

其实分析的步骤都是类似的,无外乎是先分析网站信息,页面组成,然后编写代码爬取数据,最后再保存数据。
页面分析
我们选取一个岗位来分析,比如:Python。
在 Boss 直聘的官网上搜索 Python,可以看到浏览器的 URL 变为如下:
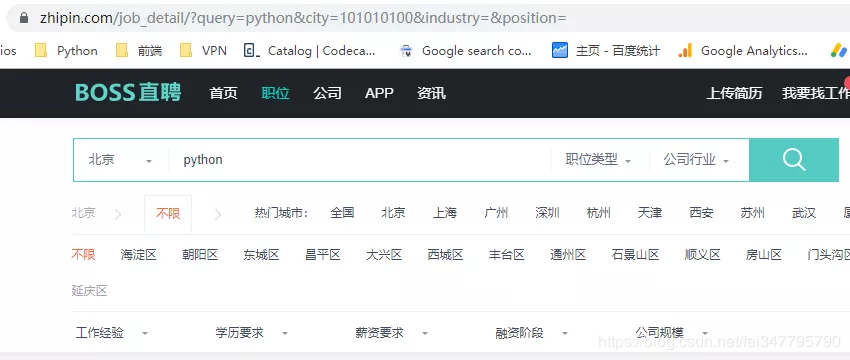 把该地址复制到 Postman 尝试访问,发现无法得到正确的返回:
把该地址复制到 Postman 尝试访问,发现无法得到正确的返回:
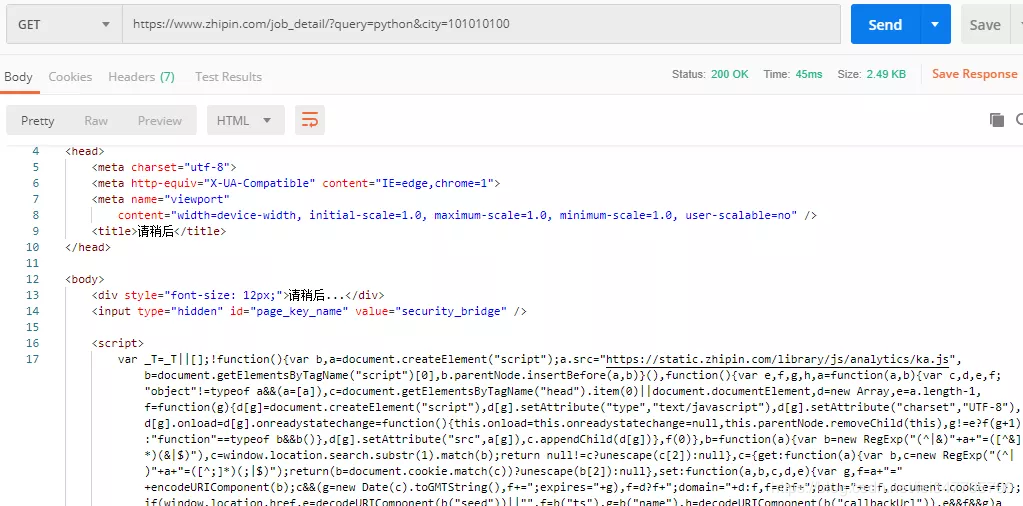 此时,再次回到浏览器,查看该请求下面的 headers,可以看到其中有一个 cookie,是很长的一串字符串,我们拷贝这个 cookie 到 Postman 中,再次请求:
此时,再次回到浏览器,查看该请求下面的 headers,可以看到其中有一个 cookie,是很长的一串字符串,我们拷贝这个 cookie 到 Postman 中,再次请求: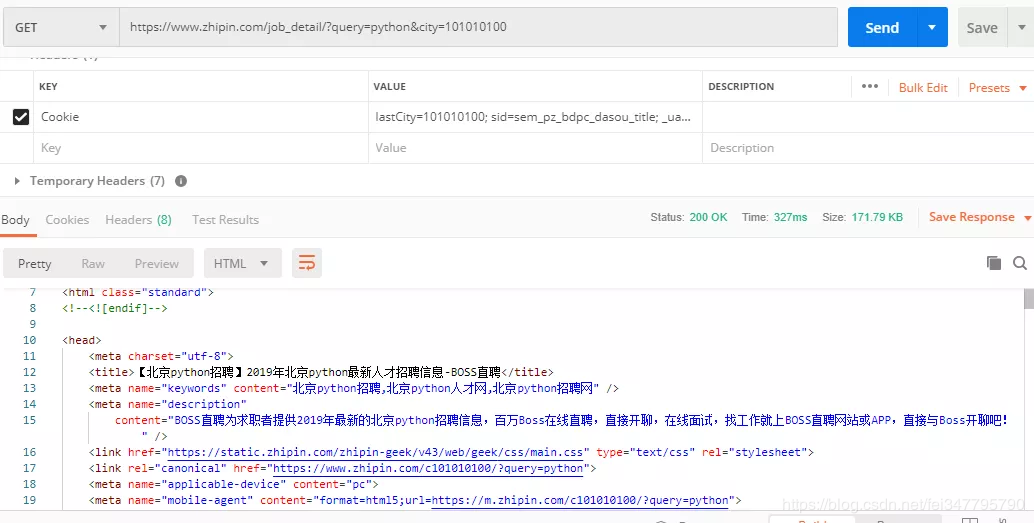 成功了,看来 Boss 直聘网也只是做了简单的 cookies 验证。
成功了,看来 Boss 直聘网也只是做了简单的 cookies 验证。
BeautifulSoup 使用
下面就是解析 HTML 数据了,我比较习惯用 BeautifulSoup 这个库来解析。
from bs4 import BeautifulSoup
import requests
'''
更多Python学习资料以及源码教程资料,可以在群821460695 免费获取
'''
url = 'https://www.zhipin.com/job_detail/?query=python&city=101010100'
res = requests.get(url, headers=header).text
print(res)
content = BeautifulSoup(res, "html.parser")
ul = content.find_all('ul')
print(ul[12])可以使用 BeautifulSoup 的 find 函数来查找 HTML 的元素标签,个人觉得还是挺方便的。
编写代码
我们通过分析 HTML 网页可以知道,所有的工作信息都是保存在 ul 这个标签中的,我们可以通过上面的代码拿到页面中所有的 ul 标签,find_all 返回的是一个列表,然后再查看,工作具体位于第几个 ul 中,这样就拿到具体的工作信息了。
