

Redis专题-目录
- 基础梳理
- 常用数据类型及命令
- 持久化
- 内存管理
- 主从复制
- 哨兵高可用
- 集群分片
- 事务
- 底层数据结构
1. 基础梳理
- 类型:Database-NoSQL,非关系型数据库,开源,C语言实现,支持Key-Value形式的数据存储
- 特点:单线程,基于内存,性能强悍,可持久化
2. 常用数据类型及命令
-
String ( 基础元素,数字和字符串都行 )
命令 示例 介绍 SET SET starNum 1 设置starNum值为1 GET GET starNum 获取starNum的值 INCR INCR starNum starNum++ DECR DECR starNum starNum-- DEL DEL starNum 删除starNum记录 -
List ( 当成 双向链表 理解L和R比较方便 )
命令 示例 介绍 Lpush Lpush starList "First" "Second" {Left} starList.head->"Second"->"First" Rpush Rpush starList "First" "Second" {Right} starList.head->"First"->"Second" Lpop Lpop starList {Left} 从starList左侧开始移除元素并返回该元素 Rpop Rpop starList {Right}从starList左侧开始移除元素并返回该元素 Lrange Lrange starList 0 -1 查询starList所有元素 -
Set ( 去重、取并集)
命令 示例 介绍 Zadd Sadd starSet "Alice" "Bob" "Charlotte" 添加关注列表starSet中的元素 Zpop Spop starSet [count] 随机移除并返回starSet中count个元素 Smemebers Smemebers starSet 返回starSet中所有元素 Sinter Sinter starSet1 starSet2 starSet1 ∩ starSet2 取交集,共同关注 Sunion Sunion starSet1 starSet2 starSet1 U starSet2 取并集,兴趣推荐 -
Zset(sorted set)
命令 示例 介绍 Zadd Zadd "Vote|Rank" 1 "java" 2 "python" 排行、投票等情况进行新增或刷新操作 Zrange Zrange "Vote|Rank" 0 -1 范围查询:(1) "java" (2) "php" Zrange Zrange "Vote|Rank" 0 -1 WITHSCORES 带分值的查询:(1) "java" (2) "1" (3) "php" (4) "2" Zrem ZREM "Vote|Rank" "python" 删除操作 Zcard Zcard "Vote|Rank" 查询元素数量 -
Hash ( 当成Map来用 )
命令 示例 介绍 Hset Hset user1 info "Not VIP" 在K-V数据库里套K-V数据结构hhh Hget Hget user1 info 单次操作: "Not VIP", 后续操作: (nil) Hgetall ZREM user1 获取user1的所有K-V元素 -
