

Hyperledger Fabric:一种分布式操作系统-基于准入控制的区块链
摘要
Hyperledger Fabric 是一种模块化的,可扩展的开源的用于部署和操作权限的区块链系统。Fabric目前被用于超过400多种原型以及概念证明阶段的分布式账本技术的场景中,如很多生产系统,跨越了不同行业和使用场景。
基于“one-sizefits-all”解决方案的前提出发,Fabric是第一个运用于分布式应用程序的真正可扩展的区块链系统。它支持模块化的共识协议,允许系统根据特定用例和信任模型进行定制。Fabric也是第一个用通用编程语言开发智能合约,不依赖本机加密货币的运行分布式应用的区块链系统。这与现有需要使用特定编程语言或者依赖加密货币才能开发智能合约的区块链平台形成了鲜明的对比。此外,它使用一个与行业标准身份管理相结合的易于理解的成员服务来实现许可模型。为了支持这种灵活性,Fabric采用了一种新颖的方法来设计带有权限控制的区块链系统和改进方式以应对非确定性,资源耗尽以及性能攻击。
本文描述了Fabric,它的架构,各种设计决策背后的基本原理,安全模型和保证,它最突出的实现方面,以及分布式应用程序编程模型。我们通过实现和测试基于比特币的数字货币进一步评估Fabric。我们展示了Fabric在某些流行的部署配置中实现了每秒超过3500TPS的吞吐量,具有亚秒级的延迟。
1.介绍
区块链可以定义为在分布式网络中维护在相互不信任的节点间的用于记录交易的不可变的分类账本。每个节点持有一份账本的拷贝。节点执行共识协议来验证交易,将它们打包进区块,在区块上建立hash链。这个过程由对交易进行排序形成,这是一致性所必须的一步。区块链技术中出现了比特币bitcoin.org/被广泛认为是一项有前途的在数字世界中运行可信赖的交换的技术。在公共或者无权限的区块链中,任何人都可以在没有特定身份的情况下参与。公共区块链通常涉及原生的加密货币,并且使用“工作量证明”(POW)和经济激励的共识。另一方面,带有准入机制的区块链运行在一组已知的已确定的参与者中。带有准入机制的区块链提供了一种在一组有共同目标但是互不信任对方的群体间进行交换的一种方法,例如企业间交换资金,货物或者信息。依靠节点的身份,带有准入机制的区块链可以使用传统拜占庭(BFT)协议进行共识。区块链可以以智能合约的形式执行任意的可编程交易逻辑,例如以太坊 ethereum.org/。比特币中的脚本是该概念的前身。智能合约充当受信任的分布式应用程序,并从区块链和基本的共识中获取安全性。这非常类似于使用状态及构建弹性应用程序的众所周知的方法复制状态机(SMR)[31]。然而,区块链离开了传统的复制状态机很重要的原因是:(1)同时不仅仅只运行一个,而是多个应用程序;(2)应用程序可以被任何人动态部署;(3)这些应用代码可能是不可信的,甚至是恶意的。这些差异导致需要一个新的设计。
许多现有的有智能合约的区块链遵循状态复制机[31]以及实现了所谓的主动复制[13]:一种共识协议或者原子广播,首先排序交易然后将它们传播给peer节点;第二,每个节点按顺序执行交易。我们将这个模式称作排序-执行架构;它要求所有的节点执行每个交易同时所有交易都是确定的。在现有的区块链系统中,从公有链,如以太坊(基于POW的共识),联盟链,如Tendermint tendermint.com/,Chain chain.com/和Quorum www.jpmorgan.com/global/Quor…中都是基于排序执行架构的。排序-执行架构设计不是所有系统都能立刻显现出来的,因为额外的交易验证步骤可能会模糊它,排序-执行的限制在于:所有节点都需要执行交易,所有交易必须是确定的。
事先获得许可的区块链受到很多限制,这些限制通常来源于他们没有权限的亲属或者使用排序-执行的架构。特别是:
- 共识在平台内是硬编码的,这与已有的理解相矛盾,没有“一刀切”的(BFT)共识协议;
- 交易验证的信任模型由共识协议决定,不能适应智能合约的要求;
- 智能合约必须用固定的,非标准的,或者特定领域的语言来开发,这阻碍了智能合约广泛传播采用并可能导致程序错误;
- 所有节点需要按顺序执行所有的交易,需要复杂的措施来防止不受信任的合约针对平台的拒绝服务攻击(如以太坊中在运行时计算的“gas”);
- 交易必须是确定的这一点,很难以编程方式来保证;
- 每个智能合约运行在所有节点上,这和保密性以及禁止将合约代码和状态传播给其他节点相违背。
在本文中,我们描述了Hyperledger Fabric或者简称Fabric,一个开源的克服了这些限制的区块链平台github.com/hyperledger… 。Fabric是一个Linux基金会linuxfoundation.org支持下的Hyperledger www.hyperledger.org的项目之一。Fabric被用于超过400多种原型,概念证明,在生产环境下的分布式账本系统,跨越了不同行业和用例。这些用例包括但是不限于解决争议等领域,贸易物流,外汇净额,食品安全,合同管理,钻石出处,奖励积分管理,低流动性证券交易和结算,身份管理,以及通过数字货币结算。
Fabric引入了一种新的具有弹性,灵活性,可扩展性和机密性的区块链架构。Fabric是一种模块化的可扩展的通用的带有准入权限的区块链,支持执行用标准编程语言编写的分布式应用程序。这使得Fabric成为第一个用于带有准入权限的区块链的分布式系统。
Fabric的体系架构遵循一种新的执行-排序-校验,用于不可信的分布式环境下执行不可信的代码的范式。它将交易氛围3个步骤,运行于系统的不同实体上:
- 执行交易并且验证它的正确性,从而对其背书(对应于其他区块链系统中的“交易验证”);
- 通过共识协议进行排序,不考虑交易的语义;
- 针对特定于应用程序的信任假设进行交易验证,这可以防止并发性导致的竞争条件。
这种设计与排序-执行的方式完全不同,Fabric在顺序达成一致之前先执行了交易。这结合了两种众所周知的复制方法,被动和主动,如下。
首先,Fabric使用了被动或者主备复制[6,13],这种方式经常在分布式数据库中被使用,但它是基于中间件的非对称更新处理[24,25],并且被移植到了拜占庭错误的非信任环境下。在Fabric中,每个交易仅仅被一小部分节点执行,允许并行执行,解决潜在的不确定性问题,借鉴“执行验证”BFT复制[21]。灵活的背书策略可以指定需要哪些节点以及多少节点为正确执行正确的智能合约进行担保。
其次,Fabric包括了主动复制,其中交易对账本状态的影响只有在所有交易经过共识排序之后才被更新,在确定性校验阶段分别在各自节点独立执行。这允许Fabric根据交易的背书策略来认可特定应用程序的信任假设。此外,状态更新的排序被委托给一个共识模块(即,原子广播)是无状态的,并且在逻辑上与执行交易和维护账本的节点分离。由于共识是模块化的,因此可以根据特定部署的信任假设来定制其实现。虽然可以何容易实现使用peer节点来进行共识,但是分离两个角色增加了灵活性,让人们可以依靠完善的CFT(故障容错)或者BFT(拜占庭容错)排序的工具包。
总体而言,这种混合复制设计混合了拜占庭模型中的被动和主动复制,以及执行顺序验证范例,代表了Fabric架构的主要创新。他们解决了之前提到的问题,并使Fabric成为了支持灵活信任假设的带有准入权限的可扩展的区块链系统。为了实现这个架构,Fabric包含了以下每个组件的模块化构建:
