

一、Node简介
1、Node定义:
Node.js 是一个基于 Chrome V8 引擎的 JavaScript 运行环境。 Node.js 使用了一个事件驱动、非阻塞式 I/O 的模型,使其轻量又高效。
先了解什么时阻塞?
- 阻塞:I/O时,进程休眠等待I/O完成后进行下一步。
- 非阻塞:I/O时,函数立即返回,进程不等待I/O完成。
注意:此为异步操作,当即收不到返回值,需借助回调函数接收数据!!
总结:node使用的非阻塞式I/O,又因为时基于JavaScript的事件驱动,当进程进程操作结束时,可以通知主进程。
2、为什么使用Node
(1)、 我们先说几个概念:
- CPU密集和aI/O密集
- CPU密集:压缩、解压、加密、解密
- I/O密集:文件操作、网络操作(
HTTP)、数据库
- web常见场景
- 静态资源读取(js、css)
- 数据库操作(数据库存储在物理磁盘上)
- 渲染页面
- 处理高并发的常用方案
- 增加机器数
- 增加每台机器的CPU数(多核)
- 进程
进程:是计算机中的程序关于某数据集合上的一次运行活动,是系统进行资源分配和调度的基本单位。
多进程:启动多个进程,多个进程可以一块执行多个任务
- 线程
- 线程:进程内一个相对独立的、可调度的执行单元,与同属一个进程的线程共享进程的资源
- 多线程:启动一个进程,在一个进程内启动多个线程,这样,多个线程也可以一块执行多个任务
(2)、NodeJs处理、响应模型
- 关于NodeJS单线程的误区
- NodeJs的单线程只是针对主进程,I/O操作系统底层多线程调度
- NodeJs的单线程并不是单进程
- NodeJs常用场景
- Web Server
- 本地代码构建(虽然其他语言构建可能效率更高,但是前端不care!!因为代价很高)
- 使用工具开发
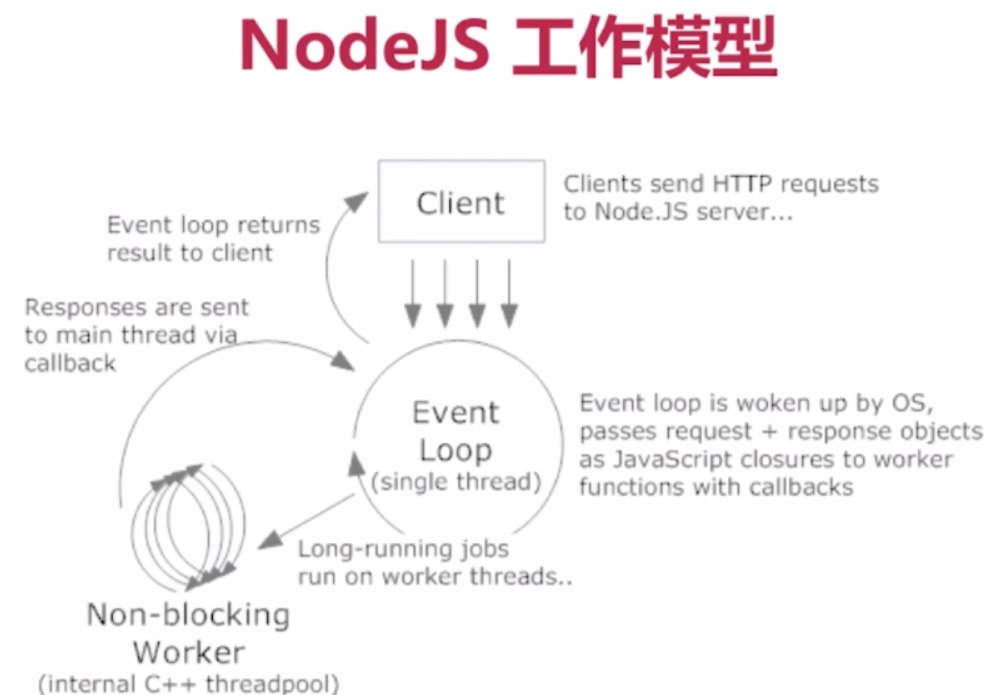
NodeJs的响应模型如下图,(理解可参考饭店:厨师、服务员做菜场景)。
二、环境和调试
包括以下:
- CommonJs //语法规范
- global //全局对象
- process //进程
1、CommonJS
规范如下:
- 每个文件是一个模块,有自己的作用域
- 在模块内部
module变量代表模块本身 module.exports属性代表模块对外接口
(1)、require
(a)、规则
- 支持```js、json、node````扩展名,不写则以此尝试。
- 不写路径,则认为是
build-in模块或者各级node_modules内的第三方模块
(b)、特性
module被加载的时候执行,加载和缓存- 一旦出现某个模块被循环加载,就只输出已经执行的部分,还未执行的部分不输出
效果执行代码如下:
// main.js
const modA = require('./modA')
const modB = require('./modB')
// modA.js
module.exports.test = 'A'
const modB = require('./modB')
console.log('modA', modB.test)
module.exports.test = 'AA';
// modB.js
module.exports.test = 'B'
const modA = require('./modA')
console.log('modB', modA.test)
module.exports.test = 'BB'
// 执行 main.js 最后打印值如下
PS C:\Users\DELL\Desktop\测试代码\nodeAPI> node .\main.js
modB A
modA BB
2、引用系统内置模块
(1)、fs文件读取
const fs = require('fs')
const result = fs.readFile('./modA.js',(err, data)=>{
if(err){
console.log(err)
}else {
console.log(data)
}
})
console.log('result', result) //同步 undefined
(2)、module
node文件中,exports是module.exports的简写。