GEO* ( 地理位置 )
-
Stream* ( 类似MQ )
3. 持久化
RDB
- 指定时间间隔,数据快照存储
- 客户端-手动:命令BGSAVE/SAVE创建内存快照(BGSAVE调用fork创建子进程将快照写入磁盘;SAVE直接占用主进程)
- 服务端-自动:修改配置文件redis.conf调整save配置
# 900秒之内至少发生一次写操作
save 900 1
# 300秒之内至少发生十次写操作
save 300 10
- 优缺点:
优点 缺点 性能较高 数据易丢失 数据恢复较快 数据集量大时对CPU要求高(单核进行多线程操作时会影响主线程性能)
AOF
- 记录“写”操作,重启时重新执行以恢复数据
- 开启:
appendonly yes - 策略调整:
appendonly always每当数据修改就写入appendonly everysec每秒同步一次<缺省策略>appendonly no不开启同步
- 优缺点:
优点 缺点 最安全 文件体积大 容灾 性能消耗比RDB高 易读,可修改 数据恢复比RDB慢
4. 内存管理
4.1 内存分配
- String:value最大512M
- List:元素数量最多2^32-1个
- Set:元素数量最多2^32-1个
- Hash:键值对数量最多2^32-1个
- 最大内存控制:
- 最大内存阈值100mb:
maxmemory 100mb - 到达阈值的执行策略:
maxmemory-policy allkeys-lru
- 最大内存阈值100mb:
- 内存压缩:大小超出压缩范围,溢出后Redis将自动将其转换为正常大小,配置例如:
- hash的字段最多512个:
hash-max-zipmap-entries 512 - hash的value最大64字节:
hash-max-zipmap-value 64 - list的字段最多512个:
list-max-ziplist-entries 512 - list的value最大64字节:
list-max-ziplist-value 64 - set的字段最多512个:
set-max-intset-entries 512 - zset的字段最多128个
zset-max-ziplist-entries 128 - zset的value最大64字节:
zset-max-ziplist-value 64
- hash的字段最多512个:
4.3 过期处理
- 主动处理:redis主动触发监测key是否过期,10次/秒
- 从具有相关过期的密钥集中测试20个随机密钥
- 删除找到的所有已过期密钥
- 如果超过25%的密钥已过期,从步骤1重新开始
- 被动处理:每次访问key时如果超时则清理
4.4 数据恢复
- RDB方式
- 过期的key不会持久化到文件中
- 载入时过期的key会通过redis主被动方式清理掉
- AOF方式
- 每次遇到过期key会追加一掉DEL命令到AOF文件
- 即顺序载入执行AOF命令文件就会进行删除过期的key
4.5 内存回收策略
- 配置文件修改:
maxmemory-policy allkeys-lru - 命令修改:
config set maxmemory-policy allkeys-lru
