

组件化是什么?
我觉得这个问题不用纠结拿到一个十分明确的答案,每个人的理解都不一样,我的理解是做到做好各模块间的解耦调用就好了。
思路推导
项目组成:各个module、本地依赖、远程依赖
目标达成:解耦、调用
操作手段:规划职责、抽取代码
第一步:按照上面的想法,这时我们得到了一些module,它们每个都有清晰的作用,高内聚低耦合,现在还需要做什么?对,剩下就是使用它们了,使用必定会有依赖关系,依赖链的建立就会看出层级,不同的层级会有一堆不同作用的模块。
第一个概念:组件化有层级特征
第二步:上面提到了高内聚低耦合,其实想要达到自身是一个完整的个体很难,低耦合不可避免的是组件间会有通信需求或者静态依赖。
第二个概念:组件间的通信和静态依赖也会造成耦合
如何解耦?
概念一说明有层级关系,那静态依赖的组件应该是处于更底层的,这种耦合是不可能消除的,但是我们可以收敛它们。这里建议把项目里的一些base类、工具类、自定义视图等收敛到一个组件里供上层组件依赖调用。
概念二里说明了通信依赖,那什么是通信依赖呢?举个例子,组件A需要使用到组件B的某些功能,这里你不能直接依赖B去调用了,因为划分了组件层级就是要避免同级组件相互调用造成高耦合。
