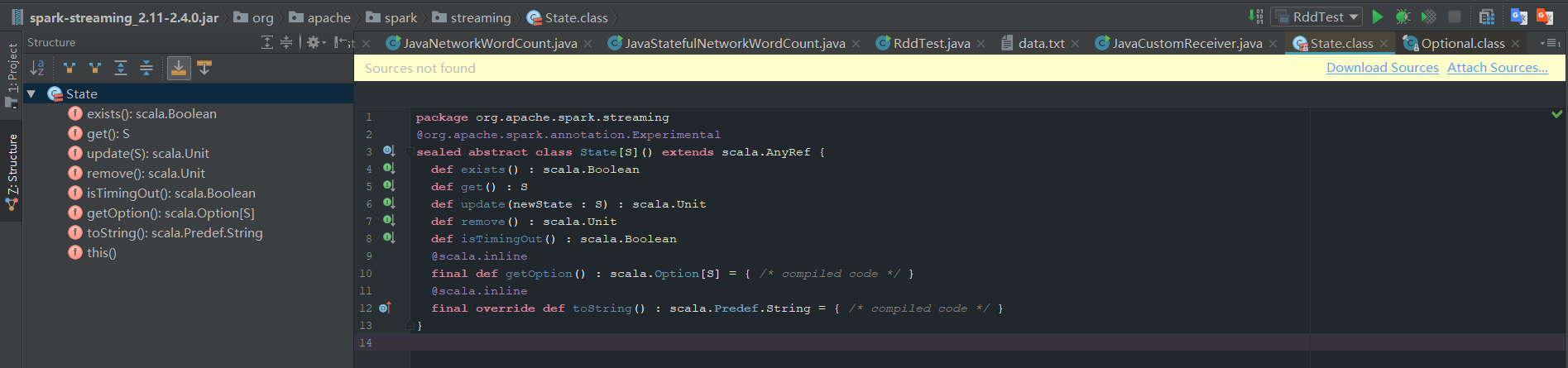
这次的代码是基于第一次简单的单词统计演化而来,新加入的功能从类名中可以看出,即stateful(有状态的)---可以记录历史输入的单词数据,这就是所谓的有状态吧。 除此之外要注意:这里使用的仍是netcat开启端口进行数据源的读取。这里有几个概念:数据源、接收器(Receiver)。
- 未来数据源可能来自文件系统如HDFS、kafka、flume,都要做相应的配置。
- 接收器也存在自定义的情况,但如从文件系统直接读取可不需要接收器,其他的情况内核cpu个数要大于接收器个数,否则可能出现接受数据却不处理数据的现象。
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaPairRDD;
import org.apache.spark.api.java.function.Function3;
import org.apache.spark.streaming.Durations;
import org.apache.spark.api.java.Optional;
import org.apache.spark.streaming.State;
import org.apache.spark.streaming.StateSpec;
import org.apache.spark.streaming.api.java.*;
import scala.Tuple2;
import java.util.Arrays;
import java.util.List;
import java.util.regex.Pattern;
/**
* Created by Chailx on 2019/9/26.