回收策略:
- noeviction: 当达到内存限制并且客户端尝试执行可能导致使用更多内存的命令时,将返回错误(大多数写入命令,但是DEL和一些其他例外)
- allkeys-lru: 所有key执行LRU算法回收
- volatile-lru: 已过期key里执行LRU算法回收
- allkeys-random: 所有key里随机回收
- volatile-random: 已过期key里随机回收
- volatile-ttl: 在已过期的key里回收存活时间较短的key
- allkeys-lfu:所有key执行LFU算法回收
- volatile-lfu:已过期key里执行LFU算法回收
回收算法:
- LRU:Least Recently Used 最近最少使用
- 最近被访问过,将来被访问的概率也高
- 非完整实现,因为内存限制
- 通过对少量keys进行取样(50%),然后回收其中一个最好的key
- 配置取样:
maxmemory-samples 5,10则接近全量
- LFU:Least Frequently Used 访问频率最低
- 历史访问次数多,将来访问概率也高
- 近似实现,每次对key进行访问时,用基于概率的对数计数器记录访问次数,同时计数器会随时间推移而减少
- 启用LFU后可使用热点数据分析功能
redis-cli --hotkeys
5. 主从复制
- 搭建:
- 命令行:
slaveof [ip] [port] - 修改redis.conf配置文件:
slaveof [ip] [port] slave-read-only yes - 退出主从集群:
slaveof no one
- 命令行:
- 复制流程:
- slave发送psync同步请求(同步源ID、同步进度offset)
- master收到请求,同步源为当前master则根据偏移量增量同步
- 同步源非当前master则进入全量同步:master生成RDB,传输到slave,加载到slave内存
- 核心知识
- 默认使用异步复制,slave和master之间异步地确认处理的数据量
- master-slave:1-N
- slave可接受其他slave的连接。slave可有下级sub-slave
- 主从同步过程在master侧是非阻塞的
- slave初次同步需删除旧数据,加载新数据,会阻塞到来的连接请求
- 应用场景
- 读写分离,规避单机瓶颈
- 故障切换,master宕机还可以用slave顶上
- 数据安全,slave服务器设置为只读
- 避免master持久化造成的开销(master关闭持久化,slave不定期保存或启用AOF)
- 注意事项:
- master重启后会以一个空数据集开始,此时slave进行同步则会清空slave的内容
- 读写分离场景异常:数据复制延时导致读到过期数据或者读不到数据(网络原因、slave阻塞),从节点故障(多client迁移)
- 全量复制常见原因:首次建立主从关系,runid不匹配,故障转移
- 复制风暴:master故障重启,slave结点较多时复制对服务器和网络性能会有较大影响,一台机器部署了多个master
6. 哨兵(Sentinel)高可用
-
核心概念
-
自动发现机制:配置文件保存master信息,sentinel通过
info replication进行自动发现 -
