

优先队列,这个底层使用了二叉堆.所以先来介绍什么是二叉堆.
阅读链接BinaryHeaps
首先介绍两个概念。最大堆和最小堆。
最小堆:父节点<=所有子节点,子节点之间没有任何关系(包括兄弟节点)
最大堆:父节点>=所有子节点,子节点之间没有任何关系(包括兄弟节点)
因为差不多.只说一个用最小堆示例,这是一个完全二叉树.
insertMin
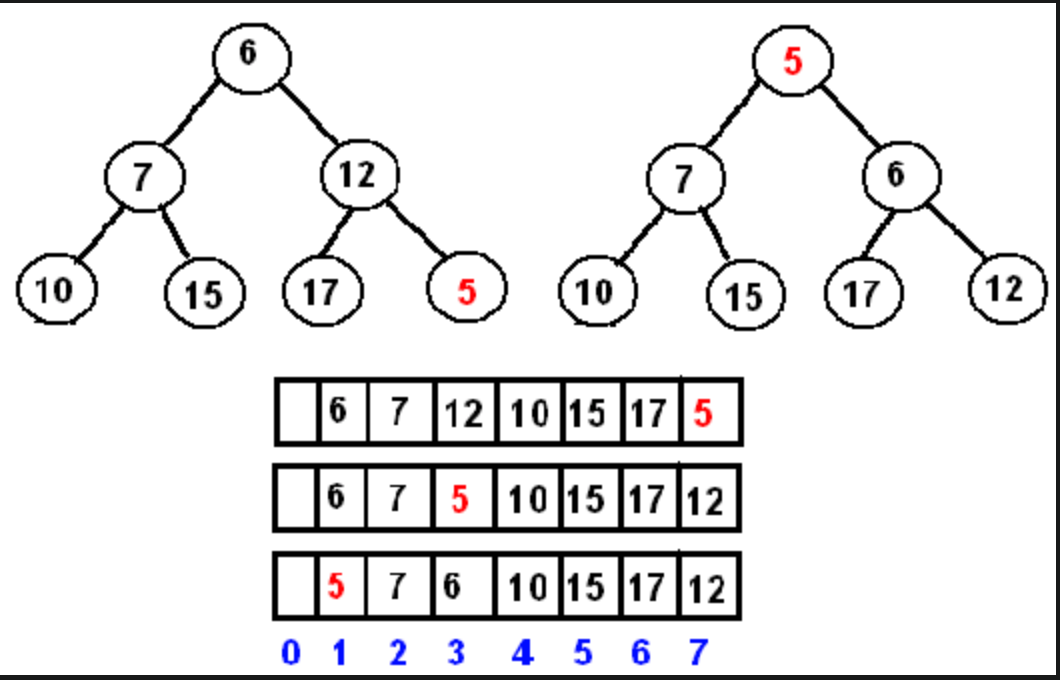
插入元素的时候会插入在最后一个.为了保证性质.用当前元素与父元素比较的方式来决定是否交换占位置(重复比较到根节点,如果需要交换位置的话).因为每个层级只需要交换一次.复杂度也就是O(logN).如图1-1所示
delete
删除节点分为三步:
- 删除的是末尾节点直接删除
- 不是末尾节点,将要删除的节点和末尾节点交换.删除末尾节点.将替换后的节点作下沉操作.
- 对于2中没有下沉操作要进行上浮操作.类似于insert.
继承关系 类成员变量
public class PriorityQueue<E> extends AbstractQueue<E>
implements java.io.Serializable
private static final int DEFAULT_INITIAL_CAPACITY = 11;
transient Object[] queue; // non-private to simplify nested class access
private int size = 0;
transient int modCount = 0;
private static final int MAX_ARRAY_SIZE = Integer.MAX_VALUE - 8;
构造函数
一共七个构造方法.前四个属于一种.后几个根据传入的集合作区分.传入的是sortSet或者PriorityQueue有序集合直接复制数据使用.如果是普通集合使用heapity()方法初始化二叉堆.
