

网上已经有很多的过滤敏感词算法:Java实现敏感词过滤算法,一开始看代码的时候还是困惑的,这里简单记录下剖析代码思路
- 创建敏感词库过程如下:
/**
* 初始化敏感词库,构建DFA算法模型
*
* @param sensitiveWordSet 敏感词库
*/
private static void initSensitiveWordMap(Set<String> sensitiveWordSet) {
//初始化敏感词容器,减少扩容操作
sensitiveWordMap = new HashMap(sensitiveWordSet.size());
String key;
Map nowMap;
Map<String, String> newWorMap;
//迭代sensitiveWordSet
Iterator<String> iterator = sensitiveWordSet.iterator();
while (iterator.hasNext()) {
//关键字
key = iterator.next();
nowMap = sensitiveWordMap;
for (int i = 0; i < key.length(); i++) {
//转换成char型
char keyChar = key.charAt(i);
//库中获取关键字
Object wordMap = nowMap.get(keyChar);
//如果存在该key,直接赋值,用于下一个循环获取
if (wordMap != null) {
nowMap = (Map) wordMap;
} else {
//不存在则,则构建一个map,同时将isEnd设置为0,因为他不是最后一个
newWorMap = new HashMap<String, String>();
//不是最后一个
newWorMap.put("isEnd", "0");
nowMap.put(keyChar, newWorMap);
nowMap = newWorMap;
}
if (i == key.length() - 1) {
//最后一个
nowMap.put("isEnd", "1");
}
}
}
}

- sensitiveWordMap 和 nowMap 指向同一个对象,nowMap 而后改成指向与 newWordMap1 同一个对象
- sensitiveWordMap 主要通过 newWordMap1 引用的对象更新而进行更新
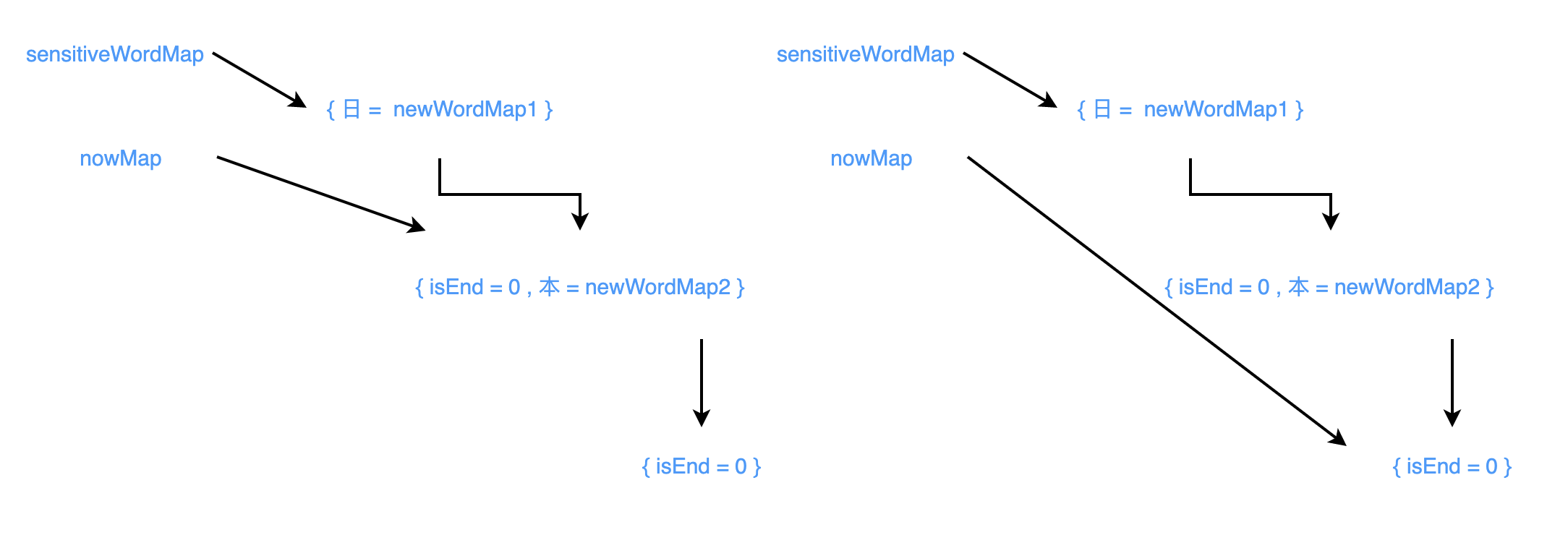
- nowMap newWordMap1 引用的对象通过 nowMap 进行更新,nowMap 而后改成指向与 newWordMap2 同一个对象
- 后续都是通过 newMap 更新,以此类推
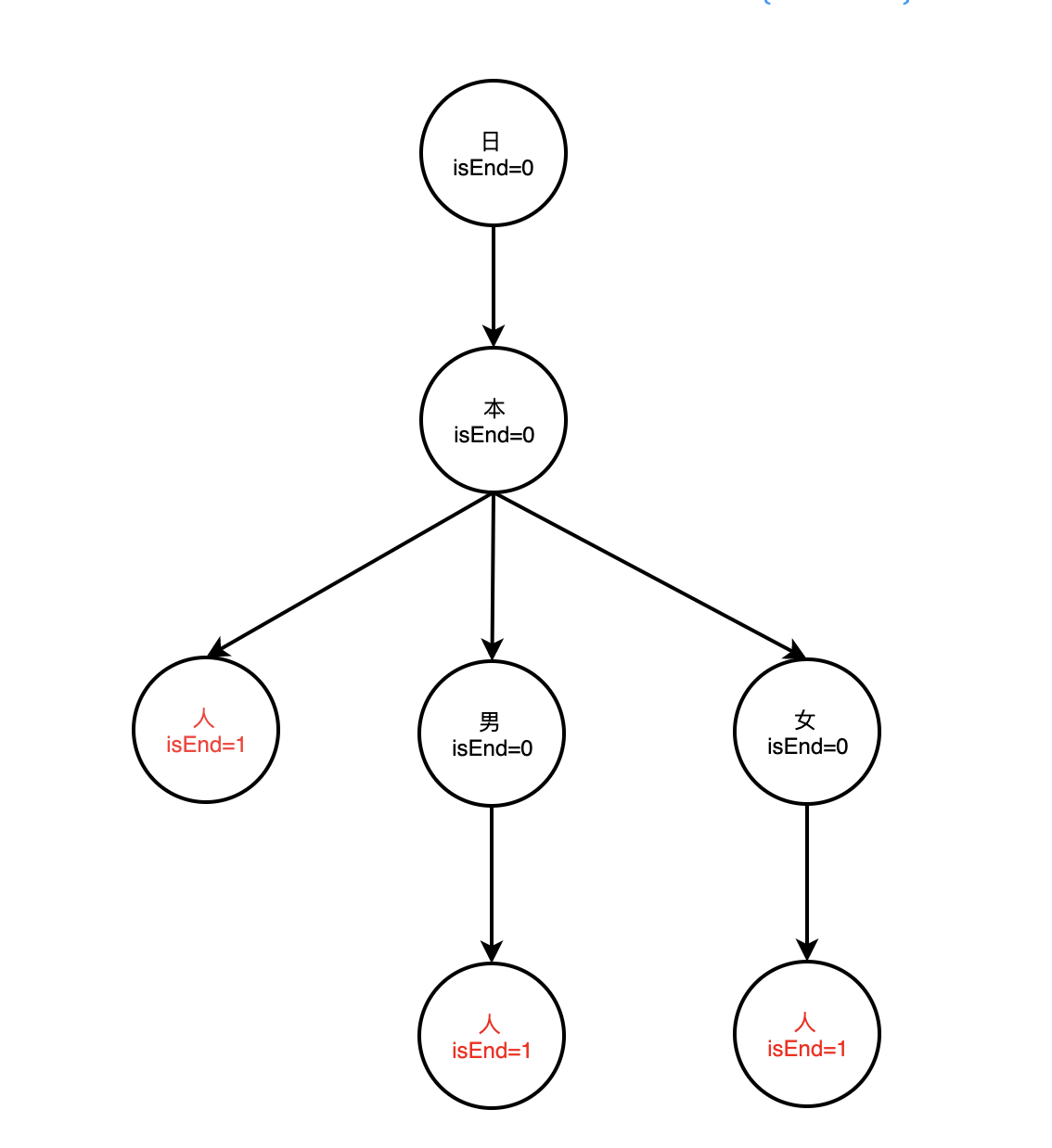
- 像日本人、日本男人、日本女人这三个敏感词最终是形成这样一棵树
- { 日 = { isEnd=0, 本 = { isEnd = 0, 人 = { isEnd = 1 }, 男 = {isEnd = 0, 人 = { isEnd = 1 } }, 女 = {isEnd = 0, 人 = { isEnd = 1 } } } } }
- 检索是否包含敏感词:
- 判断 “日本”是否是敏感词,检索到本,由于 isEnd=0 所以 日本不是敏感词
- 像敏感词为“特殊商品”、则“商品”不为敏感词。因为没有以“商”开头的树能用来检索
- 像判断“中国人和日本人”中是否包含敏感词,从代码中可以看出是遍历每一个char,去判断是否匹配敏感词库。
- 贴全部代码:
public class SensitiveWordUtil {
/**
* 敏感词匹配规则
*/
private static final int MinMatchTYpe = 1; //最小匹配规则,如:敏感词库["中国","中国人"],语句:"我是中国人",匹配结果:我是[中国]人
private static final int MaxMatchType = 2; //最大匹配规则,如:敏感词库["中国","中国人"],语句:"我是中国人",匹配结果:我是[中国人]
