

1.bitmap简介
1.1redis 位图
位图不是真正的数据类型,而是定义在String类型上的一个面向字节操作的集合。字符串类型是二进制安全的二进制大对象,一个字符串类型的值最多能存储512M字节的内容。
位上限:2^(9+10+10+3)=2^32b
1.2redis bitmap
bitMap 就是通过一个 bit位来表示某个元素对应的值或者状态,其中的key就是对应元素本身,实际上底层也是通过对字符串的操作来实现。
Redis允许使用二进制数据的Key(binary keys) 和二进制数据的Value(binary values)。Bitmap就是二进制数据的value,为一连串2进制数字(0,1),每一位就是偏移(offset)。
Redis命令
-
setbit(key, offset, value)
操作对指定的key的value的指定偏移(offset)的位置1或0,时间复杂度是O(1)。返回值 0或1,为操作之前改offset位的比特值;
-
getbit(key,offset)
获取key对应offset的bit值。
-
bitcount(key[start end])
统计字符串(字节)被设置为1的bit数
-
bitop(and|or|not|xor destkey key [key...])
多个bitmap做and(交集)、or(并集)、not(非)、xor(异或)操作并将结果保存到destkey中。
2.应用
bitmap优势:基于bit进行存储,在一定情况下能够节省大量存储空间
2.1 数据存储统计
bitmap的value是一串2进制数字(例:10010011),而0和1完全可以表示某些数据的状态或值。
场景1:用户的日活,签到
以时间为key,用户的id对应到value上的一位,记录当天是否登录。今天uid为2和5的用户进行登录,其余未登录。
setbit today 10000000 0
setbit today 2 1
setbit today 5 1
或者可以以用户的uid为key,以时间为value,统计连续一段时间内登录的天数。
-
备注1:uid如何映射到位图的某一位置,可以做一个uid和正数序列的对应关系,并存储起来,在其他场景下,同样可以进行复用。
-
备注2:数据量足够大(百万级别)时,使用Redis bitmap可以提高效率,数据量较小时可以直接使用set集合
场景2:热门音乐,文章用户的阅读,分享
原理与场景1相同,以文章为key,每有一位用户阅读分享,就将相应位图中相应的位置setbit为1。这样方便统计文章的阅读数,通过bitop操作还可以统计出多篇文章公共用户有哪些等。
问题
Redis 的位图是密集位图,如果有一个很大的位图,它只有最后一个位是1,其它都是0,这个位图还是会占用全部的内存空间。
这时引出另一个解决方案————咆哮位图(RoaringBitmap)
它将整个大位图进行了分块,如果整个块都是零,那么这整个块就不用存了。但是如果位1比较分散,每个块里面都有1,我们可以只存储所有为1的块内偏移量(整数),也就是存一个整数列表,那么块内的存储也可以降下来。这就是单个块位图的稀疏存储形式 —— 存储偏移量整数列表。只有单块内的位1超过了一个阈值,才会一次性将稀疏存储转换为密集存储。
咆哮位图除了可以大幅节约空间之外,还会降低AND、OR等位运算的计算效率。以前需要计算整个位图,现在只需要计算部分块。如果块内非常稀疏,那么只需要对这些小整数列表进行集合的 AND、OR 运算,如是计算量还能继续减轻。
本段部分内容来自《Redis精确去重计数——咆哮位图》链接:juejin.cn/post/684490…
2.2 布隆过滤(BloomFilter)
百度百科
布隆过滤器(Bloom Filter)是1970年由布隆提出的。它实际上是一个很长的二进制向量和一系列随机映射函数。布隆过滤器可以用于检索一个元素是否在一个集合中。它的优点是空间效率和查询时间都比一般的算法要好的多,缺点是有一定的误识别率和删除困难。
-
场景
缓存击穿,拦截请求防止穿库;爬虫,url判重。。。
大都数情况是建立一个大数据量的黑名单,高效判重。 -
需求
判断一个集合中是否存在某个元素。
-
解决方案
平常使用的线性表存储,平衡BST,哈希表存储随着数据量的增加,效率会变得非常慢,并且占用空间也是一个问题。
布隆过滤器则是使用比特的位数组来作为元素集合,并不存储元素本身,当要插入一个元素时,将其数据分别输入k个哈希函数,产生k个哈希值。以哈希值作为位数组中的下标,将所有k个对应的比特置为1。当要查询(即判断是否存在)一个元素时,同样将其数据输入哈希函数,然后检查对应的k个比特。如果有任意一个比特为0,表明该元素一定不在集合中。如果所有比特均为1,表明该集合有(较大的)可能性在集合中。
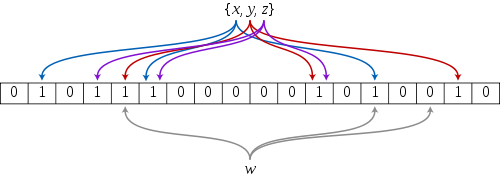
布隆过滤器判断某个元素不在集合中,则肯定不存在。
布隆过滤器判断某个元素在集合中,这个元素有可能不在(元素k次哈希值受影响)
-
实现
S集合中有n个元素,利用k个哈希函数,将S中的每个元素映射到一个长度为m的位(bit)数组B中不同的位置上。在构造一个布隆过滤器时,需要传入两个参数,即可以接受的误判率fpp和元素总个数n。
来看一个java Guava对布隆过滤的实现com.google.common.hash.BloomFilter
BloomFilter类的成员属性
/**
* 数组B
*/
private final BitArray bits;
/**
* 哈希函数个数k
*/
private final int numHashFunctions;
/**
* 把任意类型的数据转化成Java基本数据类型
*/
private final Funnel<? super T> funnel;
/**
* 定义在BloomFilter类内部的接口
*/
private final BloomFilter.Strategy strategy;
BloomFilter并没有公有的构造函数,只有一个私有构造函数,而对外它提供了5个重载的create方法,在缺省情况下误判率设定为3%,采用BloomFilterStrategies.MURMUR128_MITZ_64的实现。其中4个create方法最终都调用了同一个create方法,由它来负责调用私有构造函数,其源码如下:
static <T> BloomFilter<T> create(Funnel<? super T> funnel, long expectedInsertions, double fpp, BloomFilter.Strategy strategy) {
Preconditions.checkNotNull(funnel);
Preconditions.checkArgument(expectedInsertions >= 0L, "Expected insertions (%s) must be >= 0", new Object[]{expectedInsertions});