module.exports.test = 'B'
等同于
exports.test = 'B'
// 错误,引文此写法改变了exports的指向
exports ={
a:1,
b:2,
test:'B'
}
// 正确
module.exports ={
a:1,
b:2,
test:'B'
}
(3)、global
node的全局变量,利用JavaScript的window。内置的全局对象包括:
- CommonJs
- Buffer、process、console
- timer
// modA.js
const testVar1 = 1000; // 当局作用域
global.testVar2 = 200; // 全局作用域
module.exports.testVar1 = testVar1
// main.js
const modA=require('./modA.js')
console.log(modA.testVar1) //1000
console.log(testVar2) //200
(4)、process
(5)、调试
三、基础API
1、path:路径
基本方法:
normalize、join、resolve// 路径规范化、规范化拼接、解析为绝对路径basename、extname、dirname// 路径最后一部分、扩展名、目录名parse、format// 返回路径对象、返回字符串sep、delimiter、win32、posix// 路径的分隔符
(1)、path.normalize(path)方法规范化给定的 path,并解析 '..' 和 '.' 片段
path.normalize('C:\\temp\\\\foo\\bar\\..\\');
// 返回: 'C:\\temp\\foo\\'
(2)、path.join(path)方法使用平台特定的分隔符作为定界符将所有给定的path片段连接在一起,然后 规范化 生成的路径。
零长度的 path 片段会被忽略。如果连接的路径字符串是零长度的字符串,则返回'.',表示当前工作目录。
path.join('/foo', 'bar', 'baz/asdf', 'quux', '..');
// 返回: '/foo/bar/baz/asdf'
//如果任何路径片段不是字符串,则抛出 TypeError。
path.join('foo', {}, 'bar');
// 抛出 'TypeError: Path must be a string. Received {}'
(3)、path.resolve(path)方法将路径或路径片段的序列解析为绝对路径。
给定的路径序列从右到左进行处理,每个后续的 path 前置,直到构造出一个绝对路径。
给定的路径片段序列:/foo、 /bar、 baz,调用path.resolve('/foo', '/bar', 'baz')将返回 /bar/baz。
path.resolve('/foo', '/bar', 'baz'
// 返回: '/bar/baz'
path.resolve('/foo/bar', './baz');
// 返回: '/foo/bar/baz'
path.resolve('/foo/bar', '/tmp/file/');
// 返回: '/tmp/file'
(4)、path.basename(path)方法返回 path 的最后一部分,类似于 Unix 的 basename 命令。 尾部的目录分隔符将被忽略。
path.basename('/foo/bar/baz/asdf/quux.html');
// 返回: 'quux.html'
path.basename('/foo/bar/baz/asdf/quux.html', '.html');
// 返回: 'quux'
(5)、path.extname(path)方法返回path的扩展名,从最后一次出现.(句点)字符到path 最后一部分的字符串结束。 如果在path的最后一部分中没有 .,或者如果path的基本名称(参阅path.basename())除了第一个字符以外没有 .,则返回空字符串。
path.extname('index.html');
// 返回: '.html'
path.extname('index.');
// 返回: '.'