private static final char maskChar = '*'; // 掩码
/**
* 敏感词集合
*/
private static HashMap sensitiveWordMap;
/**
* 初始化敏感词库,构建DFA算法模型
*
* @param sensitiveWordSet 敏感词库
*/
public static synchronized void init(Set<String> sensitiveWordSet) {
initSensitiveWordMap(sensitiveWordSet);
}
/**
* 打印sensitiveWordMap
*/
public static void printMap(){
Log.i("MainActivity",sensitiveWordMap.toString());
}
/**
* 初始化敏感词库,构建DFA算法模型
*
* @param sensitiveWordSet 敏感词库
*/
private static void initSensitiveWordMap(Set<String> sensitiveWordSet) {
//初始化敏感词容器,减少扩容操作
sensitiveWordMap = new HashMap(sensitiveWordSet.size());
String key;
Map nowMap;
Map<String, String> newWorMap;
//迭代sensitiveWordSet
Iterator<String> iterator = sensitiveWordSet.iterator();
while (iterator.hasNext()) {
//关键字
key = iterator.next();
nowMap = sensitiveWordMap;
for (int i = 0; i < key.length(); i++) {
//转换成char型
char keyChar = key.charAt(i);
//库中获取关键字
Object wordMap = nowMap.get(keyChar);
//如果存在该key,直接赋值,用于下一个循环获取
if (wordMap != null) {
nowMap = (Map) wordMap;
} else {
//不存在则,则构建一个map,同时将isEnd设置为0,因为他不是最后一个
newWorMap = new HashMap<String, String>();
//不是最后一个
newWorMap.put("isEnd", "0");
nowMap.put(keyChar, newWorMap);
nowMap = newWorMap;
}
if (i == key.length() - 1) {
//最后一个
nowMap.put("isEnd", "1");
}
}
}
}
/**
* 判断文字是否包含敏感字符
*
* @param txt 文字
* @param matchType 匹配规则 1:最小匹配规则,2:最大匹配规则
* @return 若包含返回true,否则返回false
*/
public static boolean contains(String txt, int matchType ,HashSet<String> hashSet) {
if(sensitiveWordMap == null){
// LogUtil.i(BaiduRecognizeManager.TAG,"敏感词库尚未初始化");
initSensitiveWordMap(hashSet);
}
boolean flag = false;
for (int i = 0; i < txt.length(); i++) {
int matchFlag = checkSensitiveWord(txt, i, matchType); //判断是否包含敏感字符
if (matchFlag > 0) { //大于0存在,返回true