主观下线:单个哨兵自身主观认为redis实例不能继续提供服务,监测通过ping请求完成,
+PONG、-LOADING、-MASTERDOWN视为正常态,其他回复视为无效 -
客观下线:一定数量值的哨兵认为master已经下线,在某哨兵主观认为master下线后,通过
SENTINEL is-master-down-by-addr命令询问其他哨兵确认master是否下线,如果达成共识(达到quorum个数)则认为master结点客观下线,开始故障转移 -
哨兵间的通信
- 自动发现:哨兵通过"sentinel:hello"频道发布自己的消息和订阅其他哨兵的消息
- 命令通信:哨兵直接通过命令发送消息
- 订阅发布:哨兵直接互相订阅指定主题,发布消息
-
哨兵领导选举机制
基于Raft算法实现的选举机制,流程:
- 拉票:每个哨兵希望自己成为领导者
- 哨兵B节点收到A的拉票请求后,若未收到或同意过其他哨兵节点的请求,则同意A的请求
- 如果哨兵节点发现自己票数已过半,则它将成为领导者去执行故障转移
- 投票结束后,如果超过
failover-timeout的时间内,没进行实际故障转移操作,则重新拉票选举
-
slave选举机制
从服务器实例中,按顺序依次筛选:
- slave节点状态:非
S_DOWN,O_DOWN,DISCONNECTED - 优先级:
redis.conf中的配置项-slave-priority值越小,优先级越高 - 数据同步状态:
replication offset processed - 最小的
run id。run id比较方案:字典排序,ASCII码
- slave节点状态:非
-
主从切换
- 把即将成为master的slave节点撤出主从集群
- 自动执行:
slaveof NO ONE - 使其他slave节点成为新master的从属
- 自动执行:
slaveof new_master_host new_master_port
-
7. 集群分片
- 集群分片技术演进由来:
- 例如用户量三千万,存储信息到redis中预期内存需10G,如何设计redis缓存架构?
- 三千万用户,访问量大,达到单台redis读写瓶颈
- 单redis实例管理10G内存,处理效率低
- 10G内存要求可能在单台机器中难以达到
- 官方方案:redis cluster
- 非官方方案:豌豆荚-Codis,推特-TwemProxy
- 集群关心的问题:
- 数据倾斜&访问倾斜
- ……
8. 事务
可以通过MULTI和EXEC完成类似事务的效果,因为并不能保证这些命令的原子性,中间的命令出现故障不能回滚,故Redis实现的是更像是“命令的批量处理”效果
9. 底层数据结构
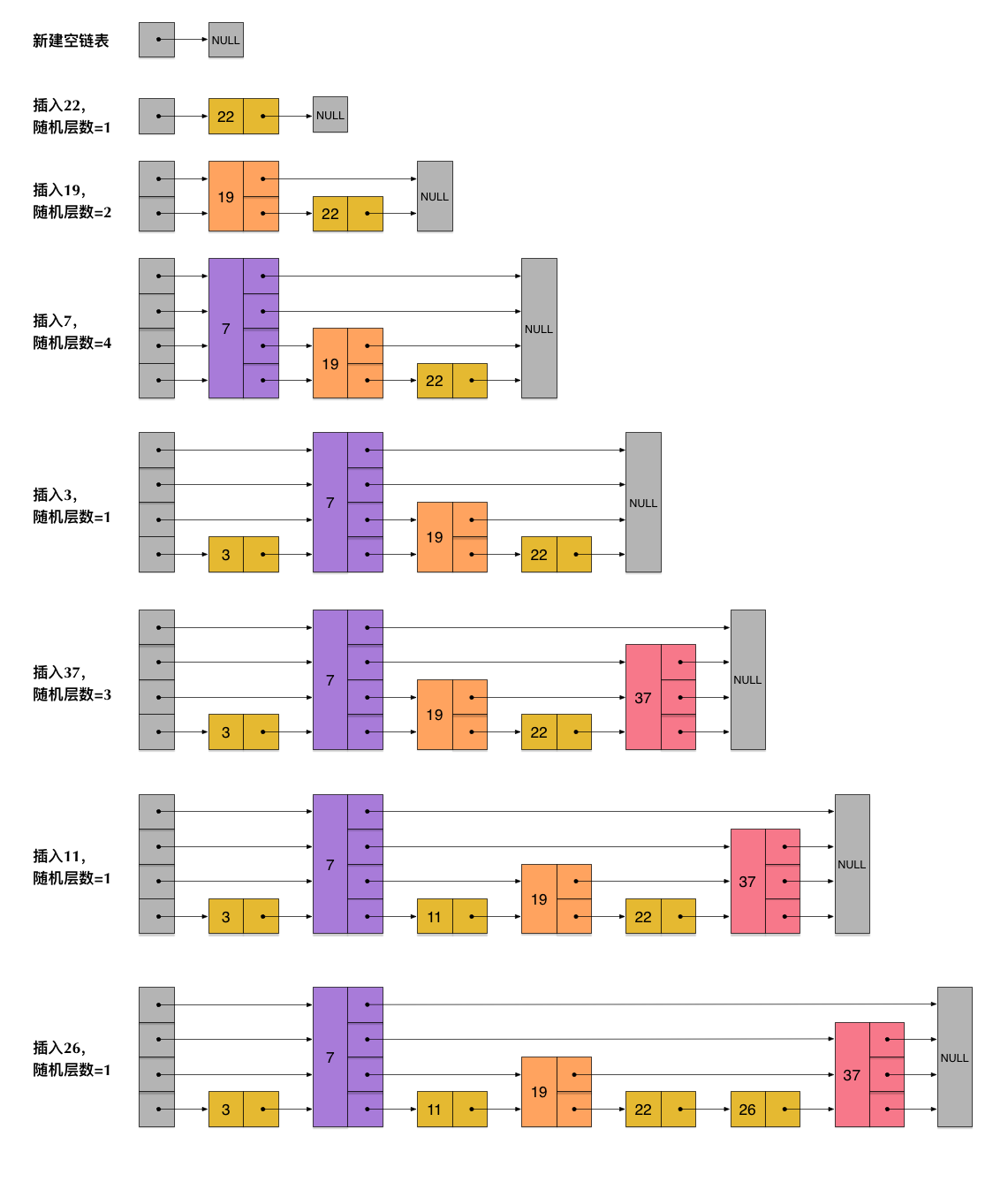
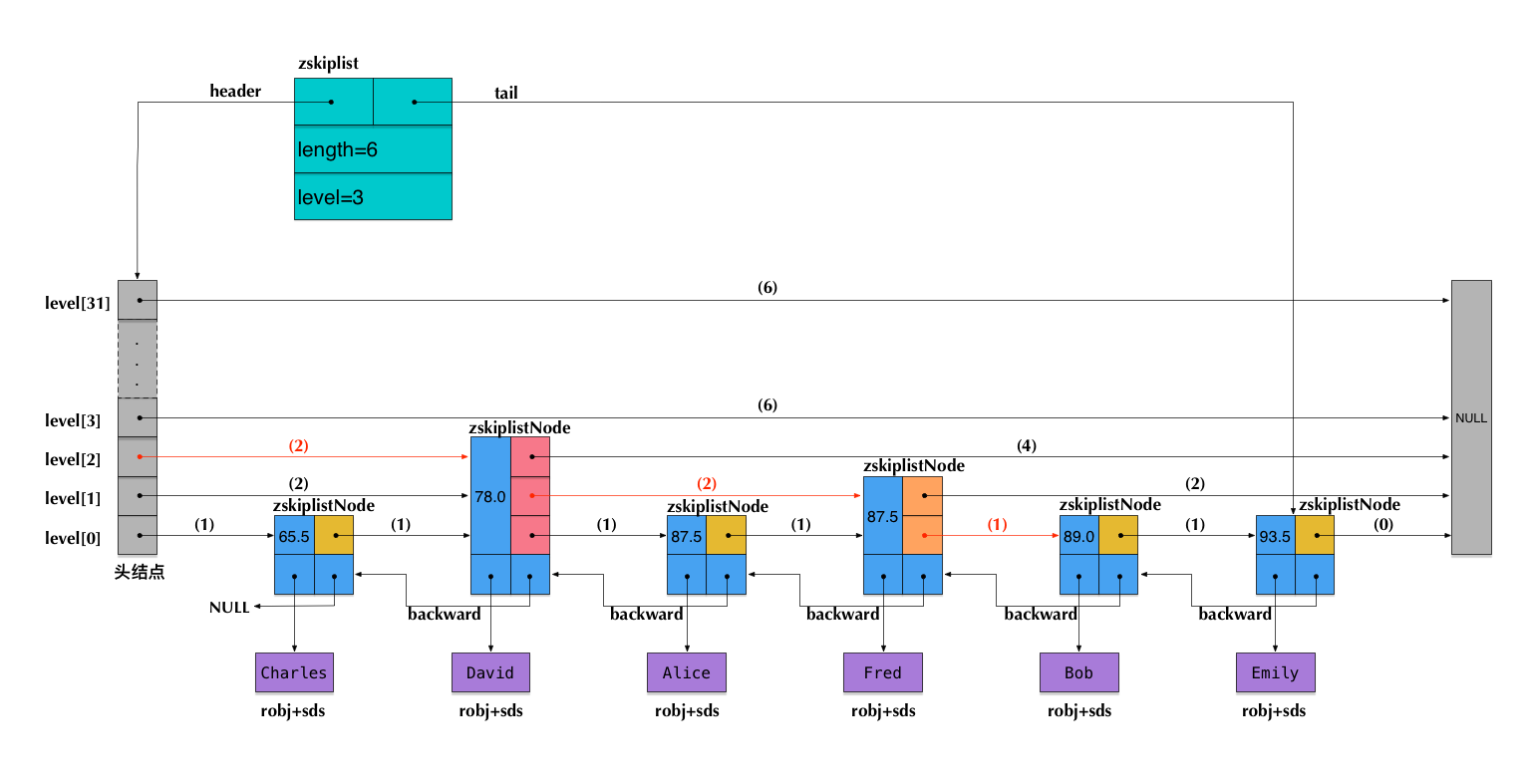
9.1 跳跃表 SkipList
- 有序集合ZSET( Sorted Set )的底层数据结构之一
- SkipList由多指针链表实现
- 问题引入:为何使用SkipList?
- 已知有序数据集{1, 3, 12, 23, 50, 79}需要完成存储分数score
- 最简单实现-有序链表:[(Head)]->[1| ]->[3| ]->[12| ]->[23| ]->[50| ]->[79| ]->[(Tail)NULL]