在我们思考解决办法前,先考虑另外一个问题,低耦合的好处是什么?便于维护?有利于并行开发?更好定位问题?这些都是。
但是如果把时期挪到程序运行时,还是那么需要解耦吗?就上面的例子来说,在运行时A直接调用B的实现是完全可行的。只要你能做到这一点就可以。
先想一个最简单的办法,定义一个中间接口来中转,A依赖接口使用,B实现接口注入,解决掉了静态依赖,耦合还存在,为什么还存在?因为对接口的耦合也叫耦合,这里如果接口改变了,你使用的地方也要变,这对于开发期来说也是需要避免的,说到这里我引申出另外一个概念,积木架构。
积木架构:每个组件都应该是内部自我满足的完整生态,如果达不到,就应该告诉外界自己需要什么,同时也应该展示自己有什么,就像搭积木一样,有的积木是没有凹凸的,有的凹有的凸,而搭积木的人就是全局的组件协调者。
不同于传统的协议调用,引入了形态,这里我们把形态凹面比作in,凸面比作out,因为这些都包含在组件内部,所以最大化的隔绝了外部环境改变带来的影响,同时也满足了内部的自行运转。还是用上面的例子来说明:
A需要一个net,A定义自己的in,in里有一个接口String net(String url, String... args),A使用in。
全局协调者(主module或者是壳module)实现注入in的net接口,里面的调用转接到B的out里的net功能。
B的net版本修改只影响到了协调者实现注入,并没有影响到A具体使用的地方。
对于全局协调者,它需要依赖所有的组件来完成桥接,这本身就是说的通的。这里可能有人会有疑问,可以不需要这个协调者,相当于是传统的协议调用外面封装了一层中转,确实是这么回事,那为什么需要这个角色呢?我们思考一个事尽量跳出当前的环境去看,你的app可能日活几十几百万,很不错,如果是几千万或者几亿呢,这样的航母,可能里面的一个子业务都是极其复杂的,需要一个专门的团队来开发维护,这样的子业务会很多,难道要揉在一起开发调试吗?不可能的,每个子业务在开发期都是独立的,意味着你是不能通过中转接口来调用了,你可能都不知道其他子业务的存在。你只能向协调者索要。
那么协调者的作用就十分明确了,负责把各组件的凹面填充好并放置到公共中转区。