flag = true;
}
}
return flag;
}
/**
* 判断文字是否包含敏感字符
*
* @param txt 文字
* @return 若包含返回true,否则返回false
*/
public static boolean contains(String txt) {
return contains(txt, MaxMatchType,null);
}
/**
* 获取文字中的敏感词
*
* @param txt 文字
* @param matchType 匹配规则 1:最小匹配规则,2:最大匹配规则
*/
public static Set<String> getSensitiveWord(String txt, int matchType) {
Set<String> sensitiveWordList = new HashSet<String>();
for (int i = 0; i < txt.length(); i++) {
//判断是否包含敏感字符
int length = checkSensitiveWord(txt, i, matchType);
if (length > 0) {//存在,加入list中
sensitiveWordList.add(txt.substring(i, i + length));
i = i + length - 1;//减1的原因,是因为for会自增
}
}
return sensitiveWordList;
}
/**
* 获取文字中的敏感词
*
* @param txt 文字
*/
public static Set<String> getSensitiveWord(String txt) {
return getSensitiveWord(txt, MaxMatchType);
}
/**
* 替换敏感字字符
*
* @param txt 文本
* @param replaceChar 替换的字符,匹配的敏感词以字符逐个替换,如 语句:我爱中国人 敏感词:中国人,替换字符:*, 替换结果:我爱***
* @param matchType 敏感词匹配规则
*/
public static String replaceSensitiveWord(String txt, char replaceChar, int matchType) {
String resultTxt = txt;
//获取所有的敏感词
Set<String> set = getSensitiveWord(txt, matchType);
Iterator<String> iterator = set.iterator();
String word;
String replaceString;
while (iterator.hasNext()) {
word = iterator.next();
replaceString = getReplaceChars(replaceChar, word.length());
resultTxt = resultTxt.replaceAll(word, replaceString);
}
return resultTxt;
}
/**
* 替换敏感字字符
*
* @param txt 文本
* @param replaceChar 替换的字符,匹配的敏感词以字符逐个替换,如 语句:我爱中国人 敏感词:中国人,替换字符:*, 替换结果:我爱***
*/
public static String replaceSensitiveWord(String txt, char replaceChar) {
return replaceSensitiveWord(txt, replaceChar, MaxMatchType);
}
/**
* 替换敏感字字符
*
* @param txt 文本
* @param matchType 敏感词匹配规则
*/
public static String replaceSensitiveWord(String txt, int matchType) {
String resultTxt = txt;
