

哈希表:通过key-value而直接进行访问的数据结构,不用经过关键值间的比较,从而省去了大量处理时间。
哈希函数:选择的最主要考虑因素——尽可能避免冲突的出现
构造哈希函数的原则是:
①函数本身便于计算;
②计算出来的地址分布均匀,即对任一关键字k,f(k) 对应不同地址的概率相等,目的是尽可能减少冲突。
1.直接定址法:
如果我们现在要对0-100岁的人口数字统计表,那么我们对年龄这个关键字就可以直接用年龄的数字作为地址。此时f(key) = key。
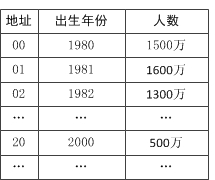
这个时候,我们可以得出这么个哈希函数:f(0) = 0,f(1) = 1,……,f(20) = 20。这个是根据我们自己设定的直接定址来的。人数我们可以不管,我们关心的是如何通过关键字找到地址。 如果我们现在要统计的是80后出生年份的人口数,那么我们对出生年份这个关键字可以用年份减去1980来作为地址。此时f (key) = key-1980。
假如今年是2000年,那么1980年出生的人就是20岁了,此时 f(2000) = 2000 - 1980,可以找得到地址20,地址20里保存了数据“人数500万”。 也就是说,我们可以取关键字的某个线性函数值为散列地址,即:
f(key) = a × key + b
这样的散列函数优点就是简单、均匀,也不会产生冲突,但问题是这需要事先知道关键字的分布情况,适合査找表较小且连续的情况。由于这样的限制,在现实应用中,直接定址法虽然简单,但却并不常用。
2.数字分析法:
分析一组数据,比如一组员工的出生年月日,这时我们发现出生年月日的前几位数字大体相同,这样的话,出现冲突的几率就会很大,但是我们发现年月日的后几位表示月份和具体日期的数字差别很大,如果用后面的数字来构成散列地址,则冲突的几率会明显降低。因此数字分析法就是找出数字的规律,尽可能利用这些数据来构造冲突几率较低的散列地址。
3.折叠法:
将关键字分割成位数相同的几部分,最后一部分位数可以不同,然后取这几部分的叠加和(去除进位)作为散列地址。
4.除留余数法:
(常用:取关键字被某个不大于散列表表长m的数p除后所得的余数为散列地址。即 H(key) = key MOD p, p<=m。不仅可以对关键字直接取模,也可在折叠、平方取中等运算之后取模。对p的选择很重要,一般取素数或m,若p选的不好,容易产生同义词。
5. 平方取中法
当无法确定关键字中哪几位分布较均匀时,可以先求出关键字的平方值,然后按需要取平方值的中间几位作为哈希地址。这是因为:平方后中间几位和关键字中每一位都相关,故不同关键字会以较高的概率产生不同的哈希地址。
6. 伪随机数法:
采用一个伪随机函数做哈希函数,即h(key)=random(key)。
解决冲突方法
1.开放定址法:
当发生地址冲突时,按照某种方法继续探测哈希表中的其他存储单元,直到找到空位置为止。这个过程可用下式描述:
H i ( key ) = ( H ( key )+ d i ) mod m ( i = 1,2,…… , k ( k ≤ m – 1))
其中: H ( key ) 为关键字 key 的直接哈希地址, m 为哈希表的长度, di 为每次再探测时的地址增量。
采用这种方法时,首先计算出元素的直接哈希地址 H ( key ) ,如果该存储单元已被其他元素占用,则继续查看地址为 H ( key ) + d 2 的存储单元,如此重复直至找到某个存储单元为空时,将关键字为 key 的数据元素存放到该单元。
增量 d 可以有不同的取法,并根据其取法有不同的称呼:
( 1 ) d i = 1 , 2 , 3 , …… 线性探测再散列;
( 2 ) d i = 1^2 ,- 1^2 , 2^2 ,- 2^2 , k^2, -k^2…… 二次探测再散列;
( 3 ) d i = 伪随机序列 伪随机再散列;
2.链地址法:
链地址法解决冲突的做法是:如果哈希表空间为 0 ~ m - 1 ,设置一个由 m 个指针分量组成的一维数组 ST[ m ], 凡哈希地址为 i 的数据元素都插入到头指针为 ST[ i ] 的链表中。这种方法有点近似于邻接表的基本思想,且这种方法适合于冲突比较严重的情况。
3.公共溢出区法:
将哈希表分为基本表和溢出表两部分,凡是和基本表发生冲突的元素,一律填入溢出表
C语言实现
- 定义一些宏与结构体
#define HashMaxSize 1000 //哈希表最大容量
#define LoadFactor 0.8 //负载因子,表示哈希表的负载能力
typedef int KeyType;
typedef int ValueType;
typedef size_t(*HashFunc)(KeyType key)//定义HashFunc是一个指向函数的指定,它可以指向函数类型有size_t且有一个int参数的函数;重定义哈希函数
typedef enum Stat{ //表示每个元素的状态
Empty, //空,当前没有值
Valid, //当前的值有效
Invalid //非空但无效,表示当前节点被删除
}Stat;
typedef struct HashElem //哈希表的元素结构体
{
/* data */
KeyType key;
ValueType value;
Stat stat;
}HashElem;
typedef struct HashTable //哈希表
{
HashElem data[HashMaxSize];
size_t size; //当前有效的元素个数
HashFunc hashfunc;
}HashTable;
- 函数声明
void HashTableInit(HashTable *ht,HashFunc hashfunc);
//初始化哈希表
int HashTableInsert(HashTable *ht,KeyType key,ValueType value);
int HashTableFind(HashTable *ht,KeyType key,ValueType *value,size_t *cur);
//哈希表的查找,找到返回1,并返回这个节点的value值,未找到返回0