- 在链表中查询元素20需要逐个比较直到23>20即停止,需要完成一次遍历来查询数据,查询次数N+1
- 查询复杂度O(N)
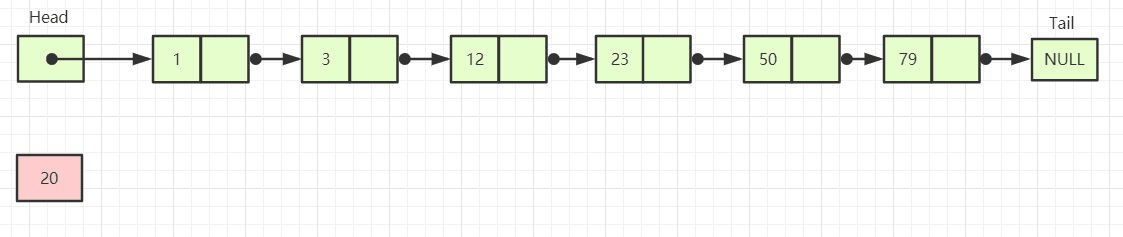
- 优化:添加索引链表中间跳过一些值进行遍历,遇到大于目标值的则通过指针返回前一表项来搜索中间值,查询次数N/2+1
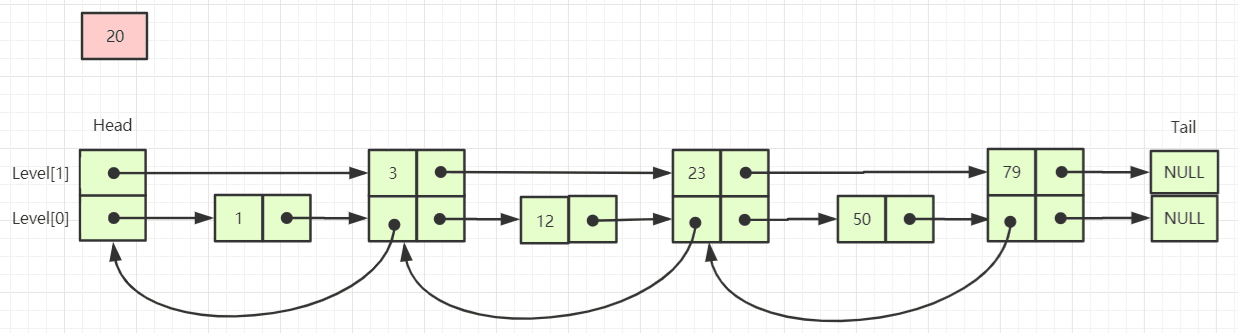
- 依照这个思路继续优化到多个Level,参考图(来自http://zhangtielei.com):
- Redis中做的优化
- 在ZSET中存储的key实际为score,允许重复;经典SkipList不允许key值重复
- 需要进行比较的有score和数据本身,有多score重复的时候还需要根据内容做字典排序
- Level[0]的链表为双向链表,方便倒序获取数据
- 参考图(来自http://zhangtielei.com):
9.2 字典 Dict
Redis5.0源码走起:github.com/antirez/red…
dict主体的定义:typedef struct dict { dictType *type; void *privdata; dictht ht[2]; long rehashidx; /* rehashing not in progress if rehashidx == -1 */ unsigned long iterators; /* number of iterators currently running */ } dict;- 继续挖结构看看上面出现的
dictht是什么玩意儿/* This is our hash table structure. Every dictionary has two of this as we * implement incremental rehashing, for the old to the new table. */ typedef struct dictht { dictEntry **table; unsigned long size; unsigned long sizemask; unsigned long used; } dictht; - 又发现了
dictEntry,仿佛已经看到了HashMap的Entry键值对结构,这不就是个桶(bucket)么typedef struct dictEntry { void *key; union { void *val; uint64_t u64; int64_t s64; double d; } v; struct dictEntry *next; } dictEntry; - 至此为止,字典的大致结构已经清楚了:一个字典
dict存有两个哈希表dictht当桶,每个桶下面跟上dictEntry链表存储数据
- 核心操作
- rehash:为了应对HashMap中键值冲突过多导致的bucket下接的链表过长问题,字典需要对过长的哈希表进行ReHash操作
- 判断条件:
