

一、MySQL索引
1.1、索引的优势和劣势
优势
1)类似于书籍的目录索引,提高数据检索的效率,降低数据库的IO成本。
2)通过索引列对数据进行排序,降低数据排序的成本,降低CPU的消耗。
劣势
1)实际上索引也是一张表,该表中保存了主键与索引字段,并指向实体类的记录,所以索引列也是要占用空间的。
2)虽然索引大大提高了查询效率,同时却也降低更新表的速度,如对表进行INSER、UPDATE、DELETE。因为更新表时,MySQL不仅要保存数据,还要保存一下索引文件每次更新添加了索引列的字段,都会调整因为更新所带来的键值变化后的索引信息。
1.2、索引结构
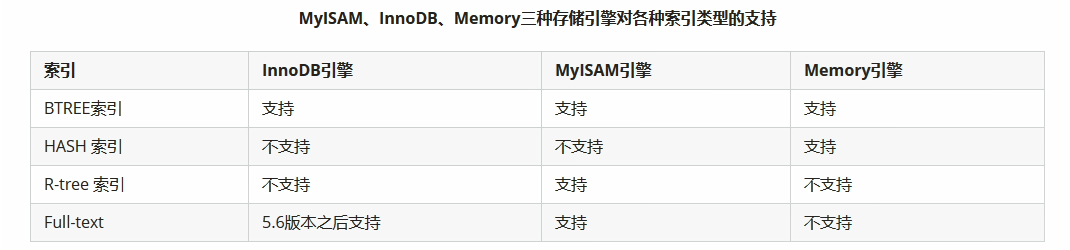
1)BTREE索引:最常见的索引类型,大部分索引都支持B树索引。
2)HASH索引:只有Memory引擎支持,使用场景简单。
3)R-tree索引(空间索引):空间索引是MyISAM引擎的一个特殊索引,主要用于地理空间数据类型,通常使用较少,不做特别介绍。
4)Full-text(全文索引):全文索引也是MyISAM的一个特殊索引类型,主要用于全文索引,InnoDB从MySQL5.6版本开始支持全文索引。
我们平常说的索引,如果没有特别指明,都是指B+树(多路搜索树,并不一定是二叉的)结构组织的索引。其中聚集索引、复合索引、前缀索引、唯一索引默认都是使用B+tree树索引,统称为索引。
1.3、索引分类
1)单值索引:即一个索引只包含单个列,一个表可以有多个单列索引。
2)唯一索引:索引列的值必须唯一,但允许有空值。
3)复合索引:即一个索引包含多个列。
1.4、 索引的语法
索引在创建表的时候,可以同时创建,也可以随时增加新的索引。
准备环境:
create database demo_01 default charset=utf8mb4;
use demo_01;
CREATE TABLE `city` ( `city_id` int(11) NOT NULL AUTO_INCREMENT, `city_name` varchar(50) NOT NULL, `country_id` int(11) NOT NULL, PRIMARY KEY (`city_id`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8;
CREATE TABLE `country` ( `country_id` int(11) NOT NULL AUTO_INCREMENT, `country_name` varchar(100) NOT NULL,
PRIMARY KEY (`country_id`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8;
insert into `city` (`city_id`, `city_name`, `country_id`) values(1,'西安',1);
insert into `city` (`city_id`, `city_name`, `country_id`) values(2,'NewYork',2);
insert into `city` (`city_id`, `city_name`, `country_id`) values(3,'北京',1);
insert into `city` (`city_id`, `city_name`, `country_id`) values(4,'上海',1);
insert into `country` (`country_id`, `country_name`) values(1,'China');
insert into `country` (`country_id`, `country_name`) values(2,'America');
insert into `country` (`country_id`, `country_name`) values(3,'Japan');
insert into `country` (`country_id`, `country_name`) values(4,'UK');1.5、创建索引
语法:
CREATE [UNIQUE|FULLTEXT|SPATIAL] INDEX index_name
//中括号中是索引的类型,index_name是索引的名称
[USING index_type]
//用来指定索引的类型,不指定默认为BTREE索引
ON tbl_name(index_col_name,...)