排序服务:一个排序服务自动广播状态更新到Peer节点上,建立对交易的共识。由Apache Kafka/ZooKeeper (kafka.apache.org/) 和 BFT-SMaRt [3]实现。
身份和成员服务:成员服务提供者负责将节点和加密身份关联起来。它保持了Fabric的基于权限的特性。
可伸缩的传播:一个可选的点对点的Gossip服务用于广播排序服务产生的区块到所有节点。
智能合约执行:在Fabric中,智能合约运行在一个隔离的容器环境中。它们可以由标准的编程语言开发,但是不能直接访问账本状态。
维护账本:每个节点都维护一个本地仅能追加的区块链账本,并且维护一个最新状态的快照在key-value存储中(KVS)。KVS可以使用标准库实现,例如LevelDB或者Apache CouchDB。
本文剩余部分描述了Fabric的架构以及我们使用它的经验。第2节总结了当前的发展状况,并解释了各种设计决策背后的基本原理。第3节详细介绍了Fabric的体系结构和执行-排序-校验方法,说明了交易执行流程。在第4节中,定义了Fabric的关键组件,特别是,排序服务,成员服务,点对点的消息广播,账本,智能合约API。基于公有云虚拟机环境下的Fabric参考比特币加密货币的性能评估中的结果和见解在第5节中给出。他们表明,Fabric在流行的部署配置中实现了超过3500tps的吞吐量,实现了延迟时间为几百毫秒的结果[36]。最后,在第6章中讨论了相关的工作。
2.背景
2.1 区块链的排序-执行架构
在以前的区块链系统中,不管带不带有权限,都遵循排序执行架构。这意味着区块链网络先对交易进行排序,使用共识协议对交易进行排序,然后按照相同的顺序在所有节点执行它们。
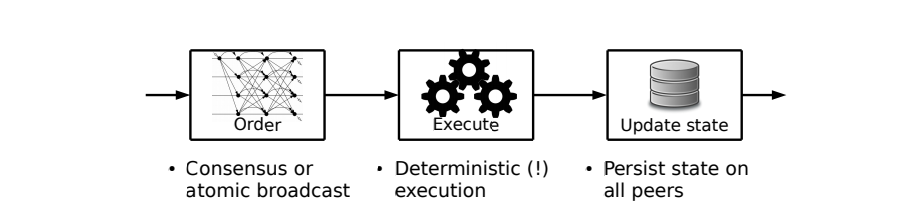
在复制服务中的排序执行架构
举个例子,基于PoW的无权限的区块链例如以太坊组合了共识和执行,如下:
- 每个节点(即,一个节点参与了共识)假设一个区块包含了合法的交易(来验证,这个节点已经预执行了这些交易);
- 这个节点尝试解决PoW谜题[28];
- 如果这个节点比较幸运解决了这个谜题,它将通过gossip协议向整个网络公布这个区块。
- 每个节点受到区块后会校验这个谜题的解法是否正确以及区块中所有的交易。 有效地,每个节点因此从第一步开始,重复执行幸运节点所做的。此外,所有节点都按顺序执行交易(一个区块接一个区块)。排序-执行架构如图一所示。
目前现存的带有权限控制的区块链,例如Tendermint,Chain,Quorum通常使用BFT共识算法[9],由PBFT[11]提供,或者由其他原子广播协议提供。不过,他们都遵循排序执行的架构,实现经典的复制状态机[13,31]。
2.2 排序执行的限制
排序执行架构在概念上很简单,因此被广泛使用。然而,当用于联盟链时,它有几个缺点。接下来我们讨论三个最重要的问题。
顺序执行。在所有节点上执行交易限制了区块链的吞吐量。特别是,吞吐量和交易延迟成反比,这可能成为除了简单智能合约以外所有智能合约的性能瓶颈。此外,与传统状态复制机相比,区块链平台形成了一个通用计算平台,其上的有效负载应用程序可能由对手部署。拒绝服务攻击将严重降低区块链的性能,可以简单的引入一个执行时间很长的智能合约。例如,执行一个死循环的智能合约将会产生致命的影响,但是不能自动检测,因为停机问题是无法解决的。
在很多区块链中应用程序被硬编码,例如比特币,交易执行叫做“transaction validation.”这里我们把这一步交易执行,来协调术语。
为了解决这个问题,公链使用带有加密货币账户来计算执行成本。例如,以太坊在交易执行的时候引入了gas的概念,gas的价格转换为加密货币的成本,由交易提交者支付。以太坊用了很长时间来实现这个概念,为每一步底层计算分配一个开销,引入自己的VM监视器来控制执行。虽然对公有链来说,这似乎是一个可行的解决方案,但是对联盟链来说这是不够的,因为没有本地加密货币的支持。
分布式系统文献提出了许多方法与顺序执行相比,提高性能的办法。例如,通过执行不相关的操作[30]。不幸的是,这样的技术仍然成功地应用于智能合约的区块链上下文中。例如,一个挑战是需要确定智能合约中的所有依赖关系,这是特别有挑战的。而且,这些技术对智能合约抵御不信任的开发者的DoS攻击是无效的。
不确定的代码。另一个关于这种并发地排序执行架构的问题是不确定性地交易问题。在共识完之后在状态复制机中执行操作,需要保证确定性,账本的复制,所有节点状态的一致性,但是这个方式违背了区块链最初的设计。这通常通过领域特定语言来解决(例如,以太坊),对于应用来说足够用于表达,但是仅限于确定性执行。然而,这种语言实现较为困难,而且要求开发人员学习额外的知识。采用通用编程语言开发智能合约(例如Go、Java、C/C++)反而显得更有吸引力,加快了区块链解决方案被接受的程度。
不幸地是,通用开发语言带来了许多确定性执行的问题。即使应用程序开发人员不明显地进行不确定性地操作,那些被隐藏的细节同样具有破坏性(例如Go语言中的map迭代器)。更糟糕的是,区块链负担创造确定性应用程序以来潜在的不可信的程序员。只要一个非确定性的带有恶意意图的合约足以让区块链停止。过滤发散的模块解决方案也研究过[8],但在实践中代价高昂。
执行的保密性。根据公有链中的蓝图,许多徐鹤的系统将智能合约运行在所有节点上。但是,许多联盟链中期望的案例需要保密,例如智能合约逻辑、交易数据、可分类的账本。虽然从数据加密到零知识证明[2]到可验证计算[26],可以帮助实现保密性,但是通常会带来相当大的开销,在实践中不可行。
幸运的是,将相同的状态传播给所有人就足够了,而不是到处运行相同的代码。因此,智能合约的执行可以限制在对这个任务可信的子集中执行,这样就证明了结果的可靠。这种设计将主动复制往被动复制[6]偏移,适应了区块链的信任模型。
2.3 现有架构的进一步限制
固定的信任模型。大多数联盟链依赖异步的拜占庭容错算法去建立共识[36]。这类协议通常依赖一个安全的假设,即n>3f节点,最多可以容忍f个节点作恶,所谓的拜占庭错误[4]。在相同的安全假设下,相同的节点也经常执行应用逻辑(即使实际上可以限制BFT在较少的节点执行)。然而这样的量化信任假设,无论节点在系统中是什么角色,可能与智能合约所需的信任不匹配。在一个灵活的系统中,应该信任应用程序级别而不是固定在协议级别的信任。通用区块链应该结偶这两个假设并允许灵活的应用程序信任模型。
硬编码的共识。Fabric是第一个引入可插拔共识的区块链系统。在Fabric之前,几乎所有区块链系统都采用了硬编码的共识协议。然而,几十年来对共识协议的研究表明,没有这样的“一刀切”的解决方案。例如,BFT协议在潜在的敌对环境[33]下性能差异很大。在具有对称和同构链路[18]的LAN集群上,具有“链”通信模式的协议表现出了可证明的最优吞吐量,但在广域异构网络上性能很差。此外,诸如负载,网络参数和实际故障或攻击之类的外部条件可能在给定部署中随时间变化。出于这些原因,BFT共识应该具有内在的可重构性,并且理想地适应不断变化的环境[1]。另一个重要方面是将协议的信任假设与给定的区块链部署场景匹配。实际上,人们可能希望使用基于可选信任模型(如XFT[27])的协议来替代BFT协商一致,或者使用CFT协议(如Paxos/Raft[29]和ZooKeeper[20]),甚至使用无许可协议。