确定需要抓取的数据
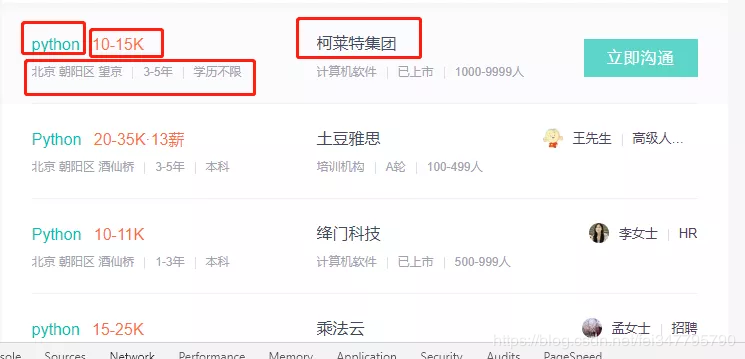 如图中所示,我们需要抓取红框中的信息,主要分为四部分。
如图中所示,我们需要抓取红框中的信息,主要分为四部分。
Python:可以得到该 job 具体页面地址
10-15K:每个 job 的薪资
柯莱特集团:招聘公司名称
北京 朝阳区 望京|3-5年|学历不限:该 job 的详情信息
对于前三个信息,还是比较好抓取的。
job_details_uri = job.find('h3', attrs={'class': 'name'}).find('a')['href']
job_company = job.find('div', attrs={'class': 'company-text'}).find('h3', attrs={'class': 'name'}).find('a').text
job_salary = job.find('h3', attrs={'class': 'name'}).find('span', attrs={'class': 'red'}).text对于 job 的详情信息,需要用到正则表达式来分割字符串,我们先来看下该部分的原始形式:
 又可以把该部分切分成三块,site、year 和 edu。可以使用正则的 group 特性,帮助我们完成切分,最后我写的正则如下:
又可以把该部分切分成三块,site、year 和 edu。可以使用正则的 group 特性,帮助我们完成切分,最后我写的正则如下:
rege = r'<p>([\u4e00-\u9fa5 ]+)<em class="vline"></em>([\d+-年]+|[\u4e00-\u9fa5]+)<em class="vline"></em>([\u4e00-\u9fa5]+)'正则表达式的具体写法这里就不说了,不熟悉的可以自行查找下。
下面把这部分代码整合到一起:
for job in jobs:
job_dict = {}
job_details_uri = job.find('h3', attrs={'class': 'name'}).find('a')['href']