//对哪一张表的那一个字段创建索引
index_col_name : column_name[(length)][ASC | DESC1.6、删除索引
语法:
DROP INDEX index_name ON tbl_name;1.7、ALTER命令
语法:
1). alter table tb_name add primary key(column_list);
//该语句添加一个主键,这意味着索引值必须是唯一的,且不能为NULL
2). alter table tb_name add unique index_name(column_list);
//这条语句创建索引的值必须是唯一的(除了NULL外,NULL可能会出现多次)
3). alter table tb_name add index index_name(column_list);
// 添加普通索引, 索引值可以出现多次。
4). alter table tb_name add fulltext index_name(column_list);
该语句指定了索引为FULLTEXT, 用于全文索引 1.8索引设计原则
索引的设计可以遵循一些已有的原则,创建索引的时候请尽量考虑符合这些原则,便于提升索引的使用效率,更高 效的使用索引。
1)对查询频次较高,且数据量比较大的表建立索引。
2)索引字段的选择,最佳候选列应当从where子句的条件中提取,如果where子句中的组合比较多,那么应当挑 选最常用、过滤效果最好的列的组合。
3)使用唯一索引,区分度越高,使用索引的效率越高。
4)索引可以有效的提升查询数据的效率,但索引数量不是多多益善,索引越多,维护索引的代价自然也就水涨 船高。对于插入、更新、删除等DML操作比较频繁的表来说,索引过多,会引入相当高的维护代价,降低 DML操作的效率,增加相应操作的时间消耗。另外索引过多的话,MySQL也会犯选择困难病,虽然最终仍然 会找到一个可用的索引,但无疑提高了选择的代价。
5)使用短索引,索引创建之后也是使用硬盘来存储的,因此提升索引访问的I/O效率,也可以提升总体的访问效 率。假如构成索引的字段总长度比较短,那么在给定大小的存储块内可以存储更多的索引值,相应的可以有 效的提升MySQL访问索引的I/O效率。
6)利用最左前缀,N个列组合而成的组合索引,那么相当于是创建了N个索引,如果查询时where子句中使用了 组成该索引的前几个字段,那么这条查询SQL可以利用组合索引来提升查询效率。
创建复合索引:
CREATE INDEX idx_name_email_status ON tb_seller(NAME,email,STATUS);
就相当于
对name 创建索引 ;
对name , email 创建了索引 ;
对name , email, status 创建了索引 ;二、视图
2.1、视图概念
视图(View)是一种虚拟存在的表。视图并不在数据库中实际存在,行和列数据来自定义视图的查询中使用的表, 并且是在使用视图时动态生成的。通俗的讲,视图就是一条SELECT语句执行后返回的结果集。所以我们在创建视 图的时候,主要的工作就落在创建这条SQL查询语句上。 视图相对于普通的表的优势主要包括以下几项。
1)简单:使用视图的用户完全不需要关心后面对应的表的结构、关联条件和筛选条件,对用户来说已经是过滤 好的复合条件的结果集。
2)安全:使用视图的用户只能访问他们被允许查询的结果集,对表的权限管理并不能限制到某个行某个列,但 是通过视图就可以简单的实现。
3)数据独立:一旦视图的结构确定了,可以屏蔽表结构变化对用户的影响,源表增加列对视图没有影响;源表 修改列名,则可以通过修改视图来解决,不会造成对访问者的影响。
4)视图只是为了方便查询,不建议修改视图。
2.2创建或者修改视图
创建视图的语法为:
CREATE [OR REPLACE] [ALGORITHM = {UNDEFINED | MERGE | TEMPTABLE}]
VIEW view_name [(column_list)]
AS select_statement
//as后面跟的sql语句
[WITH [CASCADED | LOCAL] CHECK OPTION]ALTER [ALGORITHM = {UNDEFINED | MERGE | TEMPTABLE}]
VIEW view_name [(column_list)]
AS select_statement
[WITH [CASCADED | LOCAL] CHECK OPTION]选项 :
WITH [CASCADED | LOCAL] CHECK OPTION 决定了是否允许更新数据使记录不再满足视图的条件。
LOCAL : 只要满足本视图的条件就可以更新。
CASCADED : 必须满足所有针对该视图的所有视图的条件才可以更新。 默认值.create or replace view city_country_view
as
select t.*,c.country_name from country c , city t where c.country_id = t.country_id;
2.3删除视图
语法:
DROP VIEW [IF EXISTS] view_name [, view_name] ...[RESTRICT | CASCADE]
//if exists 表示如果存在 if not exists 表示如果不存在 DROP VIEW city_country_view;三、存储过程和函数
3.1、存储过程和函数概述
存储过程和函数是 事先经过编译并存储在数据库中的一段 SQL 语句的集合,调用存储过程和函数可以简化应用开 发人员的很多工作,减少数据在数据库和应用服务器之间的传输,对于提高数据处理的效率是有好处的。
存储过程和函数的区别在于函数必须有返回值,而存储过程没有。
函数 : 是一个有返回值的过程 ;
过程 : 是一个没有返回值的函数 ;
3.2、创建存储过程
CREATE PROCEDURE procedure_name ([proc_parameter[,...]])
