之前我们获得单词嵌入矩阵主要通过两种方法:
- 基于共现矩阵,这种方法基于计数和矩阵分解,虽然有效的利用了全局信息,但是这种方法主要用来获取单词的相似性,而对于单词分析的任务表现不佳。
- 基于窗口机制的CBOW和skip-gram,这种机制能够利用局部信息,善于获得关于单词相似性中复杂的语言模式,但却不能利用全局信息
在此基础上我们引入Glove
共现矩阵
表示共现矩阵
表示单词
出现在单词
的上下文中的次数
表示出现在单词
表示单词
最小二乘目标函数
之前采用skip-gram模型时,我们使用softmax来计算单词出现在单词
的上下文中的概率
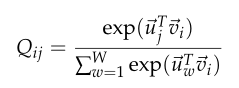
进而全局的交叉熵为
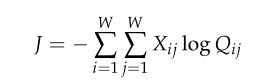
又因为计算时间开销太大,进而改写式子
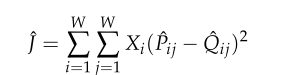
其中,
这个带来的问题是可能非常大,使得优化问题变得困难,于是我们对其使用对数
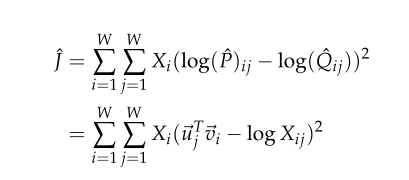
而并不能保证被优化,所以我们将其改成一个函数
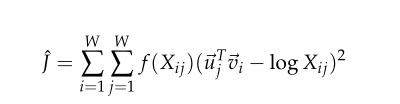
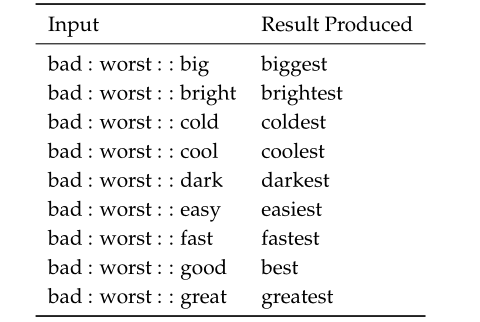
单词向量评价标准
主要通过单词的语义和句法,以及单词向量的余弦相似度比较 比如语义方面
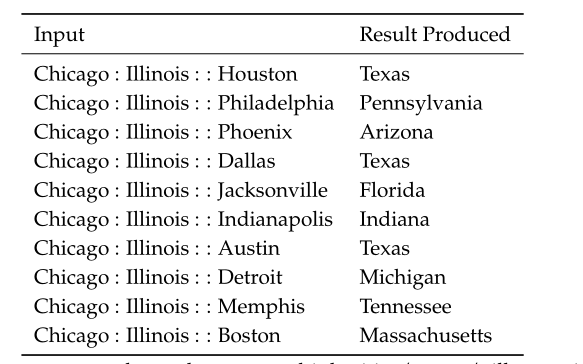
句法方面