如果有专人来做这件事是可以的,但是能自动就更好了。
假设我们有一组标准协议,在组装时根据这个协议来完成组装就好了,非常容易想到的就是编译时注解处理。可惜这里不能用apt,因为组件以aar提供,为什么要以aar来提供呢,因为每个子业务可能都是有复杂的架构,那么可能会影响到整体编译时的处理,比如混淆和gradle插件,再者参与构建的project过多的话耗时也是很长的,要处理这些问题最好的方式就是隔离它们,让子业务以aar的方式提供,而apt是针对源文件的处理。那就只能使用transform了,这里我们需要完成3步:
1. 获取所有的class,因为就一个module project,所以天然可以拿到所有。
2. 使用字节码工具asm等解析class结构,统计出所有标准协议信息。
3. 根据这些信息构建凹面填充。
构建时的临时工程结构类似这样:
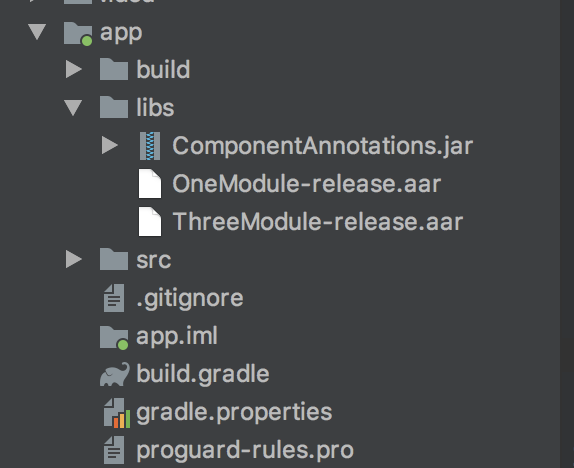
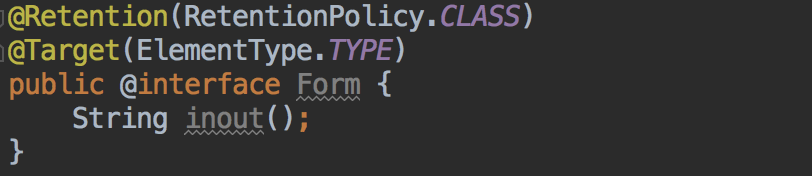