begin
-- SQL语句
end ;//声明分隔符为$,这样在输入;的时候sql语句就不会执行,只有输入$才会执行
delimiter $
create procedure pro_test1() begin select 'Hello Mysql' ; end$
// 把分隔符改为默认
delimiter ;3.3、调用存储过程
//call 存储过程名称
call procedure_name() ;3.4、查看存储过程
-- 查询db_name数据库中的所有的存储过程
select name from mysql.proc where db='db_name';
-- 查询存储过程的状态信息
show procedure status;
-- 查询某个存储过程的定义
show create procedure test.pro_test1 \G;3.5、删除存储过程
DROP PROCEDURE [IF EXISTS] sp_name ;3.6、语法
存储过程是可以编程的,意味着可以使用变量,表达式、控制结构,来完成比较复杂的功能。
3.6.1、变量
1)DECLARE
通过DECLARE可以定义一个局部变量,该变量的作用范围只能在BEGIN......END块中。
DECLATR var_name[,...] type [DEFAULT value示例:
delimiter $
create procedure pro_test2()
begin
declare num int default 5;
select num+ 10;
end$
delimiter ; 直接赋值使用SET,可以赋值常量或者赋值表达式,具体语法如下:
SET var_name =expr[,var_name=expar]...DELIMITER $
CREATE PROCEDURE pro_test3()
BEGIN
DECLARE NAME VARCHAR(20);
SET NAME = 'MYSQL';
SELECT NAME ;
END$
DELIMITER ;DELIMITER $
CREATE PROCEDURE pro_test5()
BEGIN
declare countnum int;
select count(*) into countnum from city;
select countnum;
END$
DELIMITER ;3.6.2、if条件判断
语法结构:
if search_condition then statement_list
[elseif search_condition then statement_list] ...
[else statement_list]
end if;根据定义的身高变量,判定当前身高的所属的身材类型
180 及以上 ----------> 身材高挑
170 - 180 ---------> 标准身材
170 以下 ----------> 一般身材示例:
delimiter $
create procedure pro_test6()
begin
declare height int default 175;
declare description varchar(50);
if
height >= 180
then set description = '身材高挑';
elseif
height >= 170 and height < 180
then set description = '标准身材';
else
set description = '一般身材';
end if;
select description ;
end$
delimiter ;3.6.3、传递参数
语法格式:
create procedure procedure_name([in/out/inout] 参数名 参数类型) ...
IN : 该参数可以作为输入,也就是需要调用方传入值 , 默认
OUT: 该参数作为输出,也就是该参数可以作为返回值
INOUT: 既可以作为输入参数,也可以作为输出参数IN-输入
需求:
根据定义的身高变量,判断当前身高的所属的身材类型。delimiter $
create procedure pro_test5(in height int)
begin
declare description varchar(50) default '';
if height>=180 then
set descriptino='身材高挑';
elseif height >= 170 and height < 180 then
set description = '标准身材';
else
set description = '一般身材';
end if;
select description ;
end$
delimiter ;OUT-输出
需求:
根据传入的身高变量,获取当前身高的所属的身材类型delimiter $
create procedure pro_test5(in height int , out description varchar(100))
begin
if height >= 180 then
set description='身材高挑';
elseif height >= 170 and height < 180 then
set description='标准身材';
else
set description='一般身材';
end if;
end$
delimiter ;call pro_test5(168, @description)$
select @description$@description : 这种变量要在变量名称前面加上“@”符号,叫做用户会话变量,代表整个会话过程他都是有作用 的,这个类似于全局变量一样。 @@global.sort_buffer_size : 这种在变量前加上 "@@" 符号, 叫做 系统变量
3.6.4、case结构
语法结构:
方式一 :
CASE case_value
WHEN when_value THEN statement_list
[WHEN when_value THEN statement_list] ...