*/
public class JavaStatefulNetworkWordCount {
private static final Pattern SPACE = Pattern.compile(" ");
public static void main(String[] args) throws Exception{
SparkConf conf = new SparkConf().setMaster("local[2]").setAppName("JavaStatefulNetworkWordCount");
JavaStreamingContext jssc = new JavaStreamingContext(conf, Durations.seconds(5));
jssc.checkpoint(".");
//
// 初始化RDD with mapWithState
@SuppressWarnings("unchecked")
List<Tuple2<String, Integer>>tuples = Arrays.asList(new Tuple2<>("hello",1),new Tuple2<>("world",1));
JavaPairRDD<String ,Integer>initialRDD = jssc.sparkContext().parallelizePairs(tuples);
JavaReceiverInputDStream<String> lines = jssc.socketTextStream("localhost",9999);
JavaDStream<String> words = lines.flatMap(x ->Arrays.asList(SPACE.split(x)).iterator());
JavaPairDStream<String,Integer>wordsDstream = words.mapToPair(s -> new Tuple2<>(s,1));
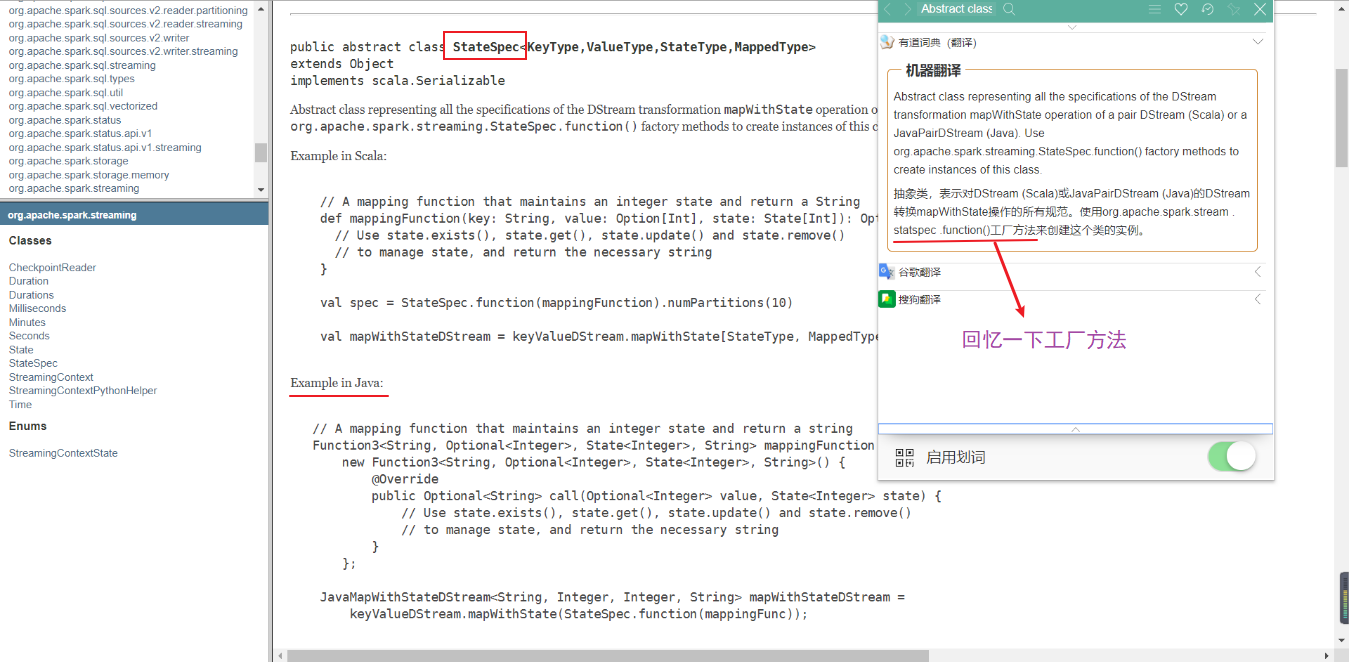
Function3是spark中的一个API。代码最上端导入了包含它的包import org.apache.spark.api.java.function.Function3,这里使用了lambda语法
word,one,state属于传入参数,在spark streaming官方文档中查找相应的方法,如stata.exists(),state.get(),state.update(),使用这些方法来构造业务逻辑。之后将此函数作为参数,根据官方文档中对StateSpet的描述,见下图
//更新累加功能(cumulative count)
Function3<String,Optional<Integer>,State<Integer>,Tuple2<String,Integer>>mappingFunc =
(word,one,state)->{
int sum = one.orElse(0)+(state.exists()?state.get():0);
Tuple2<String,Integer> output = new Tuple2<>(word,sum);
state.update(sum);
return output;
};
//Dstream由获取累积计数组成,该累积计数在每个批次中都会更新
JavaMapWithStateDStream<String ,Integer,Integer,Tuple2<String,Integer>> stateDstream =
wordsDstream.mapWithState(StateSpec.function(mappingFunc).initialState(initialRDD));
stateDstream.print();
jssc.start();
jssc.awaitTermination();
}
}
由于spark源码由scala编写,这里目前便没有下载源码,只对抽象接口、方法进行查阅文档了解。