

分布式协调框架
Zookeeper是一个典型的分布式数据一致性解决方案,分布式程序可以基于Zookeeper实现诸如数据发布/订阅、负载均衡、命名服务、分布式协调通知、集群管理、Master选举、分布式锁和分布式队列等功能。
数据结构
zookeeper的数据结构为层次化的目录结构,类似于文件系统
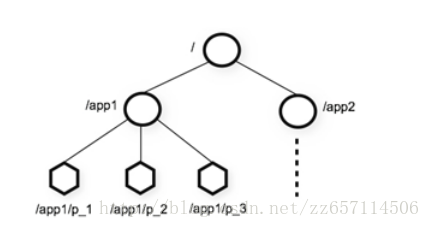
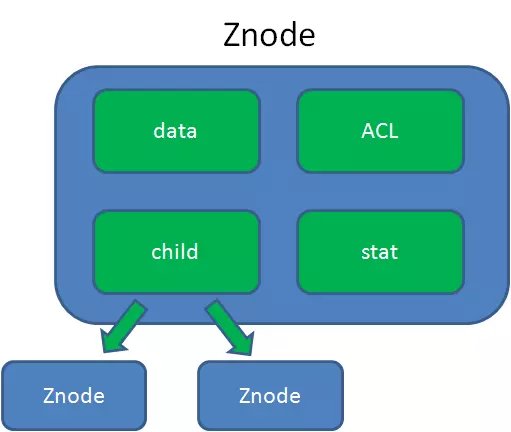
ACL:记录Znode的访问权限,即哪些人或哪些IP可以访问本节点。
stat:包含Znode的各种元数据,比如事务ID、版本号、时间戳、大小等等。
child:当前节点的子节点引用
Zookeeper的数据在内存和磁盘中各存一份
节点类型
持久节点(PERSISTENT):节点创建就会一直存在,除非执行删除请求
持久顺序节点(PERSISTENT_SEQUENTIAL):父节点维护主节点的顺序,给节点自动加上数字后缀。
临时节点(EPHEMERAL):客户端会话失效,节点会被删除
临时顺序节点(EPHEMERAL_SEQUENTIAL):有顺序的节点,客户端会话失效,节点会被删除
临时节点不允许创建子节点。
基本操作
create创建节点;delete删除节点;exists判断节点是否存在;getData获取一个节点的数据;setData设置一个节点的数据;getChildren获取一个节点下的所有子节点
客户端在请求读操作时可以选择是否设置Watch:当znode发生改变时,异步通知设置了watch的客户端
zookeeper集群
一主多从的结构,更新数据时首先更新到主节点再更新到从节点,读取数据可以从任意节点读取
zookeeper具有CP 强一致性和分区容错,Zookeeper在节点选举的时候会处于不可用状态。
写数据:一个客户端进行写数据请求时,如果时从节点接收到写请求,把请求转发给Leader主节点,主节点进行广播,一半以上节点写入成功,进行commit广播,一半以上提交成功,通知接收请求的节点返回给客户端。
读数据:各个节点的数据保持强一致性,所以读的时候可以在任意一台Zookeeper节点上。
主节点选举:
选举阶段,集群处于Looking状态,它们各自向其他节点发起投票,第一次投票各个节点都会投给自己(节点id和最新事务Id ZXID),各节点根据接收的投票请求比较,优先比较事务ID取最新的事务id,若事务id相同,比较节点id,取节点id更大的投票出去,当一个节点收到了半数以上的投票成为leader。
CAP
C:强一致性,在任何时刻客户端读取的都是最新的数据。
A:可用性,集群中部分节点挂掉后是否还能响应客户端的请求
P:分区容错性:分布式系统中至少要满足C或者P
应用场景
注册中心:利用Znode和Watcher实现注册与发现,注册相当于创建一个Znode,通过watcher将变化及时的推送给注册者。
分布式锁:
(控制时序)临时顺序节点(每次创建基于上一个的值+1),竞争锁时,相当于各个竞争者去zk下创建临时顺序节点,位于第一个的节点得到锁,其他竞争者监听第一个临时节点,当临时节点删除后再确认当前的第一个临时节点以此类推。
(独占锁)多个竞争者同时去创建一个znode,创建成功的获取到锁。
Master选举;利用临时顺序节点
集群管理:没新增一个节点,在zk下创建一个znode
负载均衡:zk中通过创建znode维护全部处于正常的服务节点列表,负载均衡器通过watch机制监听各服务节点的变化,检测到某节点宕掉后,删除对应的znode,负载均衡器就可以得到通知
命名服务:根据ZK的顺序节点的特性,来创建全局唯一的名称。
分布式协调通知:根据znode
疑问:
写入数据时,若有部分节点写入失败会怎么处理,若客户端请求了写入失败的节点如何保证一致性
ZK Watch实现原理