path.extname('index');
// 返回: ''
path.extname('.index');
// 返回: ''
path.extname('.index.md');
// 返回: '.md'
(6)、path.dirname(path)方法返回 path 的目录名,类似于 Unix 的 dirname 命令。 尾部的目录分隔符将被忽略。
path.dirname('/foo/bar/baz/asdf/quux');
// 返回: '/foo/bar/baz/asdf'
(7)、path.parse(path)方法返回一个对象,其属性表示path的重要元素。尾部的目录分隔符将被忽略
返回的对象将具有以下属性:
- dir <string>
- root <string>
- base <string>
- name <string>
- ext <string>
Window上:
path.parse('C:\\path\\dir\\file.txt');
// 返回:
// { root: 'C:\\',
// dir: 'C:\\path\\dir',
// base: 'file.txt',
// ext: '.txt',
// name: 'file' }
(8)、path.format(pathObject) 方法从对象返回路径字符串。 与 path.parse() 相反。
(9)、path.sep提供平台特定的路径片段分隔符:
- Windows 上是
\。 - POSIX 上是
/。
在 Windows 上:
'foo\\bar\\baz'.split(path.sep);
// 返回: ['foo', 'bar', 'baz']
(10)、path.delimiter提供平台特定的路径定界符:
;用于 Windows:用于 POSIX
在 Windows 上:
console.log(process.env.PATH);
// 打印: 'C:\Windows\system32;C:\Windows;C:\Program Files\node\'
process.env.PATH.split(path.delimiter);
// 返回: ['C:\\Windows\\system32', 'C:\\Windows', 'C:\\Program Files\\node\\']
(11)、path.win32属性提供对特定于 Windows 的 path 方法的实现的访问。
注意两点:
__dirname、__filename总是返回文件的绝对路径process.cwd()总是返回执行node命令所在文件夹
2、Buffer:缓冲器
Buffer 类是作为 Node.jsAPI的一部分引入的,用于在TCP流、文件系统操作、以及其他上下文中与八位字节流进行交互。
Buffer用于处理二进制数据流- 实例类似整数数组,大小固定
C++代码在v8堆外分配物理内存Buffer类在全局作用域中,因此无需使用require('buffer').Buffer。
(1)、Buffer类内置的属性和方法:
Buffer.byteLengthBuffer.isBuffer()Buffer.concat()Buffer.alloc(size[, fill[, encoding]])// 分配一个大小为 size 字节的新 BufferBuffer.from(array)// 使用八位字节数组 array 分配一个新的 BufferBuffer.from(string[, encoding])// 创建一个包含 string 的新 Buffer。 encoding 参数指定 string 的字符编码
(a)、Buffer.byteLength(string)
返回字符串的实际字节长度。
const buf1 = Buffer.byteLength('test'); // 4
(b)、Buffer.isBuffer(obj)
判断一个对象是否Buffer
const buf1 = Buffer.isBuffer({}); // false
const buf2 = Buffer.isBuffer(Buffer.from([1,2,3])); // true
(c)Buffer.concat(Array)
返回一个合并了 list 中所有 Buffer 实例的新 Buffer。
/ 用含有三个 `Buffer` 实例的数组创建一个单一的 `Buffer`。
const buf1 = Buffer.alloc(10);
const buf2 = Buffer.alloc(14);
const buf3 = Buffer.alloc(18);
const totalLength = buf1.length + buf2.length + buf3.length;
console.log(totalLength);
// 打印: 42
(2)、Buffer实例的基本方法:
buf.lengthbuf.toString()buf.fill()buf.equals()// 两个buffer是否一样buf.indexOf()buf.copy()
