

CrossEntropyLoss和NLLLoss和KLDivLoss
看名字可能感觉这三个Loss不搭嘎。
NLLLoss的全称是Negative Log Likelihood Loss,中文名称是最大似然或者log似然代价函数。
CrossEntropyLoss是交叉熵代价函数。
KLDivLoss是Kullback-Leibler divergence Loss。
NLLLoss
似然函数是什么呢?
似然函数就是我们有一堆观察所得得结果,然后我们用这堆观察结果对模型的参数进行估计。 举个例子,一个硬币,它有θ的概率会正面向上,有1-θ的概率反面向上。但是我们不知道θ是多少,这个θ就是模型的参数。
我们为了获得θ的值,我们抛了十次,得到一个序列x=正正反反正反正正正正,获得这个序列的概率是θ⋅θ⋅(1-θ)⋅(1-θ)⋅θ⋅(1-θ)⋅θ⋅θ⋅θ⋅θ = θ⁷ (1-θ)³,我们尝试所有θ可能的值,绘制了一个图(θ的似然函数)
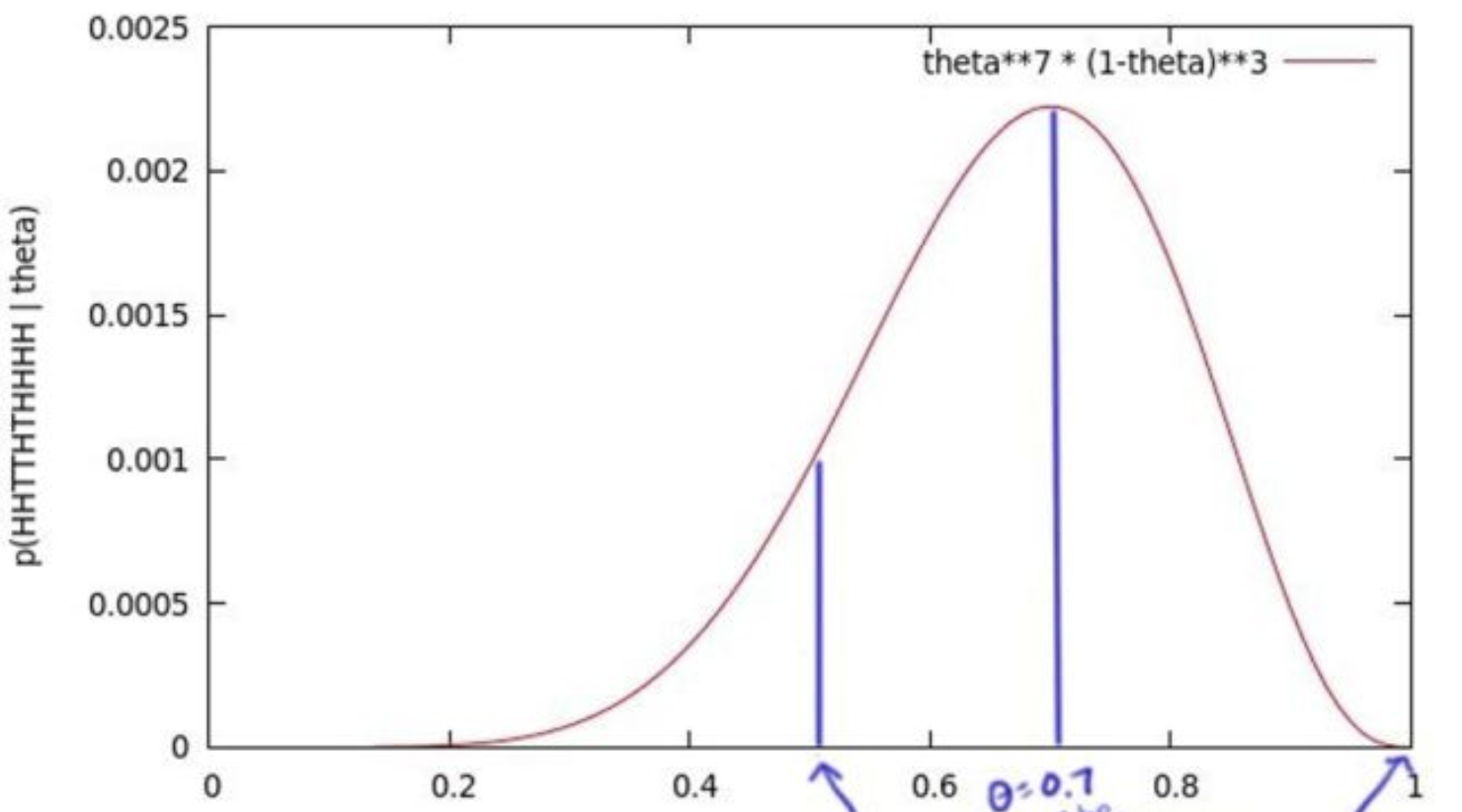
似然函数用于模型的损失函数?
