

我们有时候可能会想知道如果将其他人的妆容放在自己脸上会是怎样。现在,不需要耗费时间学习化妆技巧以及花钱购买化妆品,借助深度生成模型,我们就能轻松尝试别人的妆容效果。
选自arXiv,作者:Wentao Jiang等,机器之心编译,参与:Panda。

妆容迁移效果图,我们希望模型能将 Reference 的化妆风格迁移到 Source 上,从而得到 Results。
在迁移学习领域,有一个任务名为妆容迁移(makeup transfer),即将任意参照图像上的妆容迁移到不带妆容的源图像上。很多人像美化应用都需要这种技术。近来的一些妆容迁移方法大都基于生成对抗网络(GAN)。它们通常采用 CycleGAN 的框架,并在两个数据集上进行训练,即无妆容图像和有妆容图像。
但是,现有的方法存在一个局限性:只在正面人脸图像上表现良好,没有为处理源图像和参照图像之间的姿态和表情差异专门设计模块。另外,它们也不能在测试阶段直接用于部分妆容迁移,因为它们无法以可感知空间的方式提取妆容特征。
为了克服这些问题以更好地服务真实世界场景,颜水成等研究者认为完美的妆容迁移模型应具备以下能力:
能够稳健地处理不同的姿态,也就是在源图像和参照图像的姿态不同时也要能生成高质量的结果,比如可以将侧脸图像上的妆容迁移到正脸图像上。
能够实现逐部分迁移的迁移过程,即可以分开迁移人脸上不同区域的妆容,比如眼影或唇彩。
能够控制妆容的浓浅程度,即可以增强或减弱被迁移妆容的效果。Chen et al. 2019 提出了将图像解构为妆容隐码(makeup latent code)和人脸隐码(face latent code)来实现对妆容浓浅程度的控制,但这项研究并未考虑其它两项需求。
针对这些需求,研究者提出了一种全新的姿态稳健型可感知空间式生成对抗网络(PSGAN)。

论文地址:https://arxiv.org/pdf/1909.06956.pdf
得益于当前风格迁移方法的发展,使用妆容矩阵,模型仅需对特征图(feature map)执行一次缩放和位移就能实现妆容迁移。但是,妆容迁移比风格迁移问题更复杂一些,这既需要考虑得到结果,也需要考虑妆容样式的细微细节。
研究者提出使用 MDNet 将参照图像的妆容提炼为两个妆容矩阵 γ 和 β,两者具有与视觉特征一样的空间维度。然后,通过 AMM 模块对 γ 和 β 进行变形处理,使其适应源图像,从而得到自适应妆容矩阵 γ' 和 β'。
这个 AMM 模块可以解决因为姿态差异而导致的不对齐问题,从而使 PSGAN 能稳健地处理不同姿态。最后,新提出的 DRNet 会首先对源图像进行卸妆,然后再在卸妆后的结果上通过逐像素加权的乘法和加法来应用矩阵 γ』 和 β』,执行再化妆(re-makeup)。
因为妆容风格是以可感知空间的方式提炼出来的,所以可以根据人脸解析的结果,通过设置逐像素运算中的权重来实现逐部分的迁移。比如在图 1 的左上图中,唇彩、皮肤和眼影都可以分别实现单独迁移。
通过将权重设置为 [0,1] 区间中的标量,可以实现对浓浅程度的控制。图 1 左下图展示了一个示例:从左到右是越来越浓的妆。PSGAN 的 AMM 模块也能够有效地解决姿态和表情差异问题。图 1 的右上图和右下图分别展示了当姿态和表情差距较大时的迁移示例。研究者认为,这三种新提出的模块能让 PSGAN 具备上述的完美妆容迁移模型所应具备的能力。

