

数据量越来越大怎么办呢? — 使用HDFS
一HDFS概念
1.什么是HDFS:
hadoop 实现了一个分布式文件系统 hadoop distributed file system ,HDFS
2.HDFS 文件系统的优缺点
***HDFS优点: 数据冗余,高容错 处理流式的数据访问(一次写入,多次查询) 适合存储大文件 可构建在廉价机器上,可扩展 ***HDFS缺点: 低延迟的数据访问 不适合小文件存储(1m-127m,小文件越多,意味着元数据所占用的内存越大,对于HDFS压力更大 NameNode里面的元数据存放:内存里,也会刷磁盘) |
二HDFS架构
1.架构
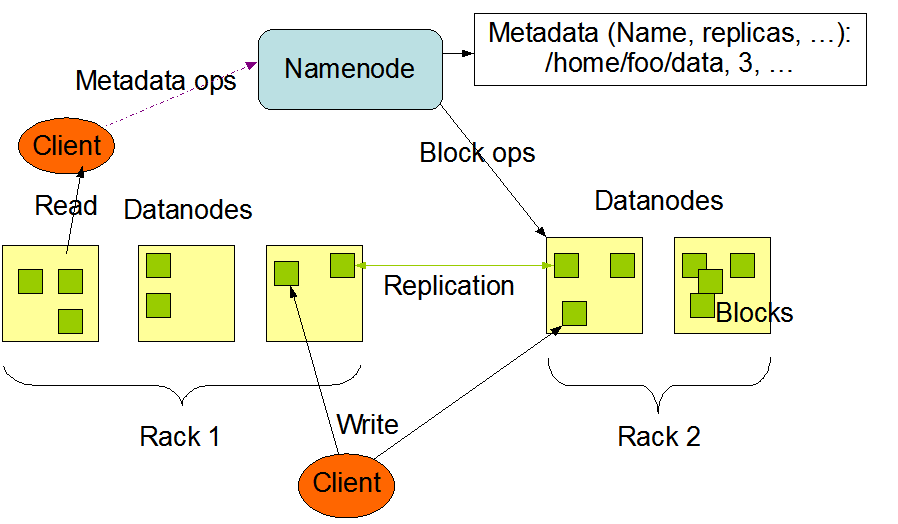
1个Master(NameNode NN)带N个Slaves(DataNode DN)。
NameNode+N个DataNode: 建议NN和DN部署在不同节点(机器)上
一个文件会被拆分成多个Block
blocksize:128M
130M==>2个Block:128M, 2M2.副本机制
HDFS文件一次性写入(除了更新或者截断),不支持多并发写,一次只能一个写
举个例子:
文件名: part ,是一个300M文件
分成文件块: blockid=1 ,blockid=3
有2个副本,每个block有2个副本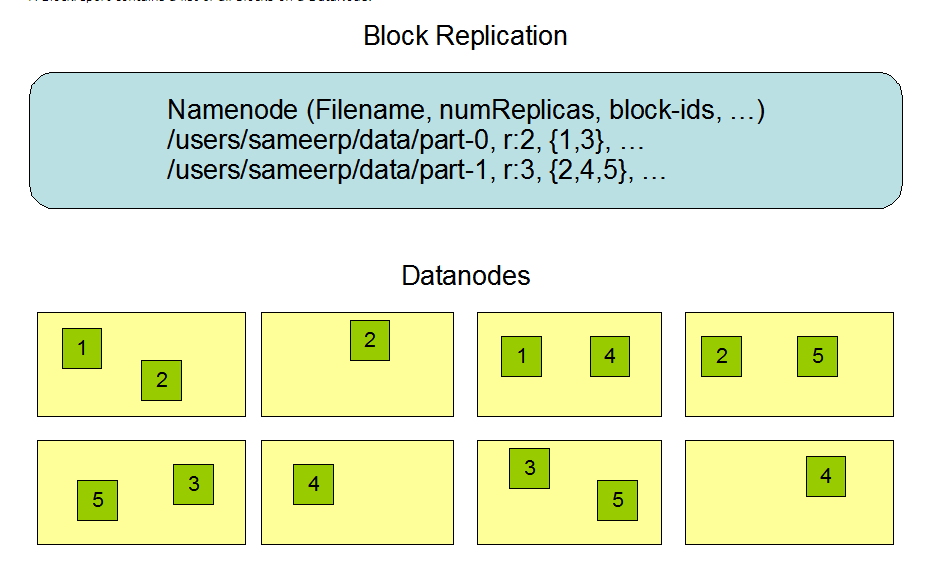
三搭建HDFS
1 安装JDK
1解压 tar -zxvf jdk-7u79-linux-x64.tar.gz -C ~/app/ 2进到解压好的文件夹下 jdk1.7.0_79 3添加到系统环境变量:$JAVA_HOME,之后方便使用。配置在当前用户下.bash_profile里JAVA_HOME配置好,再配置到系统的$PATH上4环境变量生效:source ~/.bash_profile5java是否安装成功: java -version2安装SSH
1安装ssh: sudo yum install ssh2配置免密码登录:ssh-keygen -t rsa # key保存在/home/hadoop/.ssh/id_rsa3拷贝ssh key 到认证文件夹中:cp ~/.ssh/id_rsa.pub ~/.ssh/authorized_keys3安装和部署Hadoop
1CDH官网下载hadoop安装包hadoop-2.6.0-cdh5.7.0.tar.gz
2解压
3修改配置文件hadoop-env.sh | export JAVA_HOME=${JAVA_HOME} #JAVA jdk安装路径,需要具体的路径 |
core-site.xml | <configuration> <property> <name>fs.defaultFS</name> #hdfs默认的文件系统地址 <value>hdfs://myhadoop:8020</value> #机器名 /etc/hosts </property> <property> <name>hadoop.tmp.dir</name> #hdfs临时文件存储 <value>/home/hadoop/app/tmp</value> </property> </configuration> |