static int dict_can_resize = 1; //可以进行 static unsigned int dict_force_resize_ratio = 5; // 强制进行- 引入方法:dictAdd->dictAddRaw->_dictRehashStep->dictRehash,在进行add操作时判断是否达到rehash条件,达到条件则进行rehash步骤
- int dictRehash(dict *d, int n) --源码
int dictRehash(dict *d, int n) { int empty_visits = n*10; /* Max number of empty buckets to visit. */ if (!dictIsRehashing(d)) return 0; // 这里判断了是否需要进行rehash和resize while(n-- && d->ht[0].used != 0) { dictEntry *de, *nextde; /* Note that rehashidx can't overflow as we are sure there are more * elements because ht[0].used != 0 */ assert(d->ht[0].size > (unsigned long)d->rehashidx); while(d->ht[0].table[d->rehashidx] == NULL) { d->rehashidx++; if (--empty_visits == 0) return 1; } de = d->ht[0].table[d->rehashidx]; /* Move all the keys in this bucket from the old to the new hash HT */ while(de) { uint64_t h; nextde = de->next; /* Get the index in the new hash table */ h = dictHashKey(d, de->key) & d->ht[1].sizemask; de->next = d->ht[1].table[h]; d->ht[1].table[h] = de; d->ht[0].used--; d->ht[1].used++; de = nextde; } d->ht[0].table[d->rehashidx] = NULL; d->rehashidx++; } /* Check if we already rehashed the whole table... */ if (d->ht[0].used == 0) { zfree(d->ht[0].table); d->ht[0] = d->ht[1]; _dictReset(&d->ht[1]); d->rehashidx = -1; return 0; } /* More to rehash... */ return 1; }
参考资料
Redis官网:redis.io
中间件专题-缓存中间件-Redis:网易云课堂-微专业-Java高级开发工程师
GitHub-CyC2018:Redis笔记
SkipList:Redis内部数据结构详解
Dictht:redisbook.readthedocs.io/en/latest/i…
推荐书目:《Redis设计与实现》第二版