其中OneModule、ThreeModule就是子业务,这里只是方便放到了libs下,正常应该是从远程maven拉取,ComponentAnnotations就是标准协议,类似这样:

实际使用时类似这样:


我们还需要考虑一个混淆和构建脚本的问题,因为组件以release混淆aar提供的话,针对构建时要keep整个子业务包的,但是子业务肯定会静态依赖使用底层组件,底层组件也是aar方式,所以我们需要对底层组件做定制的混淆映射规则,然后各子业务组件对于使用底层组件的地方按照这个规则混淆就好了。当然,也可以保持底层组件不混淆或者接口不混淆也可以。
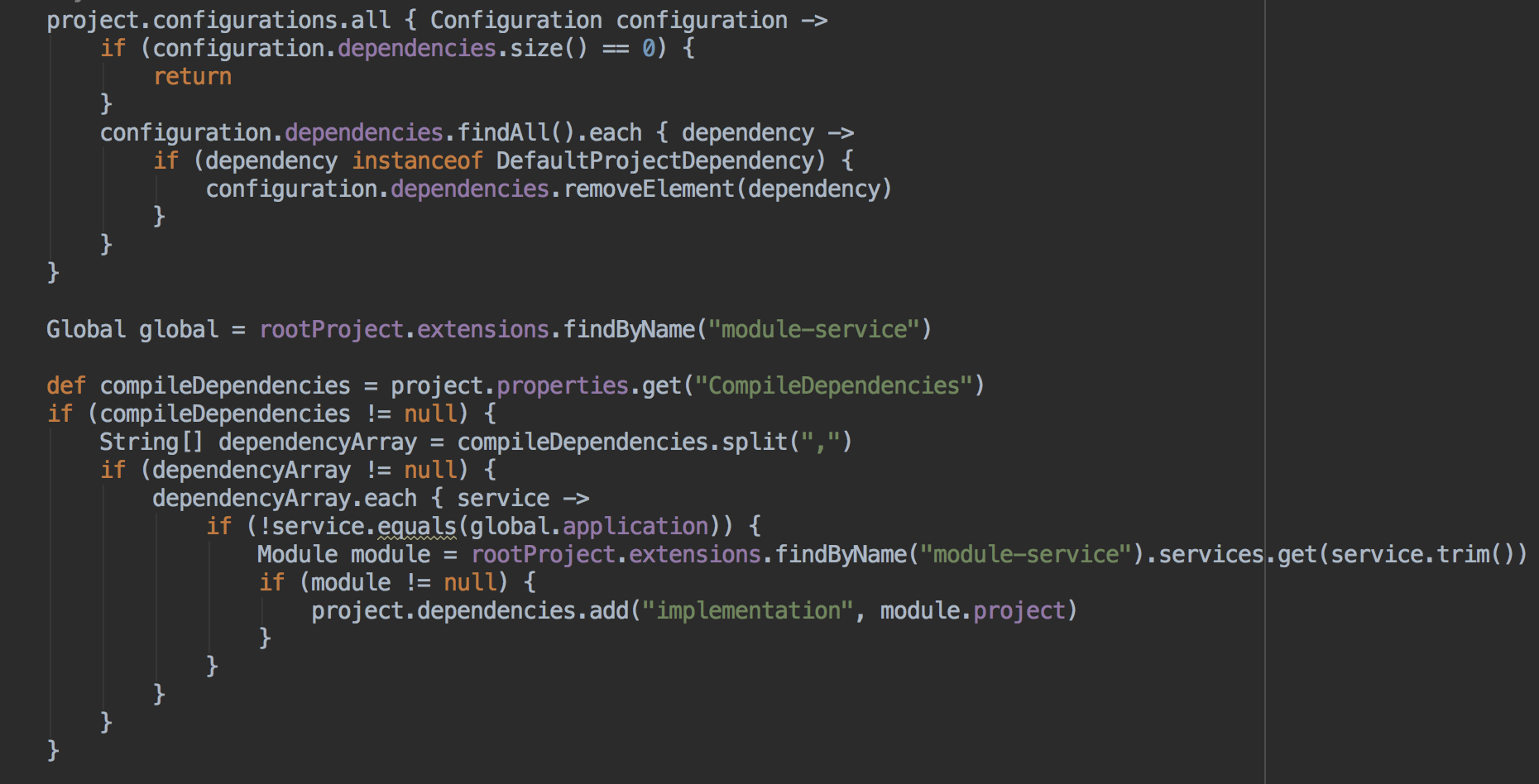
构建脚本指的是提供统一的基础构建流程给子业务使用,用来干什么呢?其实这是配套的扩展脚本,我的想法是每个组件由统一的配置表来申明信息,这些信息会写入到BuildConfig中供组件的生命周期使用,同时也会在整体构建流程里进行规则校验,比如回环依赖、同级依赖。
如图:
在每个子业务的gradle.properties里申明信息