2.4 排序执行的区块链的经验
在了解执行排序校验架构的Fabric之前,Fabric团队已经有利用排序执行模型构建使用PBFT[11]共识算法的带有准入权限的区块链构建经验。从许多概念证明的应用的反馈来看,这种方法的局限性立即变得清晰。举个例子,用户经常观察到节点间状态不一致并报告共识协议的bug;在所有情况下,仔细检查会发现罪魁祸首是非确定性交易。其他投诉以及限制的表现,例如,有用户反应“每秒只有5笔交易”,但是他们的交易每笔平均需要200毫秒才能执行完成。我们已经了解到区块链系统的关键属性,即一致性,安全性和性能,必须不依赖于用户的知识和意愿,特别是区块链运行在不受信任的情况下运行的。
3. 架构
在这一节,我们将介绍3阶段 执行-排序-校验架构并解释交易流程。Fabric的组建将在第4章介绍。
3.1 Fabric概览
Fabric是一个带有准入权限的分布式区块链系统,可以执行使用通用编程语言编写的分布式应用(例如:Go,Java,Node.js)。它安全地在只能追加的账本结构上追踪执行历史,而且没有内置的加密货币。
Fabric介绍了执行-排序-娇艳的区块链架构,并没有采用标准的排序执行设计,原因在第二章中介绍。简而言之,一个Fabric的分布式应用由两部分组成:
- 一个智能合约,叫链码,是实现了应用逻辑的程序代码,运行在执行阶段。链码在fabric中是分布式应用的核心,可能被不受信任的开发者开发。有一类特殊的链码为了管理区块链系统和维护参数,存在于系统中,叫做系统链码。(见4.6)
- 背书策略,在校验阶段执行。背书策略不能被不信任的应用开发者选择和修改;它们是系统的一部分。背书策略在Fabric中是一个静态库,可以由链码通过参数指定。只有指定的管理员可以运行系统管理功能,并有权修改背书策略。
一个典型的背书策略让链码指定交易的背书者,由一系列需要进行背书的peer节点指定;它使用一个简单的逻辑表达集合,例如“五个中的三个”或者“A and B or B and C”。自定义的背书策略可以实现任意逻辑(例如,我们的比特币加密货币,见5.1节)。
客户端发送交易到背书策略指定的peer节点。每个交易被特殊的节点执行,同时结果被记录,这步也叫做背书。在执行完了之后,交易进入排序阶段,使用可插拔的共识协议生产统一排序的交易,交易被打包进区块。这些区块会借助Gossip协议广播到所有的节点。不像标准的积极复制[31],会完全排序交易输入,Fabric排序结合状态的交易输出,在交易执行阶段计算所得。每个节点在校验阶段校验背书交易的状态变化以及执行的一致性。所有节点验证交易在同一个顺序并且验证是确定性的。在这个意义上,Fabric在拜占庭模型中引入了一种新的混合复制范例,它结合了被动复制(状态更新的预一致计算)和主动复制(执行结果和状态更改的后一致验证)。
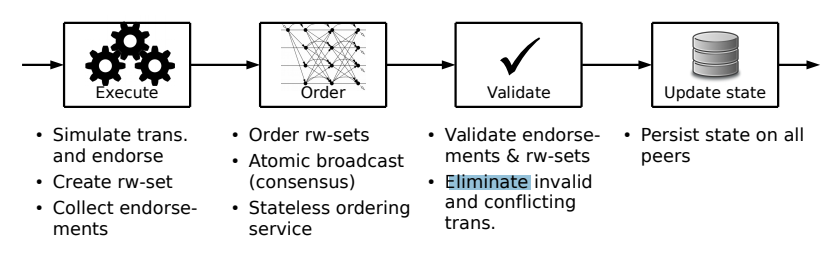
Fabric的执行-排序-校验架构(rw-set的意思是读集和写集合,在3.2中介绍)
执行顺序验证方法如图2所示。
一个Fabric区块链系统由一系列的node组成一个网络。正如Fabric是有权限控制的,所有参与网络的节点都带有身份,通过一个模块化的成员服务提供者(MSP)(4.1节)。节点在Fabric网络中承担3个角色:
Client: 提交交易提案用于执行,帮助编排执行阶段,最终,广播交易到排序服务。
Peers:执行交易提案同时校验交易。Peer同样维护区块链账本,一个只能追加的数据结构用于记录交易,组成一条hash链,同样也有状态,一个简洁的表现账本状态。不是所有的节点执行所有的交易提案,只有一部分叫做背书节点(或者简单说,背书者),由链码策略指定和哪个交易有关。然而,所有的节点都持有完整的账本。
排序服务节点
简单讲叫做Orderer,是公共的排序服务组件。简短地来说,排序服务在Fabric中建立了所有交易的顺序,在执行阶段每个交易包含了状态更新和计算的依赖,并带有背书节点的签名。Orderers不知道应用状态,也不参与交易的执行或者校验。这种设计在Fabric中渲染了模块化的共识并简化了共识协议的更换。
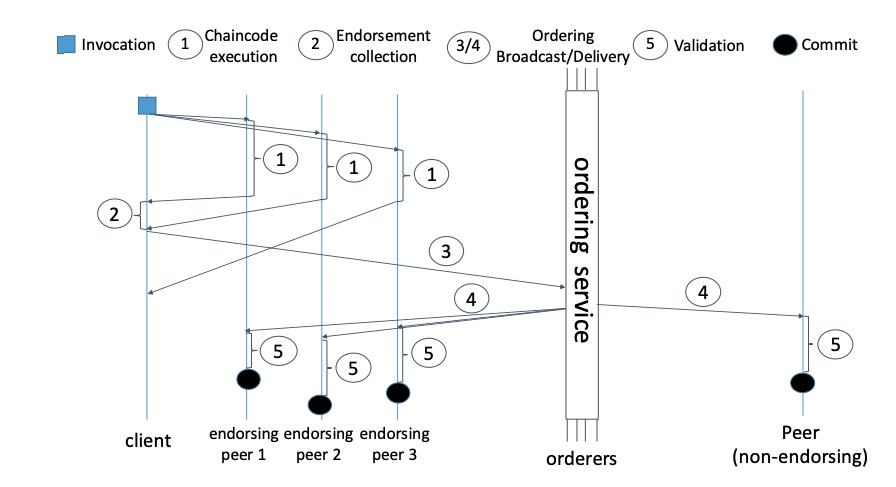
Fabric中high level交易流程
因为在同一个物理节点上扮演不同的角色成为了可能,因此Fabric可以被操作像传统的点对点区块链系统一样,在每个节点维护状态,调用,校验,排序交易。不同节点的交易流程在图三中描述。
对比目前未知只支持单链的区块链,目前为止,Fabric网络已经支持多链机制,支持多条链连接到排序服务。每个区块链叫做channel,并且拥有不同的节点作为成员。但是基于channel的共识不是协调进所有交易的,每个channel是相对于其他channel独立的。所有的部署都认为所有的orderer是可信的,同样实现在peer级别的基于channel的权限控制。在下面,我们简单提一下channel,集中精力在一个通道上。
接下来三个章节解释了Fabric中的交易流程,阐明了执行,排序和校验的步骤。一个Fabric网络如图四所示。
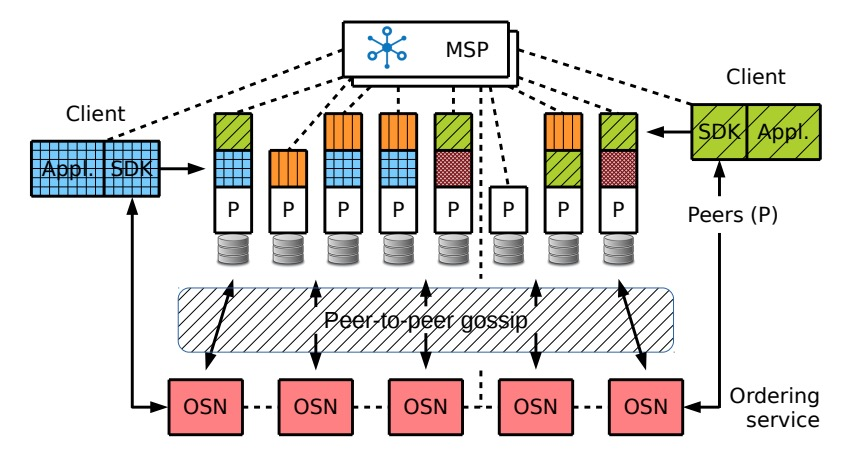
一个带有联盟MSP的Fabric网络以及运行了(不同阴影和颜色的)链码,根据策略有选择地安装到节点上。
背书节点模拟提案,通过安装在区块链中的特定链码执行操作。链码运行在Docker容器中,与背书进程独立。
一个提案在这时候基于背书节点本地状态进行模拟,没有与其他节点同步;甚至背书节点没有持久化模拟的结果到账本状态中。区块链的状态被 peer transaction manager (PTM)在带有版本的键值对维护,成功地更新将单调增加版本的值(见4.4)。一个链码创建的状态不能直接被另一个链码访问。链码不应该在程序代码中维护状态。唯一能够维护的应该是 GetState, PutState, and DelState操作。手续适当的权限,一个链码可以调用另一个链码在相同的通道中去获取状态。
作为模拟的结果,每个背书者产生了writeset,包含模拟执行产生的状态更新(例如用一个新的值修改一个key),同时产生一个readset,代表提案模拟基于的依赖版本(例如,所有读出的key的版本)。在模拟之后,背书节点签名一个消息叫做背书,包含了读集,写集,(同时包含元数据例如交易id,背书者id,背书者签名),并发送回客户端一个提案响应。一个客户端收集直到满足链码背书策略,交易调用(参见3.4)。特别地,这要求所有的背书者确定地生产同样的执行结果(例如,相同的读集和写集)。然后,客户端继续创建交易,发送到排序服务。
**关于设计选择的讨论。**背书节点模拟执行交易没有与其他背书节点同步,2个背书节点可能根据不同的账本状态执行从而产生不同的输出。对于标准的背书策略,需要多个背书节点产生相同的结果,这意味着在多个操作对同一个key的争论,一个客户端可能不能满足背书策略。与复制中的主备复制(通过中间件[24])相比,这是一个新元素:假设没有一个节点的执行结果在区块链网络中是可信的。
我们有意识地采用了这个设计,因为它简化了架构而且非常适用于区块链应用。正如比特币演示的,分布式应用程序在正常情况下,访问相同状态的操作可以减少或者完全消除(例如,在比特币中,2个操作修改了同样的对象是不允许的,代表双花攻击[28])。