如果似然函数用于模型的损失函数,那么情况又是如何的呢?
损失函数的用途是衡量当前参数下模型的预测值和真实label的差距。似然函数损失函数当然也是如此。
什么时候使用?
- 分类
- 更快的训练
- 简单的任务
此时的观察值就是每次模型的预测值,而参数不是模型的参数,而是真实的label。
聪明的你可能已经想到了,这里少了一个东西,就上面的例子来说,我们知道抛硬币是一个贝努利分布,这样我们得到一组观察值就能构建似然函数,求出参数值。但我们怎么知道真实label的分布是一个什么分布呢?
对于分类任务来讲,label的分布式其实就是贝努利分布!(或者贝努利分布的推广,多项式分布)
看一下贝努利分布,体会一下其实就是后面的分段函数。
拓展为多项式分布,即是:
更加一般的,例如p=[0.1, 0.1, 0.7, 0.1],x=[0,0,1,0]
当p=x的时候,得到最大值1。
我们的目标就是最大化似然函数了,也就是最小化负的似然函数。
而通常来说,对于累乘的结构,我们都要对数化,变成累加的形式好计算。
最后我们的loss function结构就是:
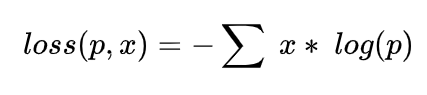
CrossEntropyLoss
其实看完log似然损失函数,会发现这玩意的形式怎么和交叉熵的形式一摸一样。
是的,交叉熵是直接用交叉熵公式去评估两个分布之间的差异,和log似然殊途同归,同貌不同源。
在数学中同样的事情还有很多,融会贯通之后会发现,很多常用的公式有着很多联系。
另外需要注意的是,在PyTorch中,CrossEntropyLoss其实是LogSoftMax和NLLLoss的合体,也就是所有的loss都会先经历一次log SoftMax之后再进入交叉熵公式。
什么时候使用?
- 分类任务
- 向更高精度和召回值优化
KLDivLoss
KLDiv Loss的全称是Kullback-Leibler divergence,它也叫做相对熵。
看名字就知道它和交叉熵都是熵的计算,有一定联系,我们看一下它的公式:
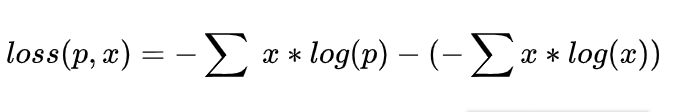
可以看到相对熵就是交叉熵减去

- 信息熵是该label完美编码所需的信息量
- 交叉熵是该label不完美编码(用观察值编码所需的信息量)
- 相对熵是交叉熵和信息熵的差值,也就是所需额外的信息量。
什么时候使用?
- 分类任务
- 和交叉熵计算差不多,通常使用交叉熵
另外,这三个loss function都可以传入weight参数,这个weight会进入loss的计算过程中,weight比较大的label会在loss function中有较大的权重,如果你的训练样本很不均衡的话,是非常有用的。