同时也需要禁止掉build.gradle里对本地project的依赖,以属性表为准,类似这样:
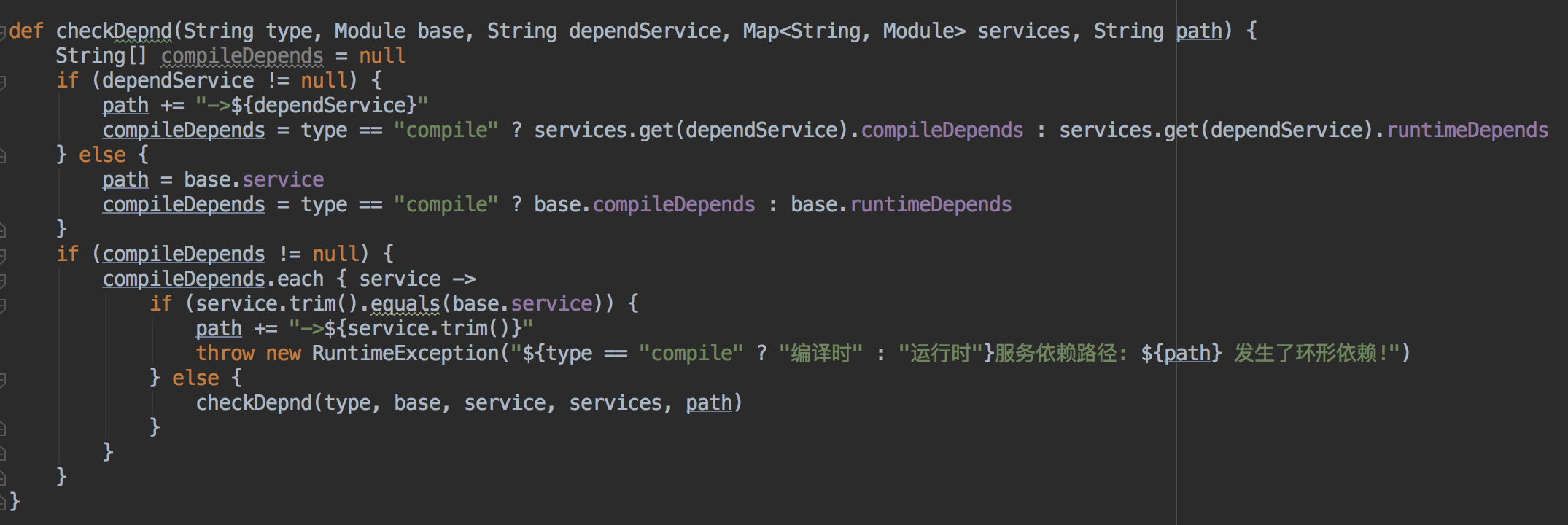
校验回环依赖:
这里不一一展现了,注意这个基础构建流程是给子业务输出aar使用的,和最后的临时构建脚本不一样,如果你的项目不需要子业务独立而是走的源码方式,后续会讲解按照这个框架来变化。
接着写入buildconfig:
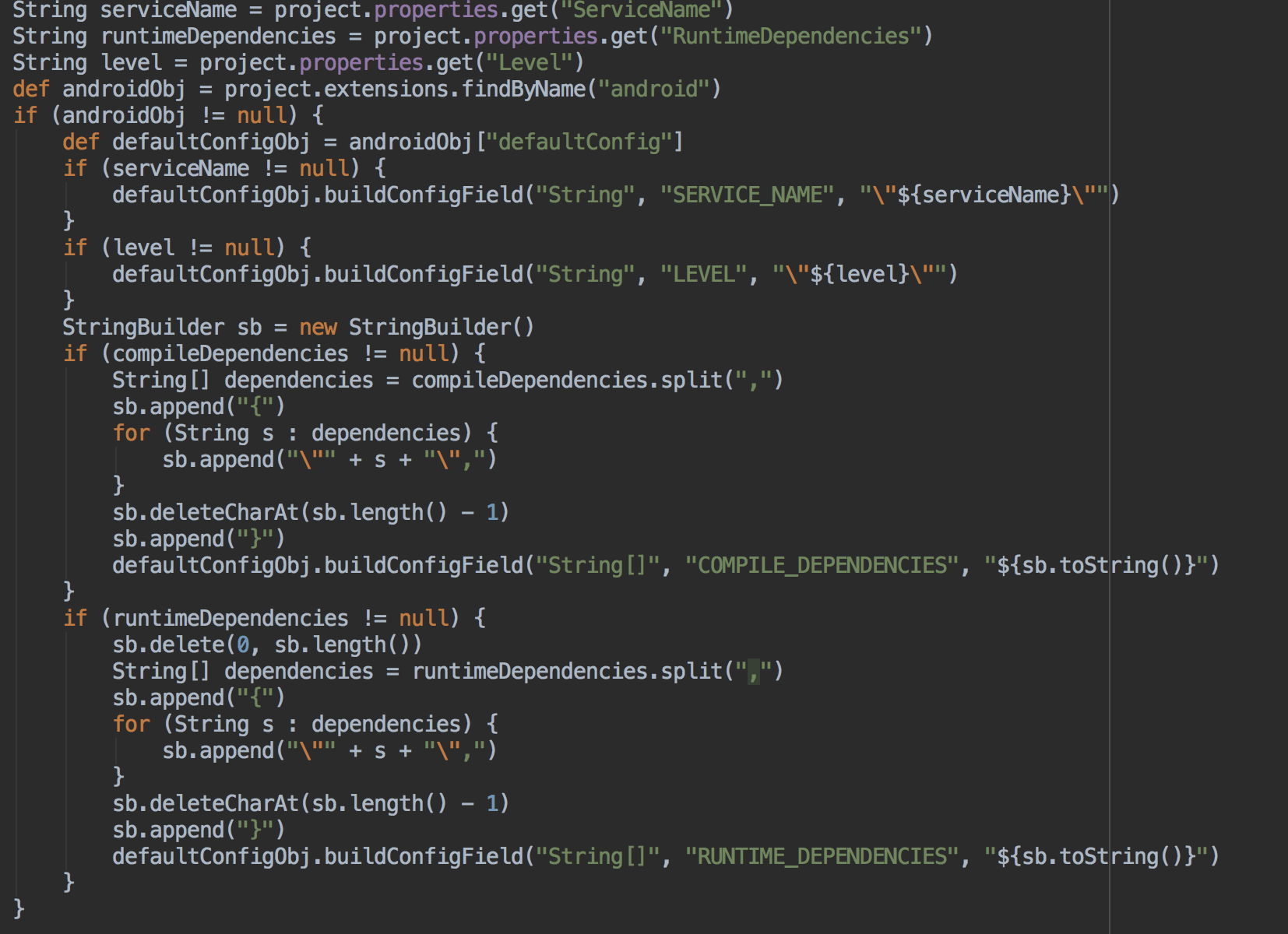
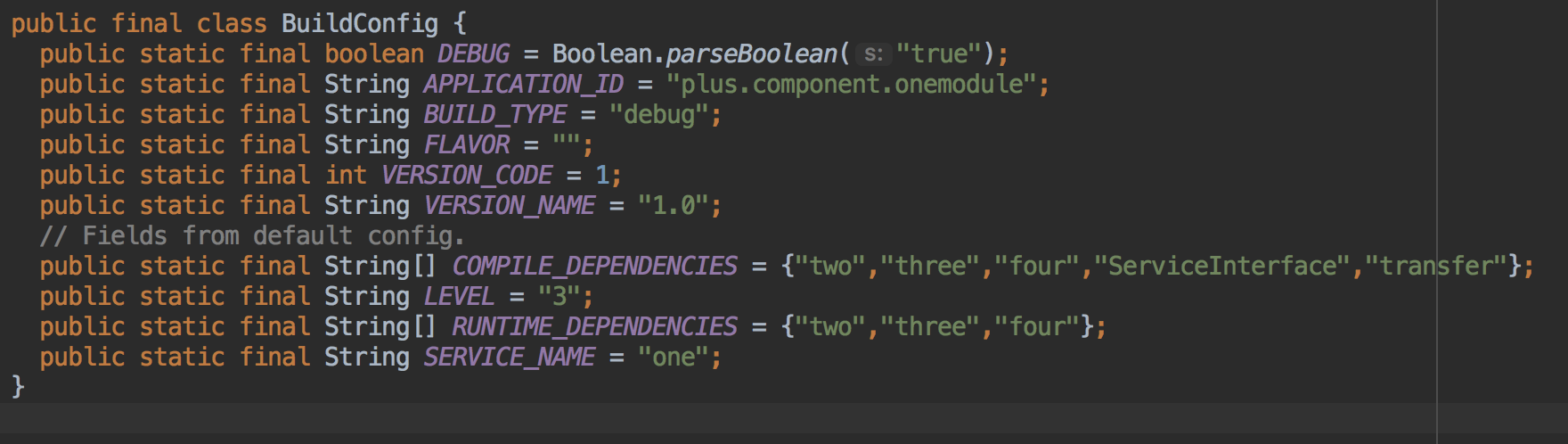
到这里可能你会问上面说的BuildConfig信息给生命周期、整体构建流程使用是什么意思?先不说生命周期,如果子业务是独立的aar,就不存在前面的比如回环校验了,这时要在transform里提取出所有BuildConfig的信息来校验,就是这个意思,而生命周期是什么?你应该注意到了,属性配置表里有RuntimeDependencies,顾名思义就是运行时依赖,运行时依赖决定了你所依赖的组件要先于你准备好才能保证你可以正常使用,所以需要对每个组件的生命周期接口化,类似这样:
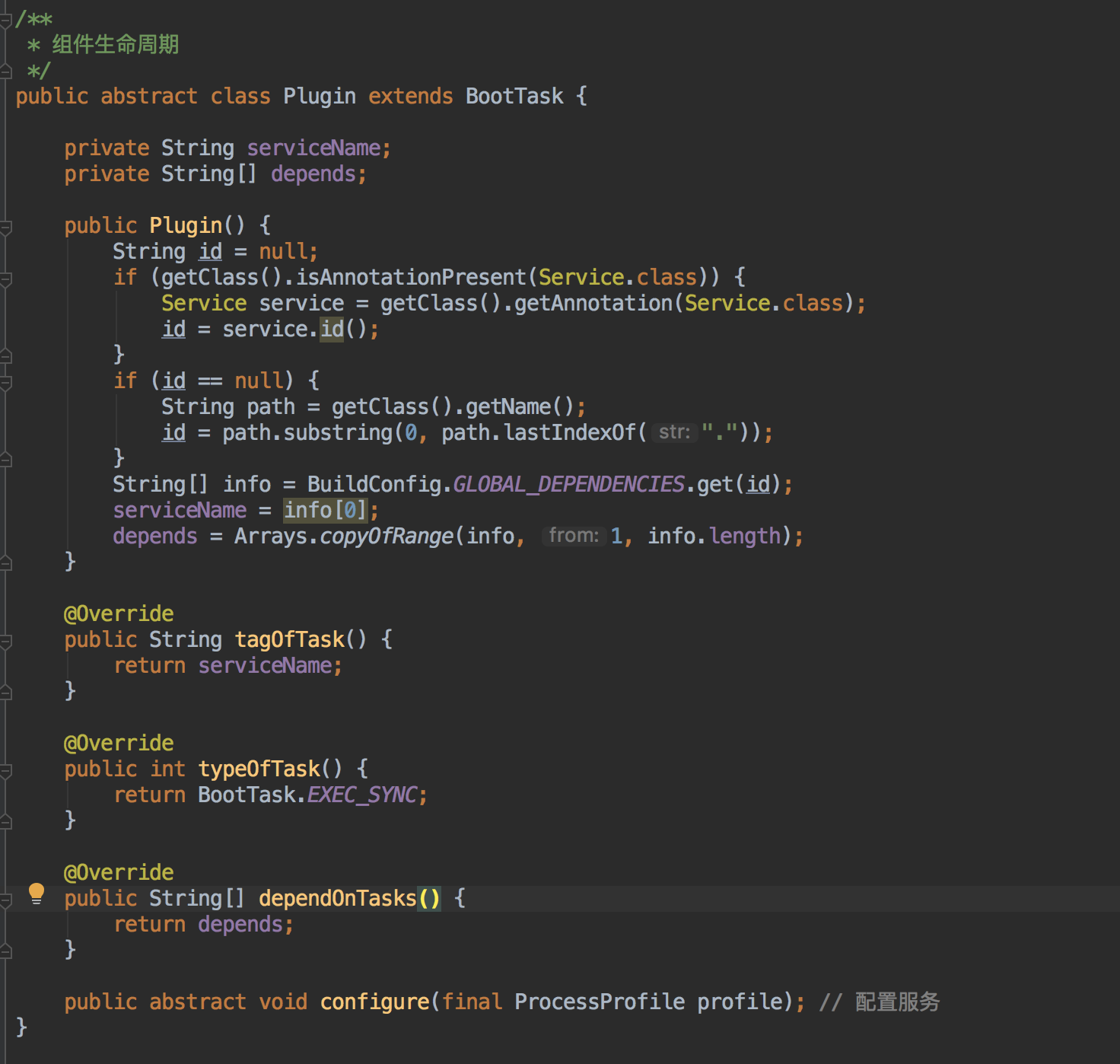
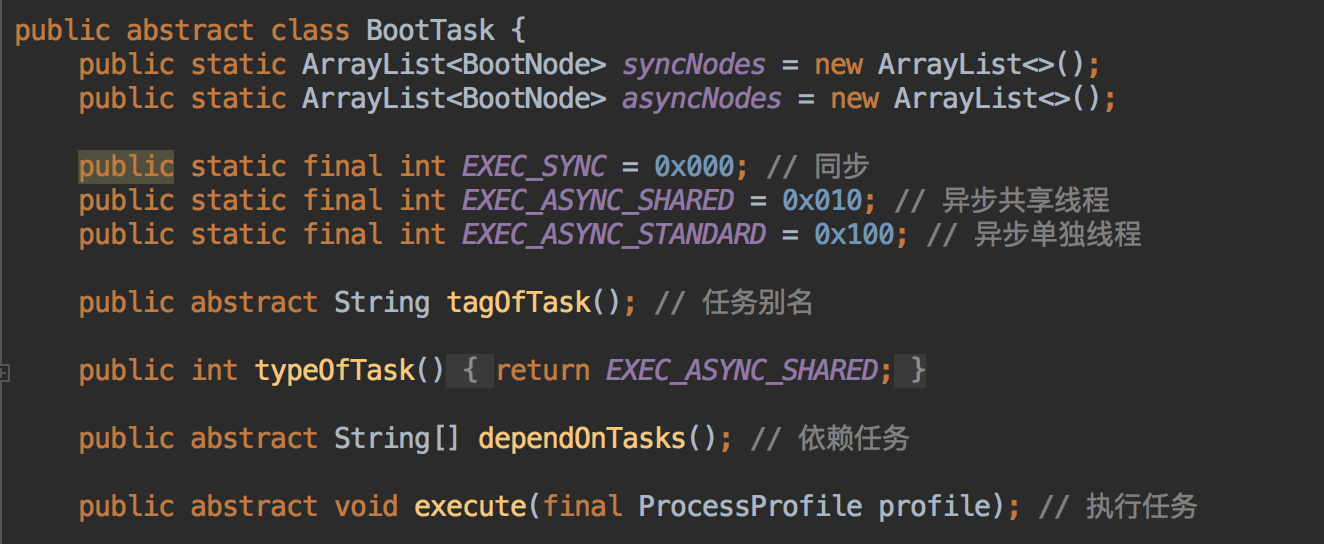
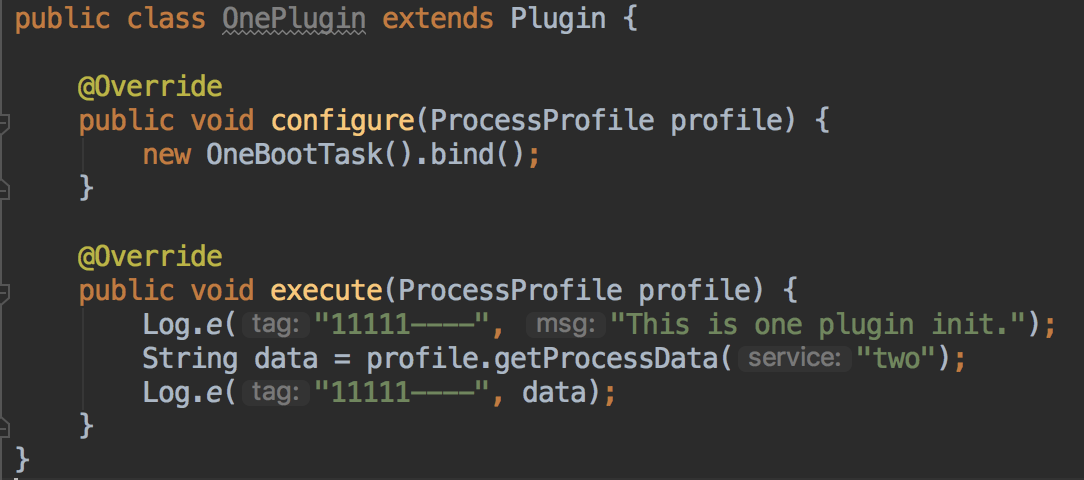
不用看具体逻辑,主要有4个接口,tagOfTask、dependOnTasks、configure、execute,这样我们就可以把Application里那一堆初始化逻辑细分到各自的子业务组件中了,并且还把里面可能存在的隐式依赖显式化了,各组件的生命周期会按照指定的依赖顺序以树的根节点开始进行,就算是新来的同事也不用担心对初始化流程改动造成问题了。
现在说下子业务组件不是aar的方式,emm,总有小的项目。这样的情况,如果觉得全局协调者和标准协议这套东西麻烦,直接以最开始讲的,各业务子组件以中间接口的依赖来通信,而凹面的填充也可以下沉到各子组件得生命周期接口里自行完成。
以上就是我对组件化的一些理解,搭好这套架构后,每个子业务内部其实是可以很自由得有自己的架构的。