在排序阶段前执行交易是容忍不确定性链码非常重要的一点在第二节。Fabric中一个不确定性交易只会危及其自身的活性,因为客户端无法收集足够多数量的背书,这是更容易接受的在实践中,相比于排序执行架构,排序执行架构会导致节点状态的不一致。
最后,容忍不确定性执行还可以处理不可信链码的DoS攻击,因为如果背书节点怀疑DoS攻击,可以根据本地执行策略终止执行。这不会影响系统的一致性,而且在排序执行架构中,这种单方面终止是不可能的。
3.3 排序阶段
当客户端在提案上收集了足够多的背书时,他会组装一个交易并讲它提交给排序服务。该交易包括交易的有效负载(例如,链码操作相关参数),交易元数据,一系列背书。排序服务为每个渠道上的所有交易进行排序。换句话说,排序源原子广播[7]背书,从而在交易上达成共识,尽管可能有错误的排序者。此外,排序服务将多个交易打包进区块,并输出包含交易的带有hash链的区块。将交易分组或者批量打包进区块可以提升广播协议的吞吐率,这是容错广播环境中众所周知的技术。
在高层次来看,排序服务仅仅支持下列2个操作。这些操作由peer节点通过通道标识隐式参数化:
broadcast:客户端调用此操作来广播任意交易tx,该交易通常包含交易有效负载和客户端的签名,以便进行传播。
deliver:客户端调用此方法以检索具有非负序号s的块B.该块包含交易列表和表示序列号为的块的哈希链值h,即。由于客户端可以多次调用它并且一旦它可用就总是返回相同的块,我们说当在调用deliver时第一次接收B时,Peer传递具有序列号s的块B。
排序服务确保一个通道上交付的块完全有序。更具体地说,排序确保了每个渠道的以下安全属性:
协议:对于任何带有序列号s和的两个块B,在正确的Peer上传送,如s=s',它保证B=B'。
Hashchain完整性:如果某个正确的节点传递带有编号s的块B而另一个正确的节点传递带有编号s+1的块B'=([tx1,...,txk],h'),则它保持h'=H(B),其中H(.)表示加密散列函数。
不跳过:如果正确的节点p为每个i=0,...,s-1发送一个编号为s>0的块,则节点p已经发送了一个编号为i的块。
无创建:当正确的节点传递带有编号s的块B时,则对于每个tx < B,某个客户端已经广播了tx。
为了活跃,排序服务至少支持以下“最终”属性:
有效性:如果正确的客户端调用广播(tx),则每个正确的节点最终都会传送包含tx的块B,其中包含一些序列号。
但是,允许每个单独的订购实现都有自己的客户请求的活跃性和公平性保证。
由于区块链网络中可能存在大量节点,但预计只有相对较少的节点实现排序服务节点,因此可以将Fabric配置为使用内置Gossip服务将所交付的块从排序服务传播到所有Peer节点(第4.3节)。Gossip的实现是可扩展的,并且与排序服务的特定实现无关,因此它适用于CFT和BFT订购服务,确保了Fabric的模块化。
排序服务还可以执行访问控制检查以查看是否允许客户端在给定信道上广播消息或接收块。排序服务的这一功能和其他功能将在第4.2节中进一步说明。
关于设计选择的讨论。排序服务不维护区块链的任何状态非常重要,既不验证也不执行交易。这种架构是Fabric的一个重要的定义功能,它使Fabric成为第一个区块链系统,可以完全区分执行和验证的共识。这使得共识尽可能模块化,并实现了实现排序服务的共识协议生态系统。
3.4 验证阶段
通过直接连接到排序服务或通过八卦将块交付给Peer节点。当新块到达时,它进入验证阶段,包括三个连续步骤:
1.对于块内的所有交易,背书政策校验并行发生。校验是所谓的验证系统链码(VSCC)的任务,VSCC是一个静态库,是区块链配置的一部分,负责验证对链码所配置的背书政策的校验(参见第4.6节) 。如果校验不满意,则交易被标记为无效,其影响将被忽略。
2.按顺序对块中的所有交易进行读写冲突检查。对于每个交易,它将readset字段中的密钥版本与分类帐的当前状态中的密钥版本进行比较,由节点本地存储,并确保它们仍然相同。如果版本不匹配,则事务将标记为无效,并忽略其影响。
3.分类帐更新阶段最后运行,其中块附加到本地存储的分类帐,并更新区块链状态。特别是,当将块添加到分类帐时,前两个步骤中的有效性检查结果也会以位掩码的形式保留,表示块内有效的交易。这有利于稍后重建状态。此外,通过将writeset中的所有键值对写入本地状态来应用所有状态更新。
Fabric中的默认VSCC允许在表示链代码的配置的背书集合上单调逻辑表达式。VSCC评估证明,通过对交易的认可通过有效签名表达的节点集合满足表达式。但是,不同的VSCC策略可以静态配置。
关于设计选择的讨论。 Fabric的分类帐包含所有交易,包括那些被视为无效的交易。这是从整体设计得出的,因为与链码状态无关的排序服务产生了块的链,并且因为验证是由共识后的Peer节点完成的。在某些需要在后续审计期间跟踪无效交易的用例中需要此功能,并与其他区块链形成对比图5. Fabric Peer节点组件。
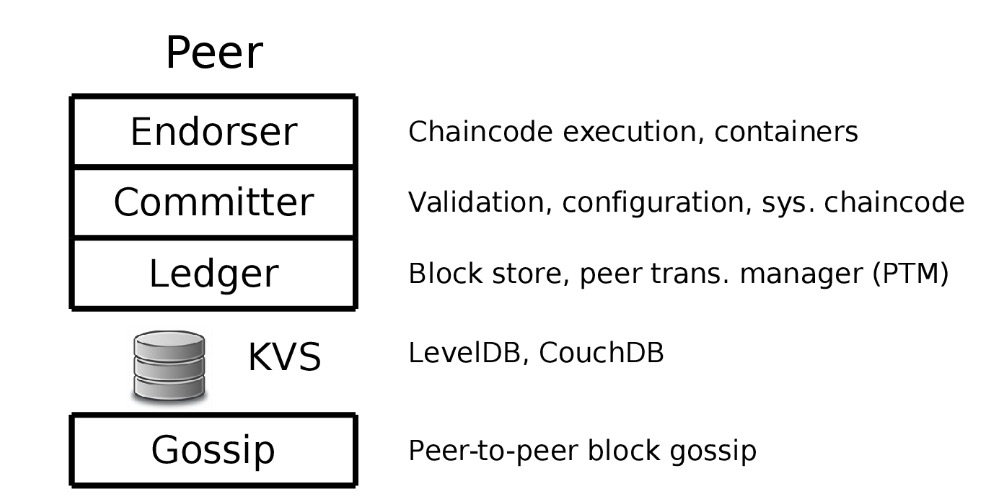
4. Fabric组件
Fabric是用Go编写的,使用gRPC框架(grpc.io/)进行客户端,Peer…
4.1 成员服务
成员服务提供者(MSP)维护系统中所有节点的标识(客户端,Peer节点和排序者),并负责颁发用于身份验证和授权的节点凭据。由于Fabric是经过许可的,因此节点之间的所有交互都通过经过身份验证的消息进行,通常使用数字签名。会员服务包括每个节点的组件,可以在其中验证交易,验证交易的完整性,签署认可,验证认可以及验证其他区块链操作。用于密钥管理和节点注册的工具也是MSP的一部分。
MSP是一种抽象,可以使用不同的实例。Fabric中的默认MSP实现处理基于数字签名的标准PKI方法,并且可以容纳商业认证机构(CA)。还提供独立CA和Fabric,称为Fabric-CA。此外,设想了替代的MSP实现,例如依赖于匿名凭证来授权客户端调用事务而不将其链接到身份[10]。
Fabric允许两种模式来设置区块链网络。在fl ine模式中,凭证由CA生成并在带外分发到所有节点。同侪和订购者只能在fl ine模式下注册。对于注册客户端,Fabric-CA提供了一种在线模式,可以向其发出加密凭据。MSP配置必须确保所有节点(尤其是所有节点)识别出与有效相同的身份和身份验证。
MSP允许身份联合,例如,当多个组织运行区块链网络时。每个组织都向自己的成员发放身份,每个同行都认可所有组织的成员。这可以通过多个MSP实例来实现,例如,通过在每个组织和MSP之间创建映射。
4.2 排序服务
排序服务管理多个通道。在每个通道,它提供一下服务:
- 用于简历交易顺序,实现广播和传递服务。
- 当成员通过广播配置更新交易时,可以重新配置通道。
- 可选地,在排序服务充当可信实体的那些配置中,可以限制向特定的客户端和Peer节点广播交易。
排序服务在系统通道上使用创世区块进行启动。该区块定义了排序服务的属性。