job_company = job.find('div', attrs={'class': 'company-text'}).find('h3', attrs={'class': 'name'}).find('a').text
job_salary = job.find('h3', attrs={'class': 'name'}).find('span', attrs={'class': 'red'}).text
job_details = str(job.find('p'))
print(job_details)
job_rege = re.match(rege, job_details)
job_dict['name'] = job_company
job_dict['uri'] = job_details_uri
job_dict['salary'] = job_salary
job_dict['site'] = job_rege.group(1)
job_dict['year'] = job_rege.group(2)
job_dict['edu'] = job_rege.group(3)
job_list.append(job_dict)
print(job_list)由于我们最后还是得到了一个列表,里面包含字典,同样可以快捷的保存到 MongoDB 中。
抓取多个页面
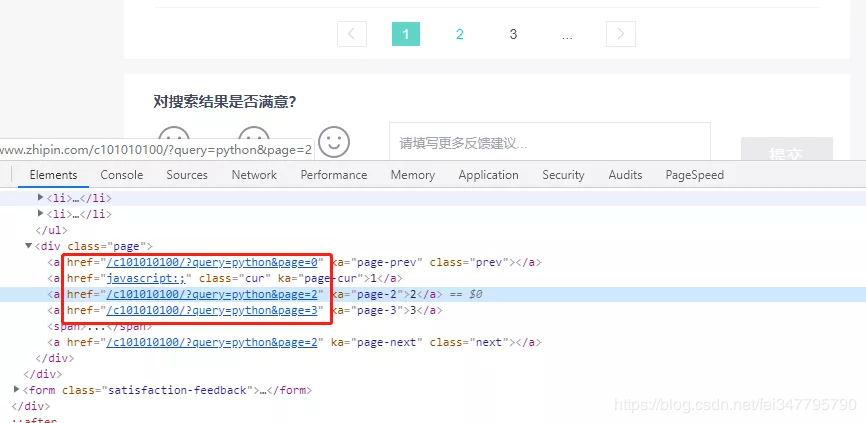
通过查看 Boss 网站的下一页源码可得到翻页 URL 的规律:
https://www.zhipin.com/c101010100/?query=python&page=c101010100:是城市代码,在我们这里就代表北京
query:也很明显,就是我们的搜索关键字
page:页数
 于是我们最后整合代码如下:
于是我们最后整合代码如下:
def jobs(page):
for i in range(1, page + 1):
job_list = []
try:
print("正在抓取第 %s 页数据" % i)
uri = '/c101010100/?query=python&page=%s' % i
res = requests.get(config.url + uri, headers=header).text
content = BeautifulSoup(res, "html.parser")
ul = content.find_all('ul')
jobs = ul[12].find_all("li")
...