//获取所有的敏感词
Set<String> set = getSensitiveWord(txt, matchType);
Iterator<String> iterator = set.iterator();
String word;
while (iterator.hasNext()) {
word = iterator.next();
resultTxt = resultTxt.replaceAll(word, getReplaceChars(maskChar, word.length()));
}
return resultTxt;
}
/**
* 获取替换字符串
*/
private static String getReplaceChars(char replaceChar, int length) {
StringBuilder resultReplace = new StringBuilder(String.valueOf(replaceChar));
for (int i = 1; i < length; i++) {
resultReplace.append(replaceChar);
}
return resultReplace.toString();
}
/**
* 检查文字中是否包含敏感字符,检查规则如下:<br>
*
* @return 如果存在,则返回敏感词字符的长度,不存在返回0
*/
private static int checkSensitiveWord(String txt, int beginIndex, int matchType) {
//敏感词结束标识位:用于敏感词只有1位的情况
boolean flag = false;
//匹配标识数默认为0
int matchFlag = 0;
char word;
Map nowMap = sensitiveWordMap;
for (int i = beginIndex; i < txt.length(); i++) {
word = txt.charAt(i);
//获取指定key
nowMap = (Map) nowMap.get(word);
if (nowMap != null) {//存在,则判断是否为最后一个
//找到相应key,匹配标识+1
matchFlag++;
//如果为最后一个匹配规则,结束循环,返回匹配标识数
if ("1".equals(nowMap.get("isEnd"))) {
//结束标志位为true
flag = true;
//最小规则,直接返回,最大规则还需继续查找
if (MinMatchTYpe == matchType) {
break;
}
}
} else {//不存在,直接返回
break;
}
}
if (matchFlag < 2 || !flag) {//长度必须大于等于1,为词
matchFlag = 0;
}
return matchFlag;
}
}
使用的话如下:
public class MainActivity extends AppCompatActivity {
@Override
protected void onCreate(Bundle savedInstanceState) {
super.onCreate(savedInstanceState);
setContentView(R.layout.activity_main);
HashSet<String> strings = new HashSet<>();
strings.add("中国人");
strings.add("日本男人");
strings.add("日本女人");
strings.add("日本");
strings.add("日本人");
SensitiveWordUtil.init(strings);
SensitiveWordUtil.printMap();
Set<String> set = SensitiveWordUtil.getSensitiveWord("中国人不是日本人");
Log.i("MainActivity","包含的敏感词有:"+set);
}
}