当前的生产实现包括实现此处描述的操作并通过系统通道进行通信的订购服务节点(OSN)。实际的原子广播功能由Apache Kafka(http:// kafka.apache.org)的实例提供,该实例基于ZooKeeper提供可扩展的发布 - 订阅消息传递和节点崩溃的强一致性。Kafka可以在与OSN分开的物理节点上运行。OSN充当Peer和Kafka之间的代理。
OSN直接将新接收的交易注入原子广播(例如,向Kafka broker)。另一方面,节点批量交易从原子广播的块中接收。只要满足以下三个条件之一,就会切一个块:(1)该块包含指定的最大交易数量; (2)块已达到最大大小(以字节为单位);或(3)自收到新区块的第一次交易以来已经过的时间量,如下所述。
该批处理过程是确定性的,因此在所有节点处产生相同的块。考虑到从原子广播接收的交易流,很容易看出前两个条件是平凡的确定性。为了确保第三种情况下的确定性块生成,节点在从原子广播读取块中的第一个交易时启动计时器。如果在计时器到期时块尚未被切下,则节点在通道上广播特殊的切割时间交易,该事务指示它想要切割的块的序列号。另一方面,每个节点在接收到给定块号的第一个切换时间交易时立即切断新块。由于此交易以原子方式传递到所有连接的节点,因此它们都在块中包含相同的交易列表。 (要在存在f拜占庭故障的OSN的情况下部署此方案,只有在接收f+1时间切换交易时才会切断该块。)排序者将最近交付的一系列块直接保存到其文件系统中,因此它们可以回答Peer节点通过交付检索块。
使用Kafka的排序服务是目前可用的三种排序服务之一。名为Solo的集中式排序服务在一个节点上运行,用于开发。基于BFT-SMaRt的概念验证排序[3]也已经提供[34];它确保原子广播服务,但尚未重新配置和访问控制。这说明了Fabric中共识的模块性。
4.3 Peer Gossip
排序和验证分离执行的一个优点是他们可以独立扩展。但是,由于大多数一致性算法(在CFT和BFT模型中)都是带宽限制的,因此排序服务的吞吐量受其节点的网络容量限制。通过添加更多节点无法扩大共识[14,36],相反,吞吐量会降低。但是,由于排序和验证是分离的,因此我们感兴趣的是在排序段之后将执行结果有效地广播到所有Peer节点以进行验证。这正是Gossip组件的目标,它为此目的利用流行多播[15]。这些块由排序服务签署。这意味着Peer节点可以在接收到所有块时独立地组装区块链并验证其完整性。
与覆盖网络相比,通过八卦传播是强大的并且抵抗节点故障。进行随机选择允许八卦减少维持Peer节点之间连接的开销,并且还减少了攻击面。Gossip在允许的环境中运行良好,可以承受sybil攻击和消息伪造。
用于八卦的通信层基于gRPC并且利用具有相互认证的TLS,这使得每一方能够将TLS凭证绑定到远程Peer的身份。八卦组件维护系统中在线Peer的最新成员视图。所有Peer独立地从定期传播的成员资格数据构建本地视图。此外,在崩溃或网络中断后,节点可以重新连接到视图。
八卦的主要目的是利用推挽协议可靠地在节点之间分配消息,即来自排序阶段的块。它使用两个阶段进行信息传播:在推送期间,每个节点从成员资格视图中选择一组随机的活动邻居,并将它们转发给它们;在拉取期间,每个节点周期性地探测一组随机选择的节点并重新寻找丢失的消息。已经显示[15,22]使用两种方法串联对于最佳地利用可用带宽并确保所有节点以高概率接收所有消息是至关重要的。
为了减少从排序节点到网络的发送块的负载,该协议还选择了一个领导节点,它代表它们从排序服务中提取块并启动八卦分发。这种机制对领导者失败具有弹性。
八卦的另一个任务是将状态转移到新连接的节点和长时间断开连接的节点。他们需要接收链中的所有块。该特征依赖于每个节点存储的最大块序列号与成员资格数据一起传播的事实。
4.4 分类账
每个Peer的分类帐组件在持久存储上维护分类帐和区块链状态,并启用模拟,验证和分类帐更新阶段。从广义上讲,它由块存储和节点交易管理器(PTM)组成。
Ledger块存储。分类帐块存储持久化交易块,并实现为一组仅附加文件。由于块是不可变的并且以有限的顺序到达,因此仅附加结构可以提供最大的性能。此外,块存储维护一些索引,用于随机访问块或块中的交易。
节点交易管理器(PTM)。 PTM在版本化的键值存储中维护最新状态。它为由任何链代码存储的每个唯一条目key存储形式(key,val,ver)的一个元组,包含其最近存储的值val及其最新版本ver。版本由块序列号和块内的交易(存储条目)的序列号组成。这使得版本独特且单调增加。
PTM使用本地键值存储来实现版本化键值存储,由Go中实现的LevelDB键值数据库实现(https:// github.com / syndtr / goleveldb)或Apache CouchDB(http:// couchdb.apache.org/)。
在模拟期间,PTM为交易提供最新状态的稳定快照。如3.2节所述,PTM在readset中为GetState访问的每个条目记录元组(key,ver),在writeset中记录事务用PutState更新的每个条目的元组(key,val)。此外,PTM支持范围查询,为此计算查询结果的加密哈希值(一组元组(key,ver)),并将查询字符串本身和哈希值添加到readset。
对于交易验证(第3.4节),PTM按顺序验证块中的所有交易。这将检查交易是否与任何先前的交易(在块内或更早的交易中)冲突。对于readset中的任何键,如果readset中记录的版本与最新状态中存在的版本不同(假设所有先前的有效交易都已提交),则PTM将该事务标记为无效。对于范围查询,PTM重新执行查询并将散列与readset中存在的散列进行比较,以确保不会发生幻像读取。这种读写冲突语义导致单拷贝可串行化[23]。
分类帐组件在分类帐更新期间容忍Peer崩溃,如下所示。在接收到新块之后,PTM已使用第3.4节中提到的位掩码在块中执行验证并将交易标记为有效或无效。分类帐现在将块写入分类帐块存储,将其复制到磁盘,然后更新块存储索引。然后,PTM将所有有效交易的writeset的状态更改应用于本地版本存储。最后,它计算并保持值保存点,表示最大成功应用的块编号。值savepoint用于在从崩溃中恢复时从持久块中恢复索引和最新状态。
4.5 Chaincode执行
Chaincode在与Peer节点的其余部分松散耦合的环境中执行,并且支持用于为编程链代码添加新语言的插件。目前,链代码支持三种语言:Go,Java和Node。
每个用户级或应用程序链代码都在Docker容器环境中的单独进程中运行,该环境将链代码彼此隔离,并与节点代码隔离。这也简化了链代码生命周期的管理(即,启动,停止或中止链代码)。链代码和对等体使用gRPC消息进行通信。通过这种松散耦合,Peer节点不知道实现链代码的实际语言。
与应用程序链代码相反,系统链代码直接在对等进程中运行。系统链代码可以实现Fabric所需的特定功能,并且可以在用户链代码之间的隔离过度限制的情况下使用。有关系统链代码的更多详细信息,请参见下一节。
4.6 配置与系统链码
Fabric的基本行为是通过通道配置和特殊链码(称为系统链码)组成的。
渠道配置。回想一下,一个通道形成一个逻辑区块链。通道的配置保存在特殊配置块中的元数据中。每个配置块包含完整的通道配置,不包含任何其他交易。每个区块链都以一个称为创世块的配置块开始,该块用于引导通道。渠道配置包括:
•参与节点的MSP定义。 •OSN的网络地址。 •共识实现和排序服务的共享配置,例如批量大小和超时。 •管理排序服务操作(广播和交付)访问的规则。 •可以修改管理通道配置的每个部分的规则。
可以使用通道配置更新事务来更新信道的配置。此事务包含对配置所做更改的表示,以及一组签名。订购服务节点通过使用当前配置来验证更新是否有效,以验证使用签名授权修改。然后,排序者生成一个新的配置块,它嵌入了新的配置和配置更新交易。接收此块的节点根据当前配置验证配置更新是否被授权;如果有效,他们会更新当前的配置。
系统链代码。部署应用程序链代码时引用了认可系统链代码(ESCC)和验证系统链代码(VSCC)。以对称方式选择这两个链代码,使得ESCC的输出(认可)可以被验证为VSCC的输入的一部分。
ESCC将提案和提案模拟结果作为输入。如果结果令人满意,那么ESCC会产生一个包含结果和认可的回复。对于默认的ESCC,此认可只是对等方本地签名身份的签名。
VSCC将事务作为输入,并输出该事务是否有效。对于默认的VSCC,将根据为链代码指定的认可政策收集和评估认可。
其他系统链代码实现其他支持功能,例如配置和链代码生命周期。
5. 评估
尽管Fabric尚未经过性能调整和优化,但我们将在本节中报告一些初步性能数据。Fabric是一个复杂的分布式系统;它的性能取决于许多参数,包括分布式应用程序和交易大小的选择,排序服务和共识实现及其参数,网络中节点的网络参数和拓扑,节点运行的硬件,节点数量和通道,进一步的配置参数和网络动态。因此,Fabric的深入性能评估被推迟到未来的工作中。
在没有区块链标准基准的情况下,我们使用最突出的区块链应用来评估Fabric,这是一种简单的权威铸造加密货币,它使用比特币的数据模型,我们称之为Fabric coin(以下简称为Fabcoin)。这允许我们将Fabric的性能放在其他许可区块链的上下文中,这些区块链通常来自比特币或以太坊。例如,它也是其他许可区块链基准测试中使用的应用程序[19,32]。
在下文中,我们首先描述了Fabcoin(第5.1节),它还演示了如何定制验证阶段和认可政策。在5.2节中,我们提出基准并讨论我们的结果。
5.1 Fabric coin
UTXO加密货币。比特币[28]引入的数据模型已被称为“未使用的交易输出”或UTXO,并且还被许多其他加密货币和分布式应用程序使用。UTXO表示数据对象演变中的每个步骤,作为分类帐上的单独原子状态。这种状态由交易创建,并由稍后发生的另一个唯一交易销毁(或“消耗”)。每个给定的交易都会破坏许多输入状态并创建一个或多个输出状态。比特币中的“硬币”最初是通过币基交易创建的,该交易奖励块的“矿工”。这在分类帐中显示为指定矿工为所有者的硬币状态。任何硬币都可以花费在硬币通过一个交易分配给新所有者的意义上,该交易原子地破坏指定前一个所有者的当前硬币状态并创建代表新所有者的另一个硬币状态。
我们在Fabric的键值存储中捕获UTXO模型,如下所示。每个UTXO状态对应于一次创建的唯一KVS条目(硬币状态为“未花费”)并且销毁一次(硬币状态为“花费”)。等价地,每个州可以被视为创建后具有逻辑版本0的KVS条目;当它再次被销毁时,它会收到版本1。不应该对这些条目进行任何并发更新(例如,尝试以不同方式更新硬币状态等于硬币的双倍花费)。
UTXO模型中的值通过引用几个输入状态的交易传输,这些输入状态都属于发出交易的实体。实体拥有一个状态,因为该实体的公钥包含在状态本身中。每个交易在代表新所有者的KVS中创建一个或多个输出状态,删除KVS中的输入状态,并确保输入状态中的值之和等于输出状态值的总和。还有一个策略确定如何创建价值(例如,比特币中的硬币群交易或其他系统中的特定薄荷操作)或销毁(即,作为执行所消耗的费用)。
Fabcoin实现。 Fabcoin中的每个状态都是形式的元组(键,val =txid.j,( 金额,所有者,标签)),表示作为具有标识符txid的交易的第j个输出创建的硬币状态,并将标记为label的金额单位分配给公钥所有者的实体。标签是用于识别给定类型的硬币的字符串(例如,“USD”,“EUR”,“FBC”)。交易标识符是唯一标识每个Fabric交易的短值。Fabcoin实施包括三个部分:(1)客户钱包,(2)Fabcoin链码,以及(3)Fabcoin实施其认可政策的定制VSCC。
Fabcoin链码。Peer运行Fabcoin的链代码,模拟交易并创建读取集和写入集。简而言之,在SPEND交易的情况下,对于∈输入中的每个输入硬币状态,链码首先执行GetState(in);这与Fabric的版本化KVS(Sec.4.4)中的当前版本一起进入readset。然后链代码为每个输入状态执行DelState(in),它还会添加到writeset并有效地将硬币状态标记为“花费”。最后,对于j=1,...,|输出|,链代码执行PutState(txid.j, out)第j个输出=(金额,所有者,标签)。此外,节点可选地运行交易验证代码,如下面在Fabcoin的VSCC步骤中所描述的;这不是必需的,因为自定义VSCC实际上验证了交易,但它允许(正确的)节点过滤掉可能格式错误的交易。在我们的实现中,链代码运行Fabcoin VSCC而无需加密验证签名。
自定义VSCC。最后,每个对等方使用自定义VSCC验证Fabcoin交易。这个验证首先是相应公共方法论下的sig中的加密签名。在每个实验中,在第一阶段,我们调用仅包含Fabcoin MINT操作的交易来生成硬币,然后运行实验的第二阶段,我们在先前铸造的硬币上调用Fabcoin SPEND操作(有效地运行单输入,单输出SPEND交易)。在报告吞吐量测量时,我们使用在单个VM上运行的越来越多的Fabric CLI客户端(修改为发出并发请求),直到端到端吞吐量饱和,并在饱和之前说明吞吐量。吞吐量数据被报告为平均吞吐量密钥,并执行如下的语义验证。对于MINT交易,它检查输出状态是否在匹配的交易标识符(txid)下创建,并且所有输出量都是正数。对于SPEND交易,VSCC还验证(1)对于所有输入硬币状态,已创建readset中的条目,并且它也是Client wallet。默认情况下,每个Fabric客户端维护一个添加到writeset并标记为已删除,(2)本地存储所有输入硬币状态的金额的加密密钥集合的Fabcoin钱包总和等于允许客户花费的总和硬币。为了创建所有输出硬币状态的SPEND数量,以及(3)传输一个或多个硬币的输入和输出,客户端钱包将硬币标签匹配。这里,VSCC通过从分类帐中检索它们的当前值来获得为输入硬币创建Fabcoin请求请求=(输入,输出,sigs的金额。
2在Fabric主分支中使用提交ID 9e770062进行分配。