hdfs-site.xml | <configuration> <property> <name>dfs.replication</name> #副本系数 <value>1</value> </property> </configuration> |
集群 : NameNode和DataNode怎么关联?
一个NN带多个DN,有多少个datanode,就把datanode的hostname写到slaves文件中 |
4启动HDFS
1 hdfs namenode -format #仅第一次执行,不可重复执行!!如果重复执行了呢?请移步《大数据问题集锦》
2启动hdfs: ./start-dfs.sh5验证是否启动成功:
方式一:查看进程jps,有下面4个进程,就对了!
NameNode
SecondaryNameNode
Jps
DataNode通过浏览器访问:http://myhadoop:50070
可以看到datanode, namenode ,secondarynamenode
启动成功!四HDFS简单使用
从本地上传文件,上传hellowangjx.txt : | hadoop fs -put hellowangjx.txt / |
查看已经上传的文件 | hadoop fs -ls / |
hdfs上创建目录 | 递归创建文件夹:hadoop fs -mkdir -p /test/a/b/c 递归展示文件夹:hadoop fs -ls -R / |
hdfs上的文件拿到本地 | 当前目录下: hadoop fs -get /test/a/b/h.txt hh.txt |
hdfs删除操作 | 删除文件:hadoop fs -rm /hellowangjx.txt |
hdfs查看文件内容 | 查看文件内容 : hadoop fs -text /hello.txt |
五HDFS容错机制
1 node server 跪了
NameNode跪了,整个集群跪 |
DataNode跪了,转移到其他副本,并且没有心跳(3s/次),NameNode超过10分钟没收到DN心跳,无论DataNode是否挂了(网络不好)就当他挂了 |
2脏数据问题
传输数据的同时会发送总和校验码Checksum,当DN存储数据的时候Checksum也会存储起来。 DN定期向NN发送心跳和DN情况,发送之前会检查Checksum是否正确,错误的话 就不发送这个数据块的信息。 |
3读写容错
写容错: client向DN传送数据,DN存储之后会发送ACK给client。如果client没有收到,则认为DN挂了,之后client发送数据就会调整路线,跳过挂了的DN。 NN也会注意到副本比配置个数少。 |
读容错: client从NN拿到文件 块 副本的位置,从距离最近的读,如果该DN挂了,则从下一个读取 |
六 Java操作 HDFS
1开发环境搭建
1本地eclipse创建maven工程 : maven quickstart
2配置pom.xml: 添加HDFS相关依赖2 使用Java API 操作 HDFS文件
Demo链接: 后补
大数据相关目录
开森滴玩大数据——Hadoop juejin.cn/post/684490…
开森滴玩大数据——HDFS
开森滴玩大数据——Yarn
开森滴玩大数据——MapReduce
开森滴玩大数据——单机Demo
开森滴玩大数据——搭建Yarn集群
《大数据问题集锦》—— 走过最长的路,是大数据的套路