(a)、buf.length
返回内存中分配给 buf 的字节数。 不一定反映 buf 中可用数据的字节量。
const buf1 = Buffer.from('this is a test')
const buf2 = Buffer.alloc(10)
console.log(buf1.length) // 14
console.log(buf2.length) // 10
(b)、buf.toString([encoding[, start[, end]]])
根据 encoding 指定的字符编码将 buf 解码成字符串。传入 start 和 end 可以只解码 buf 的子集。
const buf1 = Buffer.from('this is a test')
console.log(buf1.toLocaleString('base64')) // dGhpcyBpcyBhIHRlc3Q=
3、events:事件触发器
大多数 Node.js 核心 API构建于惯用的异步事件驱动架构,其中某些类型的对象(又称触发器,Emitter)会触发命名事件来调用函数(又称监听器,Listener)。
所有能触发事件的对象都是 EventEmitter 类的实例。
例子,一个简单的 EventEmitter 实例,绑定了一个监听器。 eventEmitter.on() 用于注册监听器, eventEmitter.emit() 用于触发事件。
const EventEmitter = require('events'); // 引入EventEmitter
class MyEmitter extends EventEmitter {} // 继承EventEmitter
const myEmitter = new MyEmitter(); // 实例化EventEmitter
myEmitter.on('event', () => {
console.log('触发事件');
});
myEmitter.emit('event');
4、fs:文件系统
fs 模块提供了一个 API,用于以模仿标准 POSIX 函数的方式与文件系统进行交互。
要使用此模块:
const fs = require('fs');
所有文件系统操作都具有同步和异步的形式。Node也提供了
异步的形式总是将完成回调作为其最后一个参数。传给完成回调的参数取决于具体方法,但第一个参数始终预留用于异常。如果操作成功完成,则第一个参数将为 null 或 undefined。
const fs = require('fs');
// 异步
fs.readFile('./test.js', 'utf8', (err, data)=> {
if(err) throw err;
console.log('异步:', data)
}
)
// 同步
const data = fs.readFileSync('./test.js', 'utf8');
console.log('同步:', data)
// 返回
// 虽然同步快于异步,但实际中还是用异步
PS C:\Users\DELL\Desktop\测试代码\nodeAPI> node .\main.js
同步: const title = 'this is a test'
异步: const title = 'this is a test'
基础方法包括:
fs.stat()// 文件信息fs.readdir()//读取目录fs.mkdir()// 新增fs.rmdir// 删除fs.watch// 监视
(1)、fs.Stats 类
fs.Stats 对象提供有关文件的信息。
从 fs.stat()、fs.lstat() 和 fs.fstat() 及其同步方法返回的对象都属于此类型。如果传给这些方法的 options 中的 bigint 为 true,则数值将为 bigint 型而不是 number 型。
5、util:使用工具
util 模块主要用于支持 Node.js 内部 API 的需求。 大部分实用工具也可用于应用程序与模块开发者。
使用方法如下:
const util = require('util');
(1)、util.promisify(original)
const fs = require('fs')
const promisify = require('util').promisify
const read = promisify(fs.readFile)
read('./test.js').then(data => {
console.log(data.toString())
}).catch(ex => {
console.log(ex)
})
或者,使用 async function 获得等效的效果:
async function test() {
try {
const content = await read('./test.js');
console.log(content.toString())
} catch (ex) {
console.log(ex)
}
}
test()