[ELSE statement_list]
END CASE;
方式二 :
CASE
WHEN search_condition THEN statement_list
[WHEN search_condition THEN statement_list] ...
[ELSE statement_list]
END CASE;给定一个月份, 然后计算出所在的季度。delimiter $
create procedure pro_test9(month int)
begin
declare result varchar(20);
case
when month >= 1 and month <=3 then
set result = '第一季度';
when month >= 4 and month <=6 then
set result = '第二季度';
when month >= 7 and month <=9 then
set result = '第三季度';
when month >= 10 and month <=12 then
set result = '第四季度';
end case;
select concat('您输入的月份为 :', month , ' , 该月份为 : ' , result) as content ;
end$
delimiter ;3.6.5、while循环
语法结构:
while search_condition do
statement_list
end while;计算从1加到n的值。delimiter $
create procedure pro_test8(n int)
begin
declare total int default 0;
declare num int default 1;
while num<=n do
set total = total + num;
set num = num + 1;
end while;
select total;
end$
delimiter ;3.6.6、repeat结构
有条件的循环控制语句, 当满足条件的时候退出循环 。while 是满足条件才执行,repeat 是满足条件就退出循环
语法结构:
REPEAT
statement_list
UNTIL search_condition //满足这个条件退出循环
END REPEAT;计算从1加到n的值。delimiter $
create procedure pro_test10(n int)
begin
declare total int default 0;
repeat
set total = total + n;
set n = n - 1;
until n=0 //没有分号,不要加分号
end repeat;
select total ;
end$
delimiter ;3.6.7、loop语句
LOOP 实现简单的循环,退出循环的条件需要使用其他的语句定义,通常可以使用 LEAVE 语句实现,具体语法如 下:
[begin_label:] LOOP
statement_list
END LOOP [end_label]如果不在 statement_list 中增加退出循环的语句,那么 LOOP 语句可以用来实现简单的死循环。
3.6.8、leave语句
用来从标注的流程构造中退出,通常和 BEGIN ... END 或者循环一起使用。下面是一个使用 LOOP 和 LEAVE 的简 单例子 , 退出循环:
delimiter $
CREATE PROCEDURE pro_test11(n int)
BEGIN
declare total int default 0;
ins: LOOP
IF n <= 0 then
leave ins;
END IF;
set total = total + n;
set n = n - 1;
END LOOP ins;
select total;
END$
delimiter ;3.6.9、游标/光标
游标是用来存储查询结果集的数据类型 , 在存储过程和函数中可以使用光标对结果集进行循环的处理。光标的使用 包括光标的声明、OPEN、FETCH 和 CLOSE,其语法分别如下。
声明光标:
DECLARE cursor_name CURSOR FOR select_statement ; //for后面跟select SQL语句OPEN cursor_name ; //指定一个游标名称,打开游标FETCH cursor_name INTO var_name [, var_name] ... //调用一次FETCh指针就下移一位CLOSE 光标:
CLOSE cursor_name ;示例:
初始化脚本:
create table emp(
id int(11) not null auto_increment ,
name varchar(50) not null comment '姓名',
age int(11) comment '年龄',
salary int(11) comment '薪水',
primary key(`id`)
)engine=innodb default charset=utf8 ;
insert into emp(id,name,age,salary) values
(null,'金毛狮王',55,3800),
(null,'白眉鹰 王',60,4000),
(null,'青翼蝠王',38,2800),
(null,'紫衫龙王',42,1800);
-- 查询emp表中数据, 并逐行获取进行展示
create procedure pro_test11()
begin
declare e_id int(11);
declare e_name varchar(50);
declare e_age int(11);
declare e_salary int(11);
declare emp_result cursor for
select * from emp;
open emp_result;
fetch emp_result into e_id,e_name,e_age,e_salary;
select concat('id=',e_id , ', name=',e_name, ', age=', e_age, ', 薪资为: ',e_salary);
fetch emp_result into e_id,e_name,e_age,e_salary;
select concat('id=',e_id , ', name=',e_name, ', age=', e_age, ', 薪资为: ',e_salary);
fetch emp_result into e_id,e_name,e_age,e_salary;
select concat('id=',e_id , ', name=',e_name, ', age=', e_age, ', 薪资为: ',e_salary);
fetch emp_result into e_id,e_name,e_age,e_salary;
select concat('id=',e_id , ', name=',e_name, ', age=', e_age, ', 薪资为: ',e_salary);
//如果fetch 次数超过总数量,会报错
close emp_result;
end$
delimiter ;
DELIMITER $
create procedure pro_test12()
begin
DECLARE id int(11);
DECLARE name varchar(50);
DECLARE age int(11);
DECLARE salary int(11);
DECLARE has_data int default 1;
DECLARE emp_result CURSOR FOR
select * from emp;
DECLARE EXIT HANDLER FOR NOT FOUND set has_data = 0; //当数据拿不到的时候会触发这句话
open emp_result;
repeat
fetch emp_result into id , name , age , salary;
select concat('id为',id, ', name 为' ,name , ', age为 ' ,age , ', 薪水为: ', salary);
until has_data = 0
end repeat;
close emp_result;
end$
DELIMITER ; 3.7、存储函数
语法结构:
CREATE FUNCTION function_name([param type ... ])
RETURNS type BEGIN
...