void HashRemove(HashTable *ht,KeyType key);
//删除值为key的结点
int HashEmpty(HashTable *ht);
//判断哈希表是否为空
size_t HashSize(HashTable *ht);
//求哈希表的大小
void HashTableDestroy(HashTable *ht);
//销毁哈希表
- 函数实现
size_t HashFuncDefault(KeyType key){
return key%HashMaxSize;//检查是否超出最大储存量
}
void HashTableInit(HashTable *ht){
if (ht == NULL) //非法输入
return;
ht->size = 0;
ht->hashfunc = HashFuncDefault;//错误赋值
for (size_t i =0;i<HashMaxSize;i++){
ht->data[i].key = 0;
ht->dota[i].stat = Empty;
ht->data[i].value = 0;
}
}
int HashTableInsert(HashTable *ht,KeyType key,ValueType value){
if (ht == NULL)
return 0;
if (ht->size >= HashMaxSize*LoadFactor) //当哈希表的size超出了负载
return 0;
size_t cur = ht->hashfunc(key); //根据哈希函数将key转换,求得key在哈希表中的下标
while(1){//判断当前下标是否被占用
if (ht->data[cur].key ==key) //保证不会用重复的数字存入哈希表
return 0;
if(ht->data[cur].stat != Valid){
ht->data[cur].key =key;
ht->data[cur].value = value;
ht->data[cur].stat = Valid;
ht->size++;
return 1;
}
cur++;
}
}
int HashTableFind(HashTable *ht,KeyType key,ValueType *value){//哈希表的查找,找到返回1,没找到返回0
if(ht == NULL)
return 0;
size_t offset=ht->hashfunc(key);//通过哈希函数找到key的下标
if(ht->data[offset].key == key && ht->data[offset].stat == Valid){//若当前下标所对应的值正好是key并且当前的状态必须为valid才返回
*value = ht->data[offset].value;
return 1;
} else{//值不为key,根据冲突解决方法查找(当前解决方法为逐个往后查),直到找到stat等于empty
while (ht->data[offset].stat !=Empty){
if(ht->data[offset].key !=key){
offset++;
if(offset >= HashMaxSize//判断下标是否超出最大值)
offset = 0;
} else{
if(ht->data[offset].stat == Valid){
*value =ht->data[offset].value;
return 1;
} else
offset++;
}
}
return 0;
}
}
int HashTableFindCur(HashTable *ht,KeyType key,size_t *cur){//删除节点
if(ht == NULL)
return 0;
for(size_t i = 0;i < HashMaxSize;i++){
if(ht->data[i].key == key && ht->data[i].stat == Valid){
*cur = i;//?
return 1;
}
}
return 0;
}
void HashRemove(HashTable *ht,KeyType key){
if (ht == NULL) //非法输入
return;
ValueType value = 0;
size_t cur =0;
int ret = HashTableFindCur(ht,key,&cur);//通过find函数得到key是否存在哈希表中
if(ret == 0)
return;
else{
ht->data[cur].stat = Invalid;
ht->size--;
}
}
int HashEmpty(HashTable *ht){
if(ht == NULL)
return 0;
else
return ht->size >0?1:0
}
size_t HashSize(HashTable *ht){//求哈希表大小
if(ht == NULL) {
ht->data->stat = Empty;
return ht->size;
} else
{
return ht->size;
}
}
void HashPrint(HashTable *ht, const char *msg){
if(ht ==NULL || ht->size = 0)
return;
printf("%s/n",msg);
for(size_t i =0;i< HashMaxSize;i++){
if(ht->data[i],stat != Empty)
printf("[%d] key=%d value=%d stat =%d\n",i,ht->data[i].key,ht->data[i].value,ht->data[i].stat);
}
}
参考博客:
blog.csdn.net/wangpengqi/…
blog.csdn.net/mark555/art…
www.cnblogs.com/youngerchin…
blog.csdn.net/weixin_4033…
blog.csdn.net/u011109881/…