包含:(1)输入硬币状态列表,在,...|中输入=|,指定客户希望花费的硬币状态(in,...),注意Fabcoin VSCC不检查transacwell为(2)输出列表硬币状态,输出金额,所有者,双重支出的tions,因为这通过Fabric的标签),...|发生。客户端钱包使用私钥进行签名,该私钥是在自定义VSCC之后运行的标准验证。在与输入硬币状态相对应的情况下,如果两个事务试图分配相同的unFabcoin请求和nonce(这是每个Fabric花费的硬币状态的一部分给新的所有者),则两者的串联都将通过VSCC事务,并在一组sigs中添加签名。当PTM执行的不确定性检查中的金额总和时,SPEND逻辑但随后将在读写事务中被捕获。根据Secput,硬币状态至少是输出3.4和4.4中的金额之和,PTM验证当前版本的输出量和输出量是正数。对于存储在分类帐中的MINT编号与readset中的编号匹配;创建新硬币的交易,输入仅包含一个因此,在第一个交易更改了特殊硬币状态的标识符(即,对公钥的引用)之后,第二个订购的交易将被称为中央银行( CB),而输出包含nized为无效。任意数量的硬币状态。要被视为有效,sigs中的MINT事务的5.2实验签名必须是加密设置。除非另有明确说明,否则我们在CB的公钥下的外部签名实验中:(1)节点运行在Fab版本请求的Fabric版本v1.1-preview2上,以及前面提到的通过本地lognonce进行性能评估的仪表。Fabcoin可以配置为使用多个CB或ging,(2)节点托管在单个IBM Cloud(SoftLayer)中,指定来自一组CB的阈值数量的签名。数据中心作为与1Gbps网络互连的专用虚拟机最终,客户端钱包包括将Fabcoin请求转换为工作,(3)所有节点都是运行事务的2.0 GHz 16-vCPU虚拟机,并将其发送给其选择的对等方。Ubuntu具有8GB的RAM和SSD作为本地磁盘,(4)单通道订购服务运行典型的Kafka订购者设置,包括3个ZooKeeper节点,4个Kafka代理和3个Fabric orderers,所有这些都在不同的VM上,(5)有5个总共同行,所有这些都是Fabcoin代言人,(6)签名使用默认的256位ECDSA方案。为了在跨越多个节点的事务流中测量和分级延迟,在整个实验中节点时钟与NTP服务同步。Fabric节点之间的所有通信都配置为使用TLS。
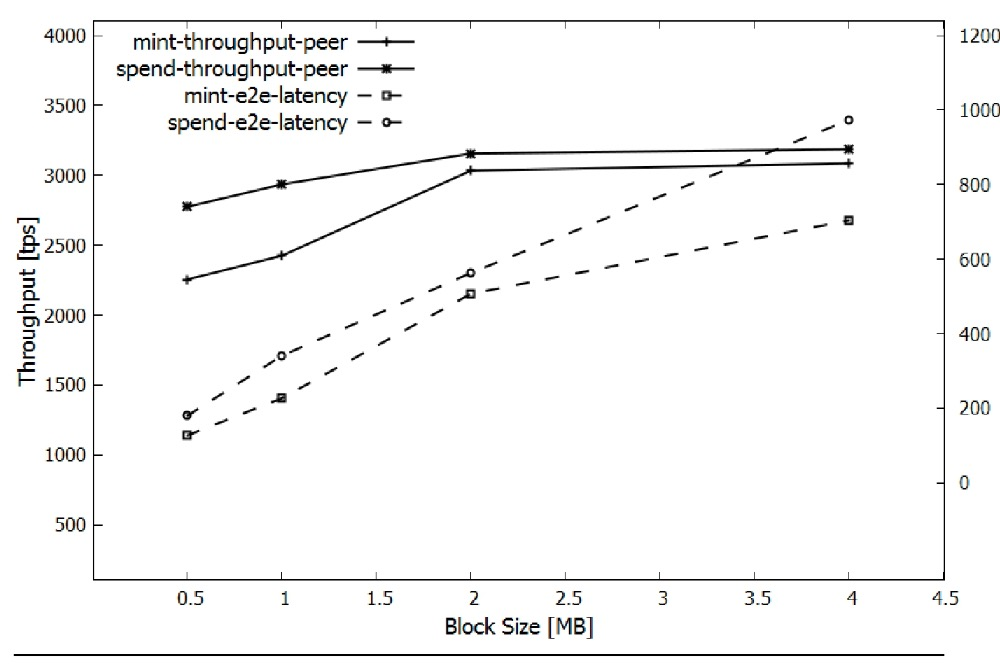
我们可以观察到吞吐量并没有显着超过2MB的块大小,但是延迟会变得更糟(正如预期的那样)。因此,我们采用2MB作为以下实验的块大小,目标是最大化测量的吞吐量,假设大约500ms的端到端延迟是可接受的。
交易规模。在此实验期间,我们还观察了MINT和SPEND事务的大小。特别是,2MB块包含473个MINT或670个SPEND事务,即SPEND的平均事务大小为3.06kB,MINT的平均事务大小为4.33kB。通常,Fabric中的事务很大,因为它们带有证书信息。此外,Fabcoin的MINT交易大于SPEND交易,因为它们带有CB证书。这是Fabric和Fabcoin未来改进的途径。
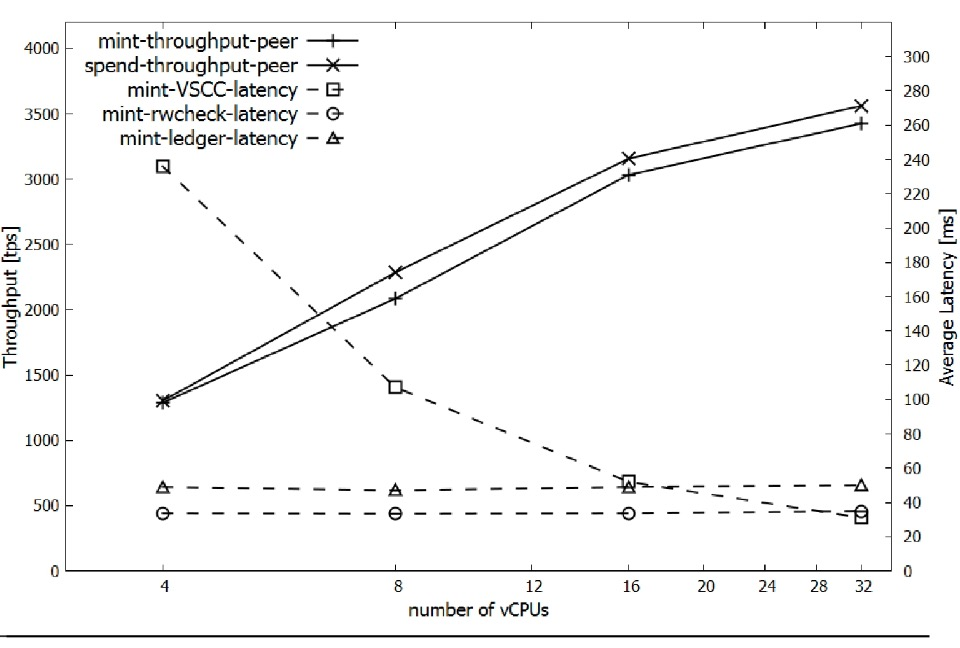
对等CPU的影响。 Fabric对等体运行许多CPU密集型加密操作。为了估计CPU对吞吐量的影响,我们进行了一系列实验,其中4个对等体在4个,8个,16个和32个vCPU VM上运行,同时还进行了块验证的粗粒度延迟分级以更好地识别瓶颈。我们的实验侧重于验证阶段,因为Kafka订购服务的订购从未成为我们实验的瓶颈。验证最后,在本实验中,我们测量了32-vCPU对等体上每秒3560个事务处理(tps)的平均SPEND吞吐量。一般来说,MINT吞吐量略低于SPEND,但差异仍在10%以内。
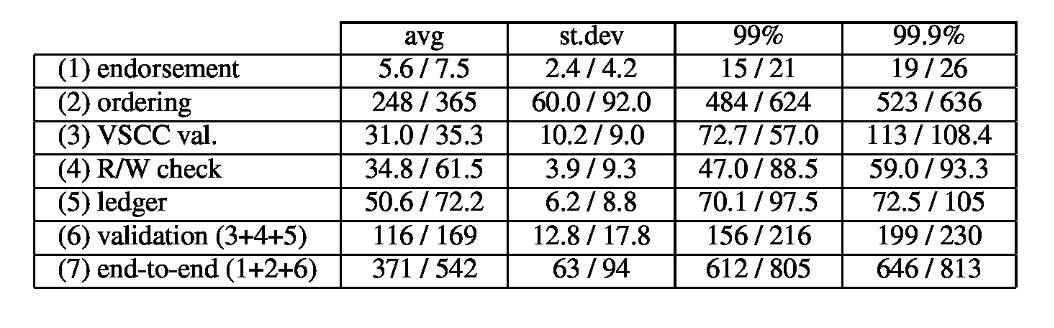
延迟分阶段进行。我们在上一次实验中进一步对报告的峰值吞吐量进行了粗粒度延迟分析。结果如表1所示。排序阶段包括在验证开始之前对等体内的广播传递延迟和内部延迟。该表报告了MINT和SPEND的平均延迟,标准偏差和尾部延迟(99%和99.9%)。
我们可以观察到排序主导了整体延迟。我们观察到平均潜伏期低于550毫秒,尾部潜伏期为亚秒级。特别是,我们实验中最高的端到端延迟来自负载建立期间的第一个块。通过利用订货人的时间切割参数(参见第3.3节)可以调节和减少低负荷下的延迟,我们在实验中基本上不使用该参数,因为我们将其设置为较大的值。
SSD与RAM磁盘。为了评估使用本地SSD进行稳定存储的开销,我们重复了之前的实验,将RAM磁盘(tmpfs)作为稳定存储安装在所有节点虚拟机。好处有限,因为tmpfs只能帮助同行验证的分类账阶段。我们在32vCPU同行测得的持续峰值吞吐量为3870 SPEND tps,比SSD大约高出9%。
表1. MINT和SPEND的延迟统计信息(以毫秒(ms)为单位),在具有2MB块的32-vCPU对等体上分为五个阶段。验证(6)包括第3,4和5阶段;端到端延迟包含1-5阶段。
6. 相关工作
Fabric的架构类似于Kemme和Alonso [24]开创的中间件复制数据库。但是,所有关于此的现有工作仅解决了崩溃失败,而不是对应于BFT系统的分布式信任的设置。例如,具有非对称更新处理的复制数据库[25,Sec。 6.3]依赖于一个节点来执行每个事务,这不适用于区块链。Fabric的执行顺序验证体系结构可以解释为对Byzantine模型的这项工作的概括,以及分布式分类账的实际应用。从BFT数据库复制的角度来看,Byzantium [17]和HRDB [35]是Fabric的另外两个前身。Byzantium允许事务并行运行并使用主动复制,但完全使用BFT中间件命令BEGIN和COMMIT / ROLLBACK。在乐观模式中,每个操作都由一个主副本协调;如果怀疑主设备是拜占庭,则所有副本都执行主设备的事务操作,并触发昂贵的协议来更改主设备。HRDB以更强大的方式依赖于正确的主人。与Fabric相比,两个系统都使用主动复制,无法处理灵活的信任模型,并且依赖于副本的确定性操作。但是,他们的数据库API比Fabric的KVS模型更丰富。
在Eve [21]中,在BFT模型中也探索了SMR的相关架构。它的对等体同时执行事务,然后使用共识协议验证它们是否都达到相同的输出状态。如果状态发散,则它们会回滚并按顺序执行操作。Eve包含独立执行的元素,它也存在于Fabric中,但不提供其他功能。
许可模型中的大量分布式分类帐平台最近问世,这使得无法与所有分布式分类帐进行比较(一些突出的是Tendermint [5],Quorum [19],Chain Core [12],Multichain <https:/ /www.multichain.com/>,Hyperledger Sawtoothsawtooth.hyperledger.org,Volt提案[32]等,请参阅最近的概述[9,16]中的参考文献。所有平台都遵循订单执行架构,如第2节所述。作为一个代表性的例子,采用Quorum平台[19],一个以企业为中心的以太坊版本。基于Raft [29]的共识,它使用八卦向所有同伴传播交易,并且Raft领导者(称为minter)将有效交易组装到一个区块,并使用Raft分配这个。所有对等方按照领导者决定的顺序执行交易。因此,它受到第1-2节中提到的限制。
参考
[1] P.-L. Aublin, R. Guerraoui, N. Knezevi ˇ c, V. Qu ´ ema, and M. Vukolic. The next 700 BFT protocols. ´ ACM Trans. Comput. Syst., 32(4):12:1–12:45, Jan. 2015.