该模型可让用户控制所要迁移的浓浅程度和图像区域。
该研究的贡献如下:
PSGAN 是首个能同时实现逐部分迁移、浓浅程度可控迁移和姿势稳健型迁移的基于 GAN 的方法。
新提出的 AMM 模块可以调整从参照图像提取出的妆容矩阵,使其适应源图像。这个模块让 PSGAN 有能力在姿态不同的图像之间迁移妆容风格。
研究者进行了广泛的定性和定量实验,结果表明 PSGAN 是有效的。
模型架构是什么
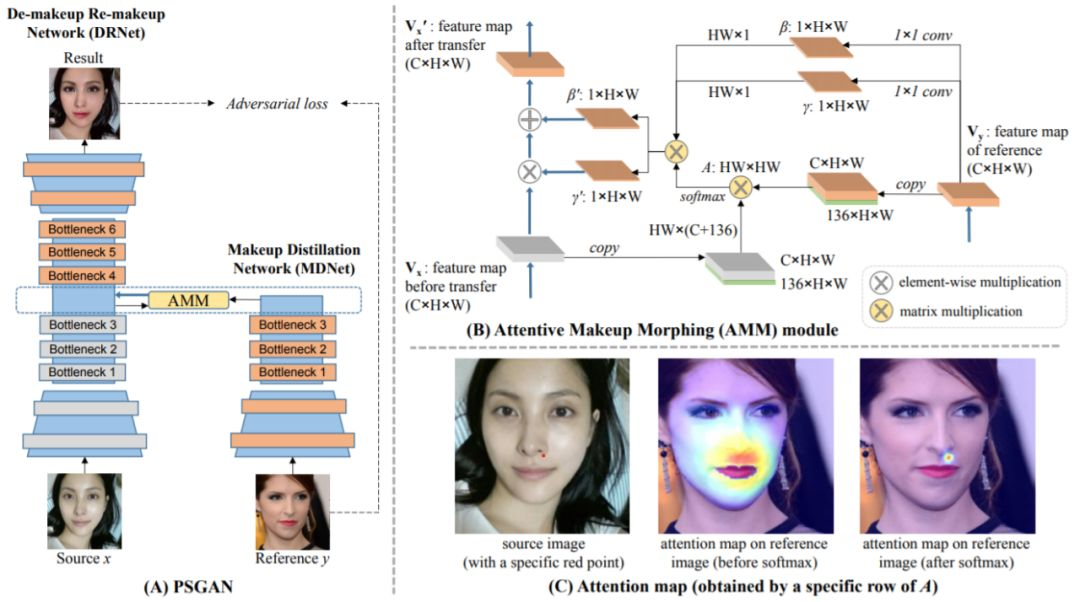
对于 PSGAN 框架,首先,DRNet 对源图像执行卸妆操作,MDNet 则从参照图像提炼妆容矩阵。AMM 模块将提炼出来的矩阵应用于 DRNet 的第三个瓶颈的输出特征图,以实现妆容迁移。
对于 AMM 模块,具有 136(68×2)个通道的绿色模块表示像素的相对位置向量,然后再与 C 通道视觉特征相连接。由此,可通过相对位置与视觉特征的相似度为源图像中的每个像素计算出注意图(attentive map)。AMM 模块得到自适应妆容矩阵 γ』 和 β』,然后再逐元素地乘和加为 DRNet 的特征图。图中的橙色和灰色模块分别表示有妆容和无妆容的特征。
最后对于注意力图,注意这里仅计算了属于同样面部区域的像素的注意值。因此,在参照图像的唇部和眼部上没有响应值。
MDNet 采用了(Choi et al. 2017; Li et al. 2018)中使用的「编码器-瓶颈」架构,没有解码器部分。它可从内在的面部特征(如人脸形状、眼睛大小)解离出与妆容有关的特征(如唇彩、眼影)。与妆容相关的特征被表示为两个妆容矩阵 γ 和 β,它们再被用于通过像素级的操作实现妆容迁移。如图 2(B) 所示,参照图像的特征图被馈送给两个 1×1 卷积层,得到 γ 和 β。
由于源图像和参照图像之间可能存在姿态和表情的差异,所以得到的感知空间型 γ 和 β 无法直接应用于源图像。AMM 模块会计算出一个注意矩阵 A,指示了源图像中像素相对于参照图像中像素的变形情况。
DRNet 使用了与(Choi et al. 2017; Li et al. 2018)类似的「编码器-瓶颈-解码器」架构。如图 2(A) 所示,DRNet 的编码器部分与 MDNet 一样,但它们的参数并不一样,因为它们的函数不同。编码器部分使用了没有仿射(affine)参数的实例归一化,从而使特征图呈正态分布,这可被视为卸妆过程。
PSGAN 使用了多种目标函数:
判别器的对抗损失(adversarial loss)和生成器的对抗损失;
循环一致性损失(cycle consistency loss),由 Zhu et al. 2017 提出,这里使用了 L1 损失来约束重建的图像和定义循环一致性损失;
感知损失(perceptual loss),使用 L2 损失来衡量迁移后的图像与源图像的个人身份差异。研究者使用了一个在 ImageNet 上预训练的 VGG-16 模型来比较源图像和生成图像在隐藏层中的激活;
妆容损失(makeup loss),由 Li et al. 2018 提出,能为妆容迁移提供粗略的引导;
总损失(total loss),以上各个损失的加权和。
研究者使用了 MT(Makeup Transfer)数据集(Li et al. 2018; Chen et al. 2019)来训练和测试网络。其中包含 1115 张源图像和 2719 张参照图像。
对照实验
图 3 展示了 AMM 模块的有效性。

图 4 表明,仅考虑相对位置不足以实现良好的妆容矩阵变形。如果仅考虑相对位置,那么中间的注意图就类似于一个 2D 高斯分布。

部分化妆和插值化妆
因为妆容矩阵 γ 和 β 是空间感知型矩阵,所以可以在测试中实现部分迁移和插值迁移。为了生成部分妆容,研究者使用了人脸解析结果来加权这两个矩阵,从而计算出新的妆容矩阵。
图 6 展示了部分地混合两张参照图像的妆容风格的结果。第三列的结果组合了参照图像 1 的唇妆和参照图像 2 的其它部分,看起来很自然,具有真实感。这种部分化妆的新功能让 PSGAN 能实现定制化妆容迁移。

此外,还可以通过系数 α∈[0,1] 实现两张参照图像的插值操作。图 5 展示了使用一或两张参照图像的插值妆容迁移结果。通过将新的妆容张量馈送给 DRNet,研究者实现了两张参照图像的妆容风格之间的平滑过渡。生成结果表明,PSGAN 不仅能控制妆容迁移的浓浅程度,还能通过混合两种妆容风格的妆容张量来生成新的妆容风格。这能显著扩展妆容迁移的应用范围。

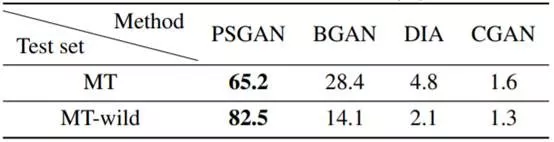
定量比较
研究者还在 Amazon Mechanical Turk(AMT)上执行了用户研究,定量地比较了 PSGAN 与 BGAN(BeautyGAN)(Li et al. 2018)、CGAN(CycleGAN)(Zhu et al. 2017)、DIA(Liao et al. 2017)的结果。
定性比较