public PriorityQueue() {
this(DEFAULT_INITIAL_CAPACITY, null);
}
public PriorityQueue(int initialCapacity) {
this(initialCapacity, null);
}
public PriorityQueue(Comparator<? super E> comparator) {
this(DEFAULT_INITIAL_CAPACITY, comparator);
}
public PriorityQueue(int initialCapacity,
Comparator<? super E> comparator) {
// Note: This restriction of at least one is not actually needed,
// but continues for 1.5 compatibility
if (initialCapacity < 1)
throw new IllegalArgumentException();
this.queue = new Object[initialCapacity];
this.comparator = comparator;
}
public PriorityQueue(Collection<? extends E> c) {
if (c instanceof SortedSet<?>) {
SortedSet<? extends E> ss = (SortedSet<? extends E>) c;
this.comparator = (Comparator<? super E>) ss.comparator();
initElementsFromCollection(ss);
}
else if (c instanceof PriorityQueue<?>) {
PriorityQueue<? extends E> pq = (PriorityQueue<? extends E>) c;
this.comparator = (Comparator<? super E>) pq.comparator();
initFromPriorityQueue(pq);
}
else {
this.comparator = null;
initFromCollection(c);
}
}
public PriorityQueue(PriorityQueue<? extends E> c) {
this.comparator = (Comparator<? super E>) c.comparator();
initFromPriorityQueue(c);
}
public PriorityQueue(SortedSet<? extends E> c) {
this.comparator = (Comparator<? super E>) c.comparator();
initElementsFromCollection(c);
}
核心方法
增
public boolean offer(E e) {
if (e == null)
throw new NullPointerException();
modCount++;
int i = size;
//元素满了扩容
if (i >= queue.length)
grow(i + 1);
size = i + 1;
//如果是空的
if (i == 0)
queue[0] = e;
else
siftUp(i, e);
return true;
}
可以看以下这里是怎么扩容的.主要是大小<64 两倍扩容,超过扩容一半.扩容超过最大容量,设置为Interger.MAX.
private void grow(int minCapacity) {
int oldCapacity = queue.length;
// Double size if small; else grow by 50%
int newCapacity = oldCapacity + ((oldCapacity < 64) ?
(oldCapacity + 2) :
(oldCapacity >> 1));
// overflow-conscious code
if (newCapacity - MAX_ARRAY_SIZE > 0)
newCapacity = hugeCapacity(minCapacity);
queue = Arrays.copyOf(queue, newCapacity);
}
增加的主要方法是 根据是否有比较器有两个下面是有比较器的方法.没有比较器使用默认的比较器.思想没有什么变化.
private void siftUpUsingComparator(int k, E x) {
while (k > 0) {
//和父元素进行比较,如果大于等于父元素,符合二叉堆性质.直接插入.
如果小于父元素,和父元素交换位置.继续上浮操作.
int parent = (k - 1) >>> 1;
Object e = queue[parent];
if (comparator.compare(x, (E) e) >= 0)
break;
queue[k] = e;
k = parent;
}
queue[k] = x;
}
查
就是取最小的元素.就是根节点.
public E peek() {
return (size == 0) ? null : (E) queue[0];
}
下面是如何实现下沉操作.跟插入一样,这里选择有比较器的实现.
private void siftDownComparable(int k, E x) {
Comparable<? super E> key = (Comparable<? super E>)x;
int half = size >>> 1; // loop while a non-leaf
while (k < half) {
int child = (k << 1) + 1; // assume left child is least
Object c = queue[child];
int right = child + 1;
if (right < size &&
((Comparable<? super E>) c).compareTo((E) queue[right]) > 0)
c = queue[child = right];
if (key.compareTo((E) c) <= 0)
break;
queue[k] = c;
k = child;
}
queue[k] = key;
}
删除
private E removeAt(int i) {
// assert i >= 0 && i < size;
modCount++;
int s = --size;
//删除的是末尾
if (s == i) // removed last element
queue[i] = null;
else {
//删除末尾节点
E moved = (E) queue[s];
queue[s] = null;
//下沉操作
siftDown(i, moved);
if (queue[i] == moved) {
//没有下沉.需要进行上浮操作以免出现父节点< 父节点的父节点的情况出现.
siftUp(i, moved);
if (queue[i] != moved)
return moved;
}
}
return null;
}
下沉操作
private void siftDownUsingComparator(int k, E x) {
//完全二叉树.插入的位置超过一半.就是在树的最下方.不用在下沉了.
int half = size >>> 1;
while (k < half) {
//需要找到该位置的两个子节点.因为需要比较是否交换位置.
int child = (k << 1) + 1;
Object c = queue[child];
int right = child + 1;
//右子树小于左子树.
if (right < size &&
comparator.compare((E) c, (E) queue[right]) > 0)
c = queue[child = right];
//该节点<=子树.不用下沉了.
if (comparator.compare(x, (E) c) <= 0)
break;
//交换位置继续下沉.
queue[k] = c;
k = child;
}
queue[k] = x;
}
还有一个就是deleteMin.这里是poll方法.就是最小的元素出列.(体现优先队列,优先级最高的元素先出列),其实就是特殊的删除方法.位置是0.
public E poll() {
if (size == 0)
return null;
int s = --size;
modCount++;
//找到最小的元素
E result = (E) queue[0];
//找到末尾的元素
E x = (E) queue[s];
//删除末尾的元素
queue[s] = null;
if (s != 0)
//下沉操作
siftDown(0, x);
return result;
}
