

在python中,序列化可以理解为:把python的对象编码转换为json格式的字符串,反序列化可以理解为:把json格式字符串解码为python数据对象。在python的标准库中,专门提供了json库与pickle库来处理这部分。
先来学习json的库,导入json库很简单,直接import json,下面通过具体的实例来说明json库对序列化与反序列化的使用。json库的主要方法为:
#!/usr/bin/env python
#coding:utf-8
import json
print json.__all__
见json库的主要方法:
['dump', 'dumps', 'load', 'loads', 'JSONDecoder', 'JSONEncoder']
定义一个字典,通过json把它序列化为json格式的字符串,见实现的代码:
#!/usr/bin/env python
#coding:utf-8
import json
dict1={'name':'chuansinfo','age':25,'address':'shenzhen'}
print u'未序列化前的数据类型为:',type(dict1)
print u'未序列化前的数据:',dict1
#对dict1进行序列化的处理
str1=json.dumps(dict1)
print u'序列化后的数据类型为:',type(str1)
print u'序列化后的数据为:',str1
如上的代码输出的内容:
C:\Python27\python.exe D:/git/Python/doc/index.py
未序列化前的数据类型为: <type 'dict'>
未序列化前的数据: {'age': 25, 'name': 'chuansinfo', 'address': 'shenzhen'}
序列化后的数据类型为: <type 'str'>
序列化后的数据为: {"age": 25, "name": "chuansinfo", "address": "shenzhen"}
Process finished with exit code 0
通过如上的代码以及结果可以看到,这就是一个序列化的过程,简单的说就是把python的数据类型转换为json格式的字符串。下来我们再反序列化,把json格式的字符串解码为python的数据对象,见实现的代码和输出:
#!/usr/bin/env python
#coding:utf-8
import json
dict1={'name':'chuansinfo','age':25,'address':'shenzhen'}
print u'未序列化前的数据类型为:',type(dict1)
print u'未序列化前的数据:',dict1
#对dict1进行序列化的处理
str1=json.dumps(dict1)
print u'序列化后的数据类型为:',type(str1)
print u'序列化后的数据为:',str1
#对str1进行反序列化
dict2=json.loads(str1)
print u'反序列化后的数据类型:',type(dict2)
print u'反序列化后的数据:',dict2
见输出结果的内容:
C:\Python27\python.exe D:/git/Python/doc/index.py
未序列化前的数据类型为: <type 'dict'>
未序列化前的数据: {'age': 25, 'name': 'chuansinfo', 'address': 'shenzhen'}
序列化后的数据类型为: <type 'str'>
序列化后的数据为: {"age": 25, "name": "chuansinfo", "address": "shenzhen"}
反序列化后的数据类型: <type 'dict'>
反序列化后的数据: {u'age': 25, u'name': u'chuansinfo', u'address': u'shenzhen'}
我们结合requests库,来看返回的json数据,具体代码为:
#!/usr/bin/env python
#coding:utf-8
import json
import requests
r=requests.get('http://wthrcdn.etouch.cn/weather_mini?city=西安')
print r.text,u'数据类型:',type(r.text)
#对数据进行反序列化的操作
dic=json.loads(r.text)
print dic,u'数据类型:',type(dic)
见输出的内容:

在如上的代码中,我们可以不通过反序列化的操作,代码可以简化为:
#!/usr/bin/env python
#coding:utf-8
import json
import requests
r=requests.get('http://wthrcdn.etouch.cn/weather_mini?city=西安')
print r.json(),u'数据类型为:',type(r.json())
见输出的内容:

在实际的工作中,序列化或者反序列化的可能是一个文件的形式,不可能像如上写的那样简单的,下来就来实现这部分,把文件内容进行序列化和反序列化,先来看序列化的代码:
#!/usr/bin/env python
#coding:utf-8
import json
list1=['selenium','appium','android','ios','uiautomator']
#把list1先序列化,再写入到一个文件中
print json.dump(list1,open('c:/log.log','w'))
print u'文件内容为:'
r=open('c:/log.log','r+')
print r.read()
见输出的内容:
C:\Python27\python.exe D:/git/Python/doc/index.py
None
文件内容为:
["selenium", "appium", "android", "ios", "uiautomator"]
Process finished with exit code 0
下面我们来反序列化,也就是先读取文件里面的内容,再进行反序列化,见实现的代码:
#!/usr/bin/env python
#coding:utf-8
import json
list1=['selenium','appium','android','ios','uiautomator']
#把list1先序列化,再写入到一个文件中
print json.dump(list1,open('c:/log.log','w'))
print u'文件内容为:'
r=open('c:/log.log','r+')
print r.read()
#先读取文件内容,再进行反序列化
res=json.load(open('c:/log.log','r+'))
print res,u'数据类型:',type(res)
见输出的内容:
C:\Python27\python.exe D:/git/Python/doc/index.py
None
文件内容为:
["selenium", "appium", "android", "ios", "uiautomator"]
[u'selenium', u'appium', u'android', u'ios', u'uiautomator'] 数据类型: <type 'list'>
Process finished with exit code 0
下来来看pickle库,它提供的方法为:
#!/usr/bin/env python
#coding:utf-8
import pickle
print pickle.__all__

这里我们只关注pickle库的dump(),dumps(),load(),loads()方法,先来看序列化的代码:
import pickle
dic={'name':'川石','age':25,'address':'深圳'}
str1=pickle.dumps(dic)
print str1,type(str1)
见输出的内容:
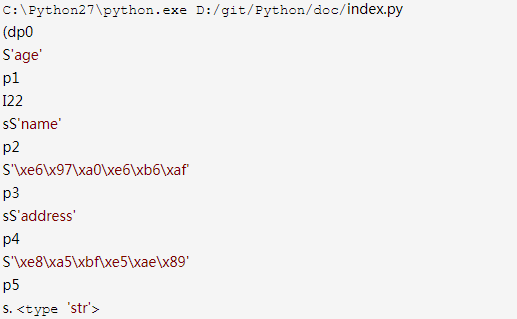
输出的内容基本看不懂,但是可以看到数据格式是字符串,这是ASCII格式的数据,默认是ASCII格式保存对象,在进行序列化的使用,设置为True就是二进制保存对象,见实现的代码和输出内容:
#!/usr/bin/env python
#coding:utf-8
import pickle
dic={'name':'川石','age':25,'address':'深圳'}
str1=pickle.dumps(dic,True)
print str1,type(str1)
见输出的二进制的数据:
C:\Python27\python.exe D:/git/Python/doc/index.py
}q (UageqKUnameqU川石qUaddressqU深圳qu. <type 'str'>
下面通过loads()方法来进行反序列化,见实现的代码:
#!/usr/bin/env python
#coding:utf-8
import pickle
dic={'name':u'川石','age':25,'address':u'深圳'}
#序列化
str1=pickle.dumps(dic,True)
print str1,type(str1)
#反序列化
dict1=pickle.loads(str1)
print dict1,type(dict1)
见输出的内容:
C:\Python27\python.exe D:/git/Python/doc/index.py
}q (UageqKUnameqX 川石qUaddressqX 深圳qu. <type 'str'>
{'age': 25, 'name': u'\u65e0\u6daf', 'address': u'\u897f\u5b89'} <type 'dict'>
下来我们通过对文件的形式来进行序列化和反序列化,见实现的代码:
#!/usr/bin/env python
#coding:utf-8
import pickle
dic={'name':u'川石','age':25,'address':u'深圳'}
#先序列化,然后写入到文件中
pickle.dump(dic,open('c:/log.log','w'),True)
print u'文件内容为:'
print open('c:/log.log').read()
#先读取文件,再反序列化
d=pickle.load(open('c:/log.log','r+'))
print u'反序列化后的数据与数据类型:',d,type(d)
见输出的内容:
C:\Python27\python.exe D:/git/Python/doc/index.py
文件内容为:
}q (UageqKUnameqX 川石qUaddressqX 深圳qu.
反序列化后的数据与数据类型: {'age': 25, 'name': u'\u65e0\u6daf', 'address': u'\u897f\u5b89'} <type 'dict'>
Process finished with exit code 0