[2] E. Ben-Sasson, A. Chiesa, C. Garman, M. Green, I. Miers, E. Tromer, and M. Virza. Zerocash: Decentralized anonymous payments from bitcoin. In IEEE Symposium on Security & Privacy, pages 459–474, 2014.
[3] A. N. Bessani, J. Sousa, and E. A. P. Alchieri. State machine replication for the masses with BFT-SMART. In International Conference on Dependable Systems and Networks (DSN), pages 355–362, 2014.
[4] G. Bracha and S. Toueg. Asynchronous consensus and broadcast protocols. J. ACM, 32(4):824–840, 1985.
[5] E. Buchman. Tendermint: Byzantine fault tolerance in the age of blockchains. M.Sc. Thesis, University of Guelph, Canada, June 2016.
[6] N. Budhiraja, K. Marzullo, F. B. Schneider, and S. Toueg. The primary-backup approach. In S. Mullender, editor, Distributed Systems (2nd Ed.), pages 199–216. ACM Press/AddisonWesley, 1993.
[7] C. Cachin, R. Guerraoui, and L. E. T. Rodrigues. Introduction to Reliable and Secure Distributed Programming (2. ed.). Springer, 2011.
[8] C. Cachin, S. Schubert, and M. Vukolic. Non-determinism ´ in byzantine fault-tolerant replication. In 20th International Conference on Principles of Distributed Systems (OPODIS), 2016.
[9] C. Cachin and M. Vukolic. Blockchain consensus protocols ´ in the wild. In A. W. Richa, editor, 31st Intl. Symposium on Distributed Computing (DISC 2017), pages 1:1–1:16, 2017.
[10] J. Camenisch and E. V. Herreweghen. Design and implementation of the idemix anonymous credential system. In ACM Conference on Computer and Communications Security (CCS), pages 21–30, 2002.
[11] M. Castro and B. Liskov. Practical Byzantine fault tolerance and proactive recovery. ACM Trans. Comput. Syst., 20(4):398–461, Nov. 2002.
[12] Chain. Chain protocol whitepaper. chain.com/ docs/1.2/protocol/papers/whitepaper, 2017.
[13] B. Charron-Bost, F. Pedone, and A. Schiper, editors. Replication: Theory and Practice, volume 5959 of Lecture Notes in Computer Science. Springer, 2010.
[14] K. Croman, C. Decker, I. Eyal, A. E. Gencer, A. Juels, A. Kosba, A. Miller, P. Saxena, E. Shi, E. G. Sirer, et al. On scaling decentralized blockchains. In International Conference on Financial Cryptography and Data Security (FC), pages 106–125. Springer, 2016.
[15] A. Demers, D. Greene, C. Hauser, W. Irish, J. Larson, S. Shenker, H. Sturgis, D. Swinehart, and D. Terry. Epidemic algorithms for replicated database maintenance. In ACM Symposium on Principles of Distributed Computing (PODC , pages 1–12. ACM, 1987.
[16] T. T. A. Dinh, R. Liu, M. Zhang, G. Chen, B. C. Ooi, and J. Wang. Untangling blockchain: A data processing view of blockchain systems. e-print, arXiv:1708.05665 [cs.DB], 2017.
[17] R. Garcia, R. Rodrigues, and N. M. Preguic¸a. Efficient middleware for Byzantine fault tolerant database replication. In European Conference on Computer Systems (EuroSys), pages 107–122, 2011.
[18] R. Guerraoui, R. R. Levy, B. Pochon, and V. Quema. Through- ´ put optimal total order broadcast for cluster environments. ACM Trans. Comput. Syst., 28(2):5:1–5:32, 2010.
[19] J. P. Morgan. Quorum whitepaper. github.com/ jpmorganchase/quorum-docs, 2016.
[20] F. P. Junqueira, B. C. Reed, and M. Serafini. Zab: Highperformance broadcast for primary-backup systems. In International Conference on Dependable Systems & Networks (DSN), pages 245–256, 2011.
[21] M. Kapritsos, Y. Wang, V. Quema, A. Clement, L. Alvisi, ´ and M. Dahlin. All about Eve: Execute-verify replication for multi-core servers. In Symposium on Operating Systems Design and Implementation (OSDI), pages 237–250, 2012.
[22] R. Karp, C. Schindelhauer, S. Shenker, and B. Vocking. Randomized rumor spreading. In Symposium on Foundations of Computer Science (FOCS), pages 565–574. IEEE, 2000.
[23] B. Kemme. One-copy-serializability. In Encyclopedia of Database Systems, pages 1947–1948. Springer, 2009.
[24] B. Kemme and G. Alonso. A new approach to developing and implementing eager database replication protocols. ACM Transactions on Database Systems, 25(3):333–379, 2000.
[25] B. Kemme, R. Jimenez-Peris, and M. Pati ´ no-Mart ˜ ´ınez. Database Replication. Synthesis Lectures on Data Management. Morgan & Claypool Publishers, 2010.
[26] A. E. Kosba, A. Miller, E. Shi, Z. Wen, and C. Papamanthou. Hawk: The blockchain model of cryptography and privacypreserving smart contracts. In 37th IEEE Symposium on Security & Privacy, 2016.
[27] S. Liu, P. Viotti, C. Cachin, V. Quema, and M. Vukoli ´ c. XFT: ´ practical fault tolerance beyond crashes. In Symposium on Operating Systems Design and Implementation (OSDI), pages 485–500, 2016.
[28] S. Nakamoto. Bitcoin: A peer-to-peer electronic cash system. www.bitcoin.org/bitcoin.pdf, 2009.
[29] D. Ongaro and J. Ousterhout. In search of an understandable consensus algorithm. In USENIX Annual Technical Conference (ATC), pages 305–320, 2014.
[30] F. Pedone and A. Schiper. Handling message semantics with Generic Broadcast protocols. Distributed Computing, 15(2):97–107, 2002.
[31] F. B. Schneider. Implementing fault-tolerant services using the state machine approach: A tutorial. ACM Comput. Surv., 22(4):299–319, 1990.
[32] S. Setty, S. Basu, L. Zhou, M. L. Roberts, and R. Venkatesan. Enabling secure and resource-efficient blockchain networks with VOLT. Technical Report MSR-TR-2017-38, Microsoft Research, 2017.
[33] A. Singh, T. Das, P. Maniatis, P. Druschel, and T. Roscoe. BFT protocols under fire. In Symposium on Networked Systems Design & Implementation (NSDI), pages 189–204, 2008.
[34] J. Sousa, A. Bessani, and M. Vukolic. A Byzantine fault- ´ tolerant ordering service for the Hyperledger Fabric blockchain platform. Technical Report arXiv:1709.06921, CoRR, 2017.
[35] B. Vandiver, H. Balakrishnan, B. Liskov, and S. Madden. Tolerating Byzantine faults in transaction processing systems using commit barrier scheduling. In ACM Symposium on Operating Systems Principles (SOSP), pages 59–72, 2007.
[36] M. Vukolic. The quest for scalable blockchain fabric: Proof- ´ of-work vs. BFT replication. In International Workshop on Open Problems in Network Security (iNetSec), pages 112– 125, 2015.
[37] J. Yin, J. Martin, A. Venkataramani, L. Alvisi, and M. Dahlin. Separating agreement from execution for Byzantine fault tolerant services. In ACM Symposium on Operating Systems Principles (SOSP), pages 253–267, 2003.
本文翻译自:arxiv.org/pdf/1801.10… 版权归作者所有,商业使用请联系作者