END; 定义一个存储过程, 请求满足条件的总记录数 ;
delimiter $
create function count_city(countryId int)
returns int //返回值类型
begin
declare cnum int ;
select count(*) into cnum from city where country_id = countryId;
return cnum;
end$
delimiter ;select count_city(1);
select count_city(2);四、触发器
4.1、介绍
触发器是与表有关的数据库对象,指在 insert/update/delete 之前或之后,触发并执行触发器中定义的SQL语句集 合。触发器的这种特性可以协助应用在数据库端确保数据的完整性 , 日志记录 , 数据校验等操作 。
使用别名 OLD 和 NEW 来引用触发器中发生变化的记录内容,这与其他的数据库是相似的。现在触发器还只支持 行级触发,不支持语句级触发。

4.2、创建触发器
语法结构:
create trigger trigger_name
before/after insert/update/delete
on tbl_name
[ for each row ] -- 行级触发器
begin
trigger_stmt ;
end; 需求:
通过触发器记录 emp 表的数据变更日志 , 包含增加, 修改 , 删除 首先创建一张日志表
create table emp_logs(
id int(11) not null auto_increment,
operation varchar(20) not null comment '操作类型, insert/update/delete',
operate_time datetime not null comment '操作时间',
operate_id int(11) not null comment '操作表的ID',
operate_params varchar(500) comment '操作参数',
primary key(`id`)
)engine=innodb default charset=utf8;DELIMITER $
create trigger emp_logs_insert_trigger
after insert
on emp
for each row
begin
insert into emp_logs (id,operation,operate_time,operate_id,operate_params) values
(null,'insert',now(),new.id,concat('插入后(id:',new.id,', name:',new.name,', age:',new.age,', salary:',new.salary,')'));
end $
DELIMITER ;DELIMITER $
create trigger emp_logs_update_trigger
after update
on emp
for each row
begin
insert into emp_logs (id,operation,operate_time,operate_id,operate_params) values(null,'update',now(),new.id,concat('修改前(id:',old.id,', name:',old.name,', age:',old.age,', salary:',old.salary,') , 修改后(id',new.id, 'name:',new.name,', age:',new.age,', salary:',new.salary,')'));
end $
DELIMITER ;DELIMITER $
create trigger emp_logs_delete_trigger
after delete
on emp for each row
begin
insert into emp_logs (id,operation,operate_time,operate_id,operate_params) values(null,'delete',now(),old.id,concat('删除前(id:',old.id,', name:',old.name,', age:',old.age,', salary:',old.salary,')')); end $
end $
DELIMITER ;测试:
insert into emp(id,name,age,salary) values(null, '光明左使',30,3500);
insert into emp(id,name,age,salary) values(null, '光明右使',33,3200);
update emp set age = 39 where id = 3;
delete from emp where id = 5;4.3、删除触发器
语法结构:
drop trigger [schema_name.]trigger_name4.4 、查看触发器
可以通过执行 SHOW TRIGGERS 命令查看触发器的状态、语法等信息。
语法结构:
show triggers ;