print(job_list)
# save to mongoDB
try:
mongo_collection.insert_many(job_list)
except:
continue
time.sleep(1)
except:
continue因为我上面的正在表达式并不能匹配所有的情况,所以使用 try...except 来忽略了其他不规则的情况。
岗位详情抓取
job 详情抓取完毕之后,开始抓取岗位详情,就是每个 job 的具体要求,毕竟知己知彼,百战不殆。
我们可以从 URI 中获得每个工作的详情页面地址,然后再拼接到 Boss 的主 URL 上:
www.zhipin.com/job_detail/…
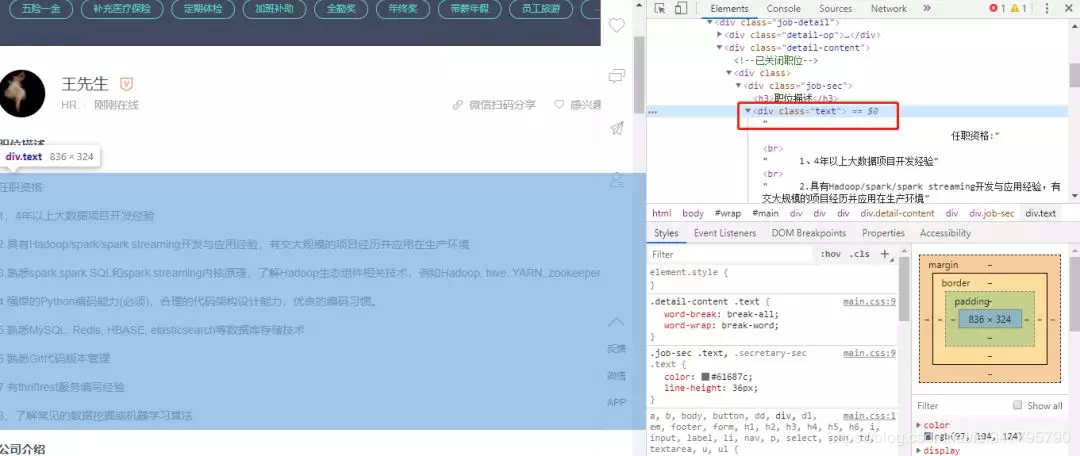
再来看下工作详情页面,所有的任职描述都在如下的 div 标签中:
 没有什么特殊的,直接用 BeautifulSoup 解析即可。
没有什么特殊的,直接用 BeautifulSoup 解析即可。
job_conn = MongoClient("mongodb://%s:%s@ds151612.mlab.com:51612/boss" % ('boss', 'boss123'))
job_db = job_conn.boss
job_collection = job_db.boss
details_collection = job_db.job_details
def run_main():
jobs = job_collection.find()
for job in jobs:
print('获得工作的uri ', job['uri'])
get_details(job)
time.sleep(1)
def get_details(items):
base_url = config.url
url = base_url + items['uri']
company_name = items['name']
try:
res = requests.get(url, headers=header).text
content = BeautifulSoup(res, "html.parser")
text = content.find('div', attrs={'class': 'text'}).text.strip()
result = {'name': company_name, 'details': text}
details_collection.insert_one(result)
except:
raise
if __name__ == '__main__':
run_main()注意下这里的 MongoDB 配置,是同一个 db 下的不同 collection。这样,也就完成了直聘网站相关岗位的数据爬取。
爬取的数据 MongoDB 链接:
job_conn = MongoClient("mongodb://%s:%s@ds151612.mlab.com:51612/boss" % ('boss', 'boss123'))
job_db = job_conn.boss
job_collection = job_db.boss
details_collection = job_db.job_details完整代码
import requests
from bs4 import BeautifulSoup
import config
import re
from pymongo import MongoClient
import time
'''
更多Python学习资料以及源码教程资料,可以在群821460695 免费获取
'''
header = config.header
rege = r'<p>([\u4e00-\u9fa5 ]+)<em class="vline"></em>([\d+-年]+|[\u4e00-\u9fa5]+)<em class="vline"></em>([\u4e00-\u9fa5]+)'
conn = MongoClient("mongodb://%s:%s@ds151612.mlab.com:51612/boss" % ('boss', 'boss123'))
db = conn.boss
mongo_collection = db.boss
def jobs(page):
for i in range(1, page + 1):
job_list = []
try:
print("正在抓取第 %s 页数据" % i)
uri = '/c101010100/?query=python&page=%s' % i
res = requests.get(config.url + uri, headers=header).text
content = BeautifulSoup(res, "html.parser")
ul = content.find_all('ul')
jobs = ul[12].find_all("li")
for job in jobs:
job_dict = {}
job_details_uri = job.find('h3', attrs={'class': 'name'}).find('a')['href']
job_company = job.find('div', attrs={'class': 'company-text'}).find('h3', attrs={'class': 'name'}).find(
'a').text
job_salary = job.find('h3', attrs={'class': 'name'}).find('span', attrs={'class': 'red'}).text
job_details = str(job.find('p'))
job_rege = re.match(rege, job_details)
job_dict['name'] = job_company
job_dict['uri'] = job_details_uri
job_dict['salary'] = job_salary
try:
job_dict['site'] = job_rege.group(1)
job_dict['year'] = job_rege.group(2)
job_dict['edu'] = job_rege.group(3)
except:
continue
job_list.append(job_dict)
print(job_list)
# save to mongoDB
try:
mongo_collection.insert_many(job_list)
except:
continue
time.sleep(1)
except:
continue
if __name__ == '__main__':
jobs(10)