Preconditions.checkArgument(fpp > 0.0D, "False positive probability (%s) must be > 0.0", new Object[]{fpp});
Preconditions.checkArgument(fpp < 1.0D, "False positive probability (%s) must be < 1.0", new Object[]{fpp});
Preconditions.checkNotNull(strategy);
if (expectedInsertions == 0L) {
expectedInsertions = 1L;
}
long numBits = optimalNumOfBits(expectedInsertions, fpp);
int numHashFunctions = optimalNumOfHashFunctions(expectedInsertions, numBits);
try {
return new BloomFilter(new BitArray(numBits), numHashFunctions, funnel, strategy);
} catch (IllegalArgumentException var10) {
throw new IllegalArgumentException("Could not create BloomFilter of " + numBits + " bits", var10);
}
}
@VisibleForTesting
static int optimalNumOfHashFunctions(long n, long m) {
return Math.max(1, (int)Math.round((double)m / (double)n * Math.log(2.0D)));
}
@VisibleForTesting
static long optimalNumOfBits(long n, double p) {
if (p == 0.0D) {
p = 4.9E-324D;
}
return (long)((double)(-n) * Math.log(p) / (Math.log(2.0D) * Math.log(2.0D)));
}
Guava封装了一个long型的数组作为BitArray,另外还有一个long型整数,用来统计数组中已经占用(置为1)的数量。
在第一个构造函数中,它把传入的long型整数按长度64分段,段数作为数组的长度。
static final class BitArray {
final long[] data;
long bitCount;
BitArray(long bits) {
this(new long[Ints.checkedCast(LongMath.divide(bits, 64L, RoundingMode.CEILING))]);
}
BitArray(long[] data) {
Preconditions.checkArgument(data.length > 0, "data length is zero!");
this.data = data;
long bitCount = 0L;
long[] arr$ = data;
int len$ = data.length;
for(int i$ = 0; i$ < len$; ++i$) {
long value = arr$[i$];
bitCount += (long)Long.bitCount(value);
}
this.bitCount = bitCount;
}
boolean set(long index) {
if (!this.get(index)) {
long[] var10000 = this.data;
var10000[(int)(index >>> 6)] |= 1L << (int)index;
++this.bitCount;
return true;
} else {
return false;
}
}
boolean get(long index) {
return (this.data[(int)(index >>> 6)] & 1L << (int)index) != 0L;
}
long bitSize() {
return (long)this.data.length * 64L;
}
long bitCount() {
return this.bitCount;
}
BloomFilterStrategies.BitArray copy() {
return new BloomFilterStrategies.BitArray((long[])this.data.clone());
}
void putAll(BloomFilterStrategies.BitArray array) {
Preconditions.checkArgument(this.data.length == array.data.length, "BitArrays must be of equal length (%s != %s)", new Object[]{this.data.length, array.data.length});
this.bitCount = 0L;
for(int i = 0; i < this.data.length; ++i) {
long[] var10000 = this.data;
var10000[i] |= array.data[i];
this.bitCount += (long)Long.bitCount(this.data[i]);
}
}
public boolean equals(Object o) {
if (o instanceof BloomFilterStrategies.BitArray) {
BloomFilterStrategies.BitArray bitArray = (BloomFilterStrategies.BitArray)o;
return Arrays.equals(this.data, bitArray.data);
} else {
return false;
}
}
public int hashCode() {
return Arrays.hashCode(this.data);
}
}
Guava是在内存中操作,Redis可以在多个服务中使用(具体实现可以查阅相关资料)。
-
布隆过滤的优缺点
优点:数据占用空间小,时间效率也较高,插入和查询的时间复杂度均为O(k);
缺点:
- 有一定误差,随着数据量增加,误差逐渐增大。
- 元素只能添加,不能删除。
-
进阶(下次再看)
布隆过滤器参数推导
布谷鸟过滤器
计数过滤